集成学习
集成学习
-
集成学习就是组合多个学习器,最后可以得到一个更
好的学习器。
-
集成学习算法:
-
个体学习器之间不存在强依赖关系,装袋(bagging)
-
随机森林(Random Forest)
-
个体学习器之间存在强依赖关系,提升(boosting)
-
Stacking
-
bagging
- 一种有放回的抽样
"""
# @Time : 2020/8/12
# @Author : Jimou Chen
"""
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
from sklearn import tree
from sklearn.ensemble import BaggingClassifier # bagging分类器
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
'''一般来说集成学习用于复杂的较好,下面是简单例子'''
# 定义一个画出两个特征的分布图,二维
def draw(model):
# 获取数值所在范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()])
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
iris = datasets.load_iris()
x_data = iris.data[:, :2] # 为了比对用了集成学习和不用集成学习的效果,只用两个特征
y_data = iris.target
# 切分数据
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data)
'''建kNN模型'''
kNN = KNeighborsClassifier()
kNN.fit(x_train, y_train)
# 画图
draw(kNN)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
# 准确率
print(kNN.score(x_test, y_test))
'''建决策树模型'''
tree = tree.DecisionTreeClassifier()
tree.fit(x_train, y_train)
# 画图
draw(tree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
# 准确率
print(tree.score(x_test, y_test))
'''接下来使用bagging集成学习,加入kNN'''
# 100个不放回的抽样,也就是训练100个kNN分类器
bagging_kNN = BaggingClassifier(kNN, n_estimators=100)
bagging_kNN.fit(x_train, y_train)
# 画图
draw(bagging_kNN)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
# 准确率
print(bagging_kNN.score(x_test, y_test))
'''加入决策树的集成学习'''
bagging_tree = BaggingClassifier(tree, n_estimators=100)
bagging_tree.fit(x_train, y_train)
# 画图
draw(bagging_tree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
# 准确率
print(bagging_tree.score(x_test, y_test))
每次运行结果都不一样的
0.7368421052631579
0.7105263157894737
0.7631578947368421
0.7105263157894737
随机森林(RF)
-
RF = 决策树+Bagging+随机属性选择
-
RF算法流程
-
样本的随机:从样本集中用bagging的方式,随机选择n个样本。
-
特征的随机:从所有属性d中随机选择k个属性(k<d),然后从k个属性中选择最佳分割属性作为节点建立
CART决策树。
-
重复以上两个步骤m次,建立m棵CART决策树。
-
这m棵CART决策树形成随机森林,通过投票表决结果,决定数据属于哪一类。
-
-
一般来说,随机森林的效果要比决策树好,所以选随机森林
"""
# @Time : 2020/8/12
# @Author : Jimou Chen
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier # 导入随机森林模型
from sklearn import tree # 导入决策树模型,与随机森林模型做对比
# 定义一个画预测图
def draw(model):
# 获取数据值所在的范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()]) # ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 样本散点图
plt.scatter(x_test[:, 0], x_test[:, 1], c=y_test)
plt.show()
data = np.genfromtxt('LR-testSet2.txt', delimiter=',')
x_data = data[:, :-1]
y_data = data[:, -1]
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
# 切分数据
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.25)
# 建立决策树模型
tree = tree.DecisionTreeClassifier()
tree.fit(x_train, y_train)
draw(tree)
# 评估模型
print(tree.score(x_test, y_test))
# 建立随机森林模型
RF = RandomForestClassifier(n_estimators=100)
RF.fit(x_train, y_train)
draw(RF)
# 评估模型
print(RF.score(x_test, y_test))
0.7333333333333333
0.8666666666666667
-
图见程序运行结果
-
每次结果均不一样
AdaBoost算法
-
AdaBoost是英文“Adaptive Boosting”(自适应增强)的缩写
-
将学习器的重点放在“容易”出错的样本上。可以提升学习器的性能
-
换而言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
-
也就是把重点放在错误率高的样本,不断纠正
"""
# @Time : 2020/8/12
# @Author : Jimou Chen
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.ensemble import AdaBoostClassifier # 导入AdaBoost模型
from sklearn.datasets import make_gaussian_quantiles
from sklearn.metrics import classification_report
# 定义一个画出两个特征的分布图,二维,只适用于两个特征
def draw(model, x_data, y_data):
