Scarpy保存数据到json文件
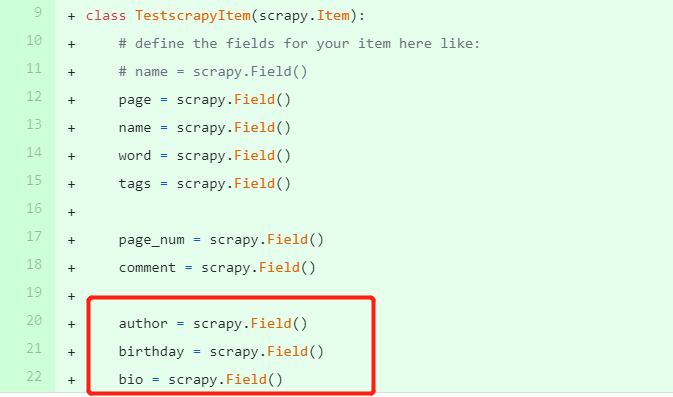
在items.py中设置需要保存的属性
import scrapy
class TestscrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
page = scrapy.Field()
name = scrapy.Field()
word = scrapy.Field()
在爬虫文件实例Item对象
item = TestscrapyItem(page=self.page_num, name=people, word=word)
yield item
注意item抛回的代码位置
- 以上次爬取的名人名言为例
import scrapy
from bs4 import BeautifulSoup
from testScrapy.items import TestscrapyItem
class MassageSpider(scrapy.Spider):
name = 'msg_crawl' # 爬虫的名字,一定要给
start_urls = ['http://quotes.toscrape.com/page/1/'] # 起始的url
page_num = 1
# 对爬到的网页进行解析
def parse(self, response, **kwargs):
soup = BeautifulSoup(response.body, 'html.parser')
nodes = soup.find_all('div', {'class': 'quote'})
for node in nodes:
word = node.find('span', {'class': 'text'}).text
people = node.find('small', {'class': 'author'}).text
item = TestscrapyItem(page=self.page_num, name=people, word=word)
yield item
