spark-submit提交任务时执行流程(简单版)
1. yarn cluster模式提交spark任务
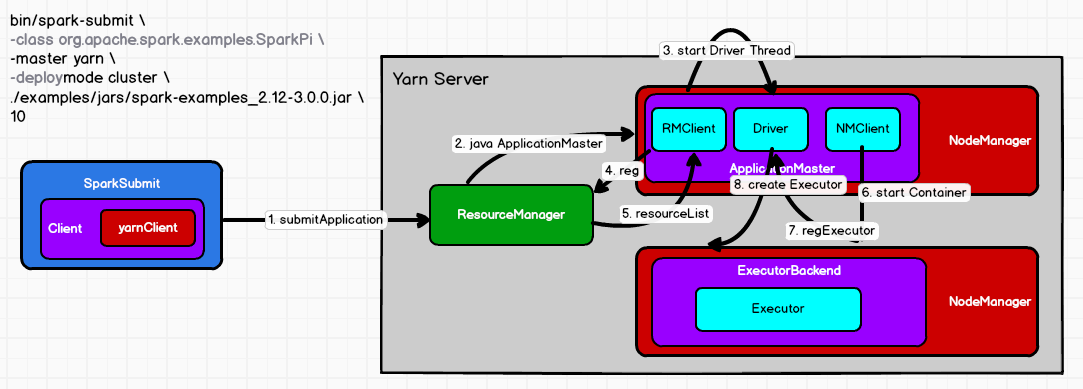
(1)执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程。
(2)SparkSubmit类中的main方法反射调用YarnClusterApplication的start方法【在spark3.4.3中是start方法】。
(3)YarnClusterApplication创建Yarn客户端,然后向yarn服务器发送执行指令:bin/java ApplicationMaster。
(4)Yarn(Resource Manager)收到指令后会在指定的NodeManager中启动Spark的ApplicationMaster。
(5)ApplicationMaster启动Driver线程,执行用户的作业。
(6)ApplicationMaster向ResourceManager注册,申请资源。
(7)ResourceManager启动NodeManager,NodeManager向ApplicationMaster注册。
(8)ApplicationMaster向NameNode发送指令,bin/java YarnCoarseGrainedExecutorBackend。启动Executor后端进程。
(9)CoarseGrainedExecutorExecutorBackend进程会和driver通信,启动计算对象Executor等待接收任务,注册已经启动的Executor。
(10)driver线程继续执行完成作业的调度和分配,自身任务的执行和监控任务的执行。
注:SparkSubmit是运行在提交命令的服务器,和ApplicationMaster和CoarseGrainedExecutorBackend是独立的进程。
Driver是运行在ApplicationMaster上的线程。Executor和YarnClusterApplication是对象。(有的资料说driver是进程,我还得再确认下!)
2. yarn client模式提交spark任务
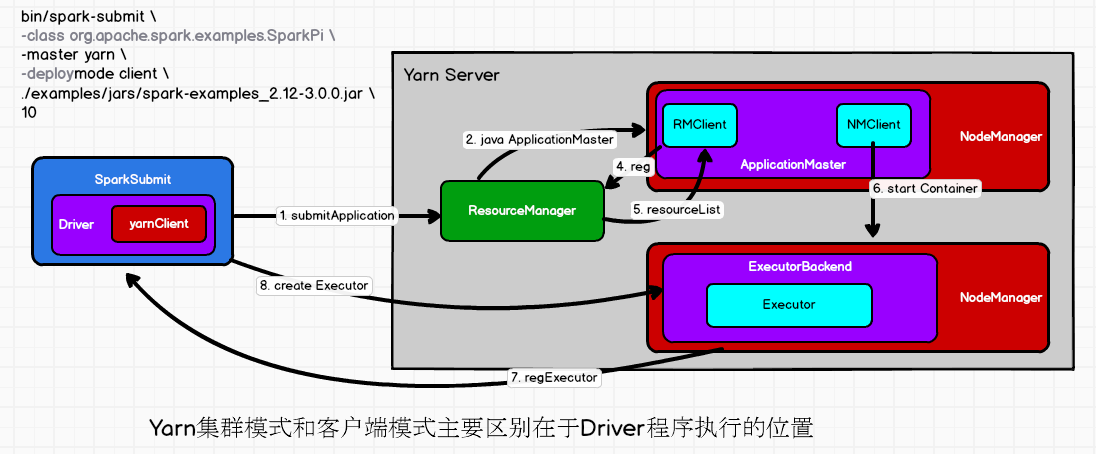
(有待进一步修正)
(1)执行脚本提交任务,实际是启用一个SparkSubmit的JVM进程。
(2)SparkSubmit类中的main方法反射调用用户diamagnetic的main方法。
(3)启动driver线程,执行用户的作业,并创建scheduleBackend。
(4)YarnClientScheduleBackend向RM发送指令,bin/java Executorlauncher。
(5)Yarn的RM收到指令后会在指定的NM中启动ExecutorLauncher(调用ApplicationMaster)
(6)ApplicationMaster向ResourceManager注册,申请用户作业所需的资源。
(7)获取资源后ApplicationMaster向NameNode发送指令,bin/java CoarseGrainedExecutorBackend。
(8)CoarseGrainedExecutorBackend进程会接收消息,与Driver通信,注册已经启动的Executor,然后启动Executor等待接收计算任务。
(9)Driver分配任务,执行任务,并监控任务的执行。
这里感觉还是描述不清楚,再修改。
参考:尚硅谷《Spark内核文档》。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号