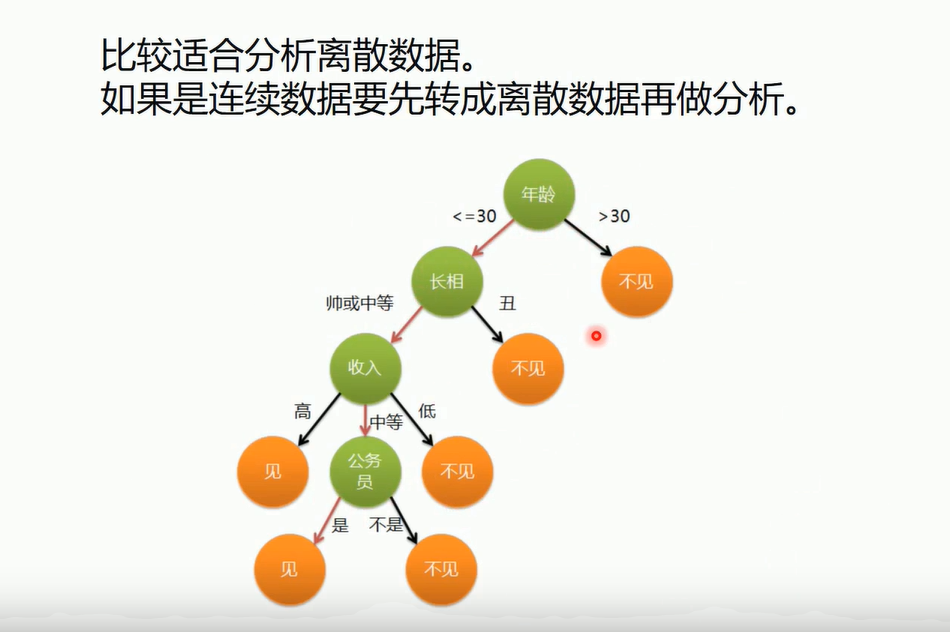
决策树
| RID |
age |
income |
student |
credit_rating |
class_buys_computer |
| 1 |
youth |
high |
no |
fair |
no |
| 2 |
youth |
high |
no |
excellent |
no |
| 3 |
middle_aged |
high |
no |
fair |
yes |
| 4 |
senior |
medium |
no |
fair |
yes |
| 5 |
senior |
low |
yes |
fair |
yes |
| 6 |
senior |
low |
yes |
excellent |
no |
| 7 |
middle_aged |
low |
yes |
excellent |
yes |
| 8 |
youth |
medium |
no |
fair |
no |
| 9 |
youth |
low |
yes |
fair |
yes |
| 10 |
senior |
medium |
yes |
fair |
yes |
| 11 |
youth |
medium |
yes |
excellent |
yes |
| 12 |
middle_aged |
medium |
no |
excellent |
yes |
| 13 |
middle_aged |
high |
yes |
fair |
yes |
| 14 |
senior |
medium |
no |
excellent |
no |
"""
# @Time : 2020/8/3
# @Author : Jimou Chen
"""
from sklearn.feature_extraction import DictVectorizer # 把字符数据转化成0和1
from sklearn import tree # 导入决策树
from sklearn import preprocessing
import csv
# 读入数据
f = open(r'AllElectronics.csv', 'r')
reader = csv.reader(f)
# 获取csv文件第一行数据,即特征
header = reader.__next__()
# print(header)
# 定义特征和标签列表
feature_list = []
label_list = []
# 获取1-6列有效数据
for row in reader:
# print(row)
# 把label存入list
label_list.append(row[-1])
row_dict = {}
# 第0列数据是序号,没有用的,所以不要,最后一列也不取
for i in range(1, len(row) - 1):
row_dict[header[i]] = row[i]
# 得到有效的特征数据
feature_list.append(row_dict)
print('feature_list :\n', feature_list)
# 把数据转化成01,先实例化一个对象
vec = DictVectorizer()
x_data = vec.fit_transform(feature_list).toarray()
print('x_data : \n', x_data)
# 打印特征名称
print(vec.get_feature_names())
# 打印标签列表
print(label_list)
# 把标签也转换为01
label = preprocessing.LabelBinarizer()
y_data = label.fit_transform(label_list)
print('y_data : \n', y_data)
# 创建决策树模型,分类器是属性为entropy的分类器
tree_model = tree.DecisionTreeClassifier(criterion='entropy')
# 输入数据建立模型
tree_model.fit(x_data, y_data)
# 先拿个训练数据来测试一下
x_test = x_data[0]
print('x_test:', x_test)
# print(x_test.reshape(1, -1))
# reshape(1, -1)是把x_test从一维变成二维,predict里面要求传二维数据
prediction = tree_model.predict(x_test.reshape(1, -1))
print('预测结果是:', prediction)
feature_list :
[{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'youth', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'medium', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}]
x_data :
[[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
y_data :
[[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
x_test: [0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
预测结果是: [0]
- reshape(1, -1)是把x_test从一维变成二维,predict里面要求传二维数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号