贝叶斯分类
贝叶斯分类用途
-
和文本有关的分析分类用贝叶斯分类效果比较好
-
eg:
邮件:总体100,正常70,垃圾30。
“办证”在正常邮件中出现10次,在垃圾邮件中出现25次
假设X为“办证”,H为垃圾邮件
𝑃 (𝑋|𝐻) =25/30=5/6
𝑃(𝐻)=30/100=3/10
𝑃 (𝑋) =35/100=7/20
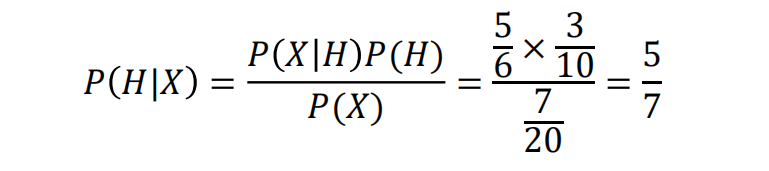
包含“办证”这个词的邮件属于垃圾邮件的概率为5/7
-
有:
- 多项式模型
- 伯努利模型
- 高斯模型
- 高斯模型用于连续型数据效果好
用sklearn实现贝叶斯
"""
# @Time : 2020/8/13
# @Author : Jimou Chen
"""
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.naive_bayes import MultinomialNB, BernoulliNB, GaussianNB # 导入朴素贝叶斯的三种模型
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target)
'''建立三种贝叶斯模型看看效果'''
# 建立多项式模型
mul = MultinomialNB()
mul.fit(x_train, y_train)
print(classification_report(mul.predict(x_test), y_test))
print(confusion_matrix(mul.predict(x_test), y_test))
# 建立伯努利模型
bernoulli = BernoulliNB()
bernoulli.fit(x_train, y_train)
print(classification_report(bernoulli.predict(x_test), y_test))
print(confusion_matrix(bernoulli.predict(x_test), y_test))
# 建立高斯模型
gaussian = GaussianNB()
gaussian.fit(x_train, y_train)
print(classification_report(gaussian.predict(x_test), y_test))
print(confusion_matrix(gaussian.predict(x_test), y_test))
D:\Anaconda\Anaconda3\python.exe D:/Appication/PyCharm/Git/MachineLearning/machine_learning/贝叶斯/iris_贝叶斯.py
precision recall f1-score support
0 1.00 1.00 1.00 9
1 1.00 0.39 0.56 28
2 0.06 1.00 0.11 1
accuracy 0.55 38
macro avg 0.69 0.80 0.56 38
weighted avg 0.98 0.55 0.66 38
[[ 9 0 0]
[ 0 11 17]
[ 0 0 1]]
precision recall f1-score support
0 1.00 0.24 0.38 38
1 0.00 0.00 0.00 0
2 0.00 0.00 0.00 0
accuracy 0.24 38
macro avg 0.33 0.08 0.13 38
weighted avg 1.00 0.24 0.38 38
[[ 9 11 18]
[ 0 0 0]
[ 0 0 0]]
precision recall f1-score support
0 1.00 1.00 1.00 9
1 1.00 0.85 0.92 13
2 0.89 1.00 0.94 16
accuracy 0.95 38
macro avg 0.96 0.95 0.95 38
weighted avg 0.95 0.95 0.95 38
[[ 9 0 0]
[ 0 11 2]
[ 0 0 16]]
D:\Anaconda\Anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1221: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
Process finished with exit code 0
- 多次运行后发现高斯模型的贝叶斯效果最好
词袋模型
'''词袋模型'''
from sklearn.feature_extraction.text import CountVectorizer
texts = ["dog cat fish", "dog cat cat", "fish bird", 'bird']
cv = CountVectorizer()
cv_fit = cv.fit_transform(texts)
print(cv.get_feature_names())
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0))
['bird', 'cat', 'dog', 'fish']
[[0 1 1 1]
[0 2 1 0]
[1 0 0 1]
[1 0 0 0]]
[2 3 2 2]
- 计数只对英文文本起作用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号