# print('{0:<4}: {1:<20} said: {2:<20}'.format(self.page_num, people, word))
print('==================ok================')
self.page_num += 1
try:
url = soup.find('li', {'class': 'next'}).a['href']
if url is not None:
next_link = 'http://quotes.toscrape.com' + url
yield scrapy.Request(next_link, callback=self.parse)
except Exception:
print('所有页面爬取结束!')
- 每次获取到一页的数据就存回,所以放在for里面
输入指令
scrapy crawl <爬虫名字> -o <json文件名> -t json
或者
scrapy crawl <爬虫名字> -o <json文件名> -a tag=humor
-
eg:
scrapy crawl msg_crawl -o res.json -t jsonscrapy crawl msg_crawl -o res.json -a tag=humor -
对比发现,用第二种不会出现警告,但是两种都是可以保存的
-
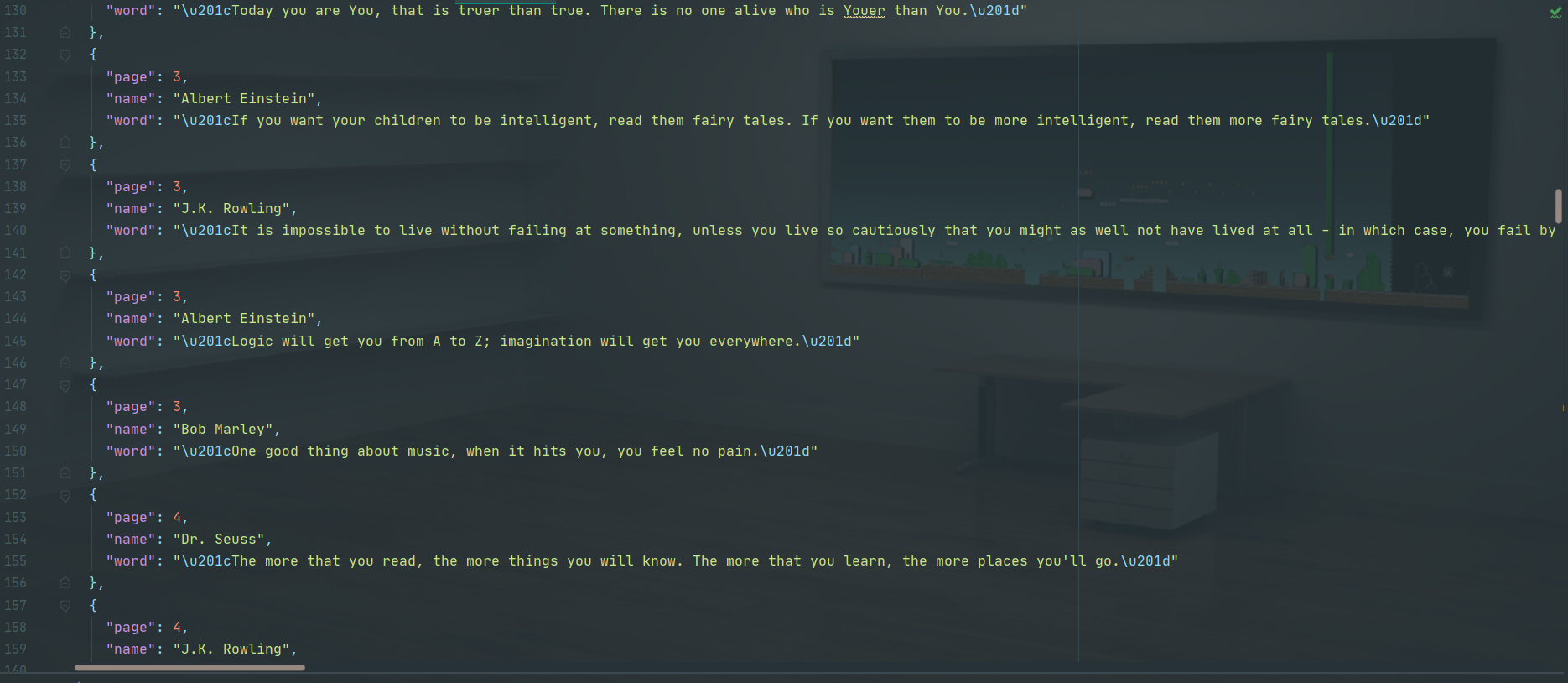
结果如下
补充
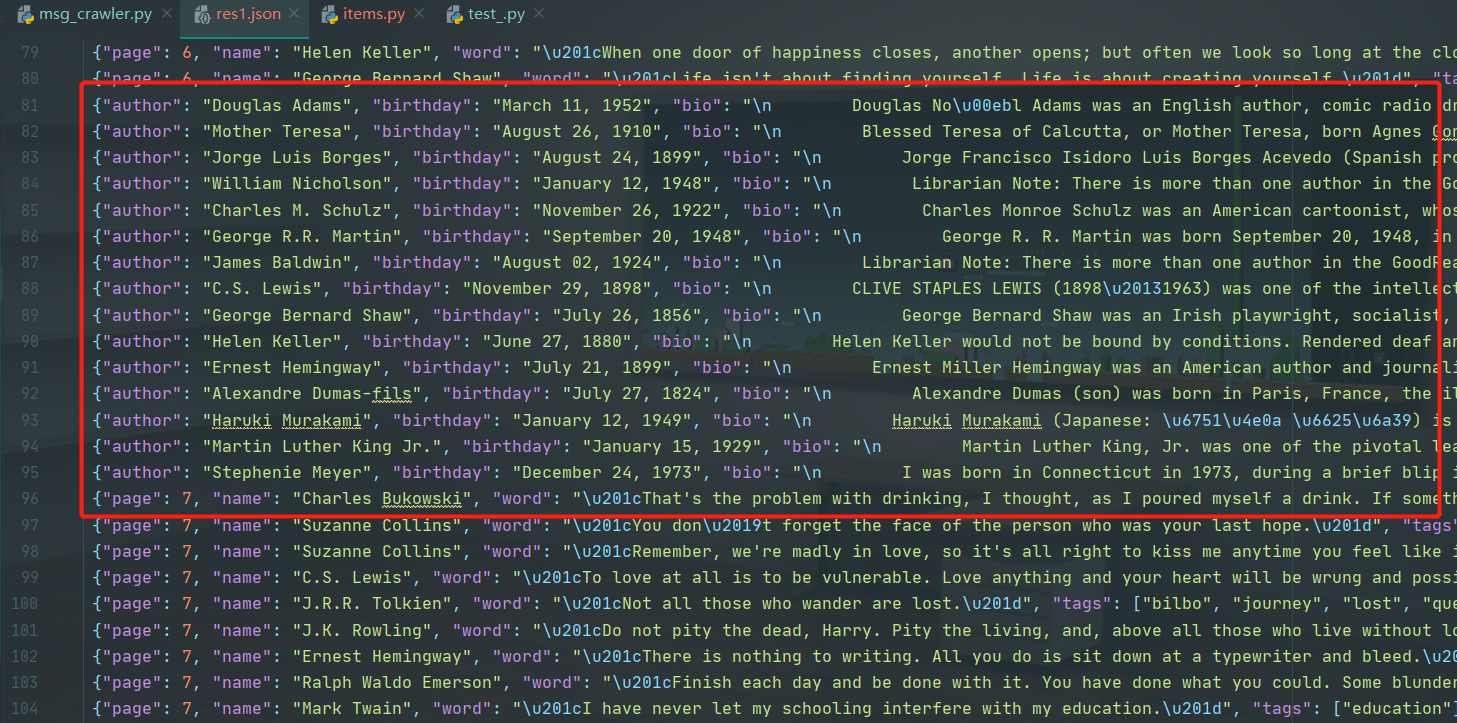
- 如果还要爬取每个页面的作者的链接,要用
yield response.follow(author_link, self.author_parse)
# 现在找到作者链接后,进去爬里面的数据信息
author_link = 'http://quotes.toscrape.com/' + node.find_all('span')[1].a['href']
yield response.follow(author_link, self.author_parse)
- 然后要保存成json时,和上面一样用item封装起来
- 具体见我github

 浙公网安备 33010602011771号
浙公网安备 33010602011771号