Scrapy的基本使用
创建一个scrapy项目
- 在终端输入:
scrapy startproject <项目名>
- 接下可以用pycharm打开
写爬虫代码
- 在文件夹spiders里面写自己的爬虫代码
import scrapy
class MassageSpider(scrapy.Spider):
name = 'msg_crawl' # 爬虫的名字,一定要给
start_urls = ['http://www.cae.cn/cae/html/main/col48/column_48_1.html'] # 起始的url
# 对爬到的网页进行解析
def parse(self, response, **kwargs):
print(response.url)
- response会自动去获取start_urls里面的url
- 启动爬虫:
scrapy crawl <爬虫的名字>
eg
scrapy crawl msg_crawl
记得切换到根目录

爬取中科院院士信息为例
"""
# @Time : 2020/8/27
# @Author : Jimou Chen
"""
import scrapy
from bs4 import BeautifulSoup
class MassageSpider(scrapy.Spider):
name = 'msg_crawl' # 爬虫的名字,一定要给
start_urls = ['http://www.cae.cn/cae/html/main/col48/column_48_1.html'] # 起始的url
# 对爬到的网页进行解析
def parse(self, response, **kwargs):
soup = BeautifulSoup(response.body, 'html.parser')
nodes = soup.find_all('li', {'class': 'name_list'})
i = 0
for node in nodes:
i += 1
people_name = node.find('a').text
link = 'http://www.cae.cn/' + node.find('a')['href']
print('{}. {}: {}'.format(i, people_name, link))
-
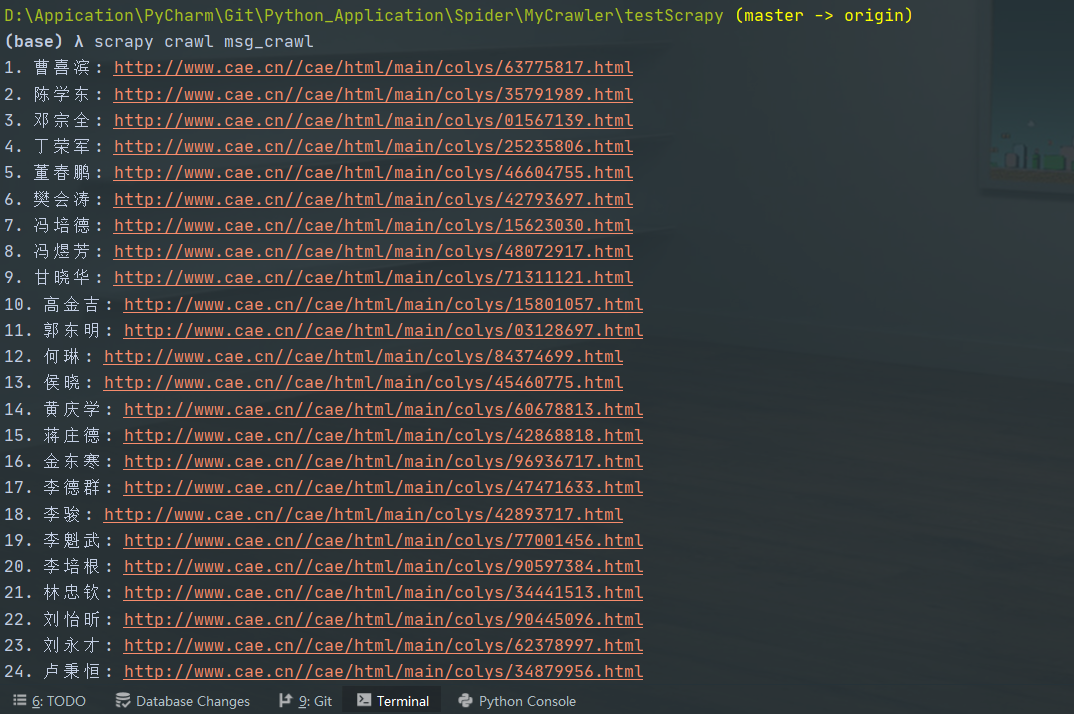
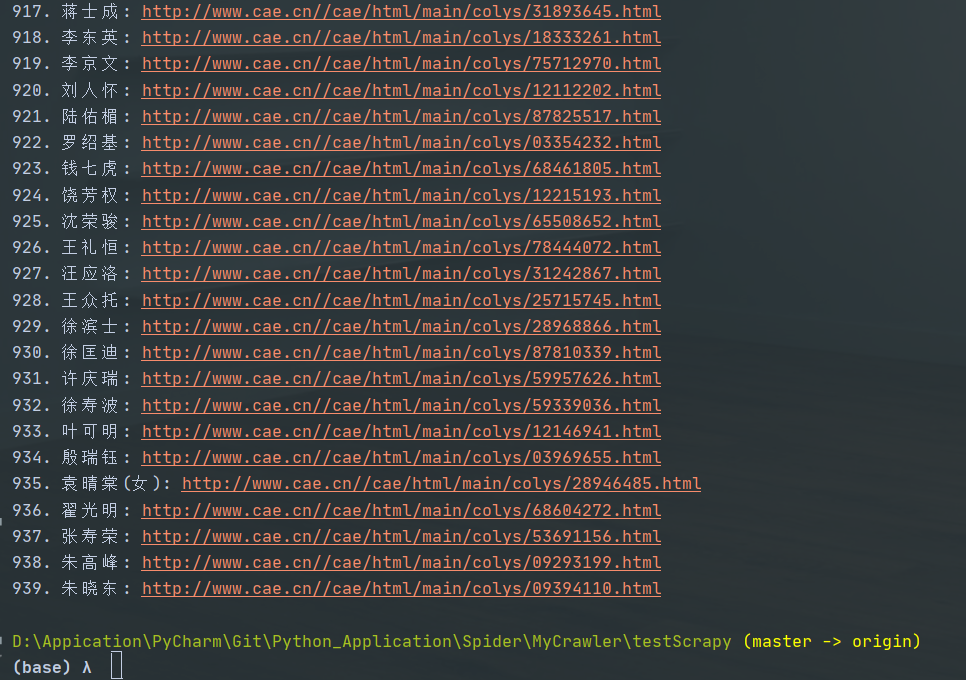
结果如下:
-
所以基本上处理网页就是在
def parse(self, response, **kwargs)这里了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号