# 获取数值所在范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()])
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 样本散点图
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
# 生成2维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征
x1, y1 = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2)
# 生成2维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征均值都为3
x2, y2 = make_gaussian_quantiles(mean=(3, 3), n_samples=500, n_features=2, n_classes=2)
# 将两组数据合成一组数据, 也就是得到1000个样本
x_data = np.concatenate((x1, x2))
y_data = np.concatenate((y1, - y2 + 1))
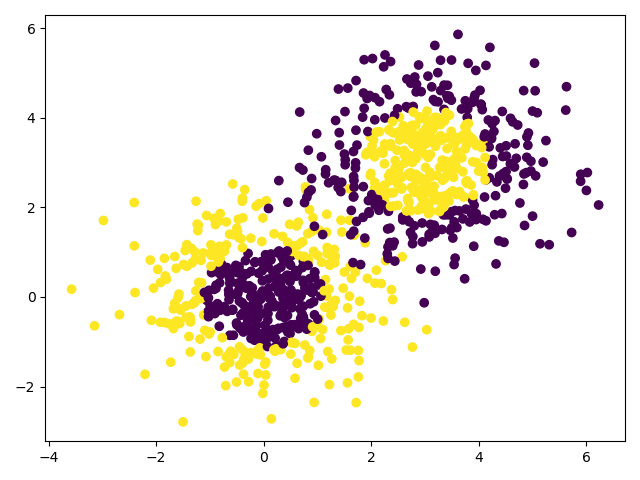
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
'''使用决策树看看结果'''
d_tree = tree.DecisionTreeClassifier(max_depth=3)
d_tree.fit(x_data, y_data)
# 画图预测
draw(d_tree, x_data, y_data)
print(d_tree.score(x_data, y_data))
'''使用AdaBoost模型,看看效果'''
AdaBoost = AdaBoostClassifier(d_tree, n_estimators=10)
AdaBoost.fit(x_data, y_data)
# 画图
draw(AdaBoost, x_data, y_data)
print(AdaBoost.score(x_data, y_data))
0.701
0.976
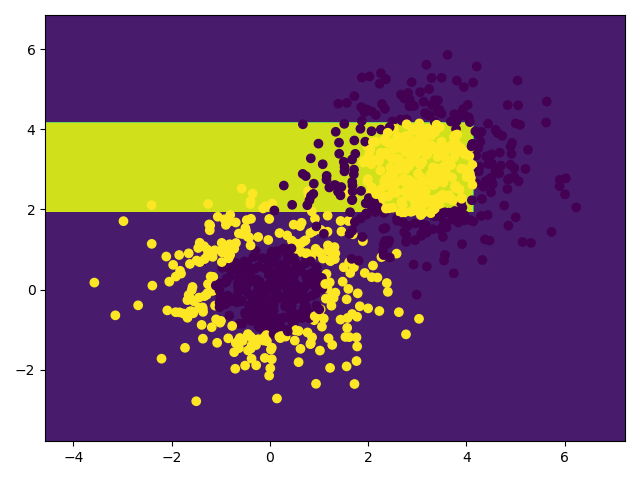
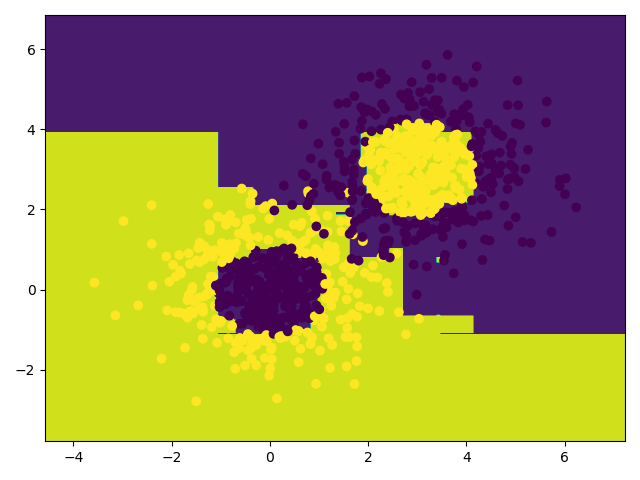
- 发现准确率高了很多
Stacking 算法
- 有初级和次级分类器
pip3 install mlxtend -i https://pypi.tuna.tsinghua.edu.cn/simple
"""
# @Time : 2020/8/12
# @Author : Jimou Chen
"""
from sklearn import datasets
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from mlxtend.classifier import StackingClassifier # 导入Stacking模型分类器
# 载入数据集
iris = datasets.load_iris()
# 只要第1,2列的特征
x_data, y_data = iris.data[:, 1:3], iris.target
# 定义三个不同的分类器
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = DecisionTreeClassifier()
clf3 = LogisticRegression()
# 定义一个次级分类器 meta_classifier, 传入的是逻辑回归模型
lr = LogisticRegression()
stacking_model = StackingClassifier(classifiers=[clf1, clf2, clf3], meta_classifier=lr)
for clf, label in zip([clf1, clf2, clf3, stacking_model],
['KNN', 'Decision Tree', 'LogisticRegression', 'StackingClassifier']):
# cross_val_score进行交叉验证, cv=3是分3份进行交叉验证,scoring='accuracy'计算准确率
scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3, scoring='accuracy')
# scores.mean()求三个交叉验证结果的平均值
print("Accuracy: %0.2f [%s]" % (scores.mean(), label))
Accuracy: 0.91 [KNN]
Accuracy: 0.93 [Decision Tree]
Accuracy: 0.95 [LogisticRegression]
Accuracy: 0.93 [StackingClassifier]
Process finished with exit code 0
- 有时候效果会比单个分类器的好
Voting算法
- 和Stacking的建模过程类似
- 但是没有次级分类器
"""
# @Time : 2020/8/12
# @Author : Jimou Chen
"""
from sklearn import datasets
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier # 导入Voting
'''
voting的建模步骤和stacking的建模过程类似,但是没有次级分类器
'''
# 载入数据集
iris = datasets.load_iris()
# 只要第1,2列的特征
x_data, y_data = iris.data[:, 1:3], iris.target
# 定义三个不同的分类器
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = DecisionTreeClassifier()
clf3 = LogisticRegression()
# 建立模型,按照这个格式建立Voting模型,
# 每个元组的第一个是对分类器的描述
voting_model = VotingClassifier([('kNN', clf1), ('d_tree', clf2), ('lr', clf3)])
for clf, label in zip([clf1, clf2, clf3, voting_model],
['KNN', 'Decision Tree', 'LogisticRegression', 'VotingClassifier']):
scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3, scoring='accuracy')
print("Accuracy: %0.2f [%s]" % (scores.mean(), label))
Accuracy: 0.91 [KNN]
Accuracy: 0.91 [Decision Tree]
Accuracy: 0.95 [LogisticRegression]
Accuracy: 0.95 [VotingClassifier]
- 可以看到比单个分类器的效果好!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号