神经网络
神经网络
-
是深度学习的基础
-
深度学习计算是用GPU算的,比如英伟达

-
模型收敛条件,即模型训练结束条件
-
误差 (如代价函数值loss)小于某个预先设定的较小的值
-
两次迭代之间的权值变化已经很小
-
设定最大迭代次数,当迭代超过最大次数就停止(用的最多的)
-
单层感知器
-
最基础的
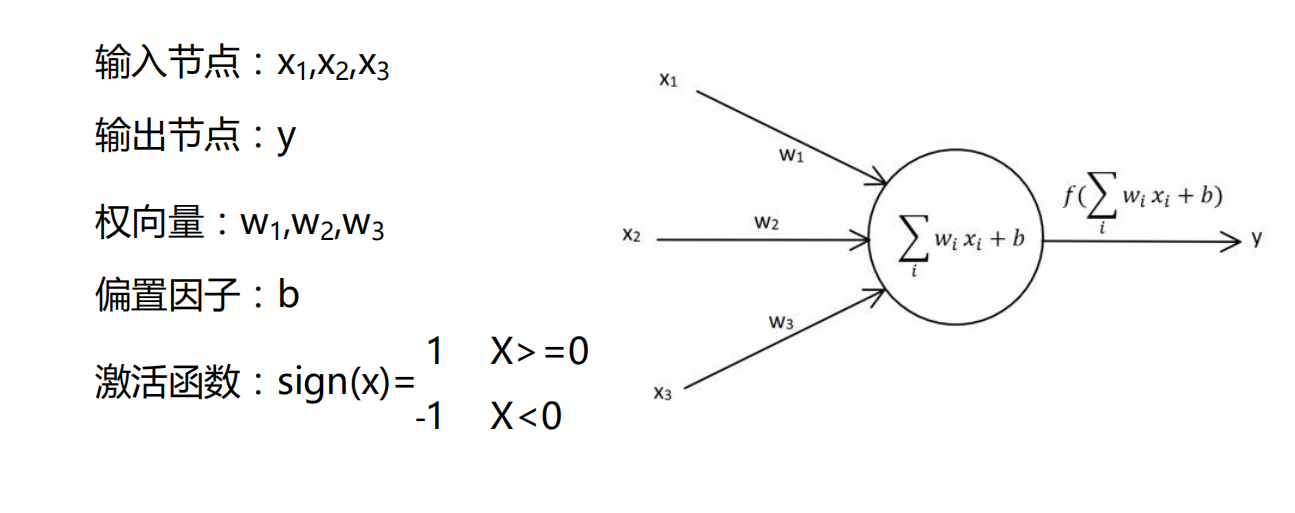
-
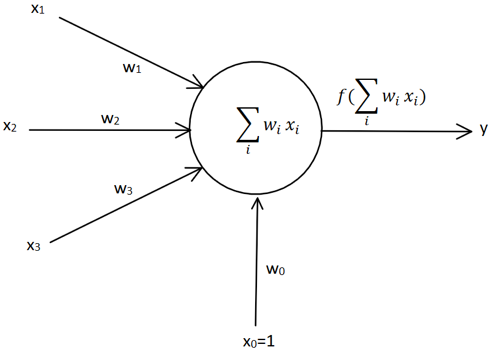
为了矩阵计算时方便一些,将偏置因子b看成是x0*w0
-
感知器学习规则

eg:
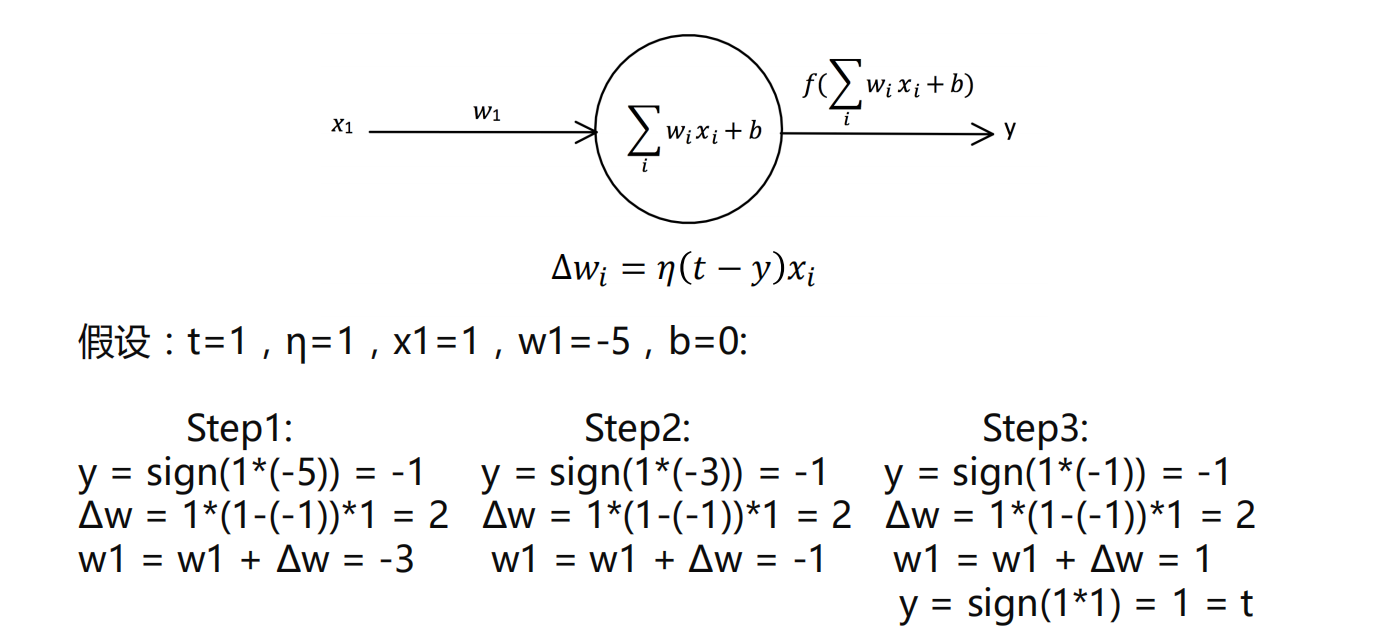
- 步骤就是不断迭代,最后如果y等于正确的标签t,那模型建立就结束
-
学习率
-
𝜂取值一般取0-1之间
-
学习率太大容易造成权值调整不稳定
-
学习率太小,权值调整太慢,迭代次数太多
-
代码注意:
-
一般把输入数据和标签设置成2维的形式
-
输入m个,输出n个,就把权值设为m行n列(这是随机取权值的情况)
-
X是个矩阵,X.T则是X的转置矩阵
-
X,Y是两个矩阵,他们相乘可以写成X.dot(Y),或者numpy.dot(X, Y)
-
np.sign 是自带的激活函数 -
eg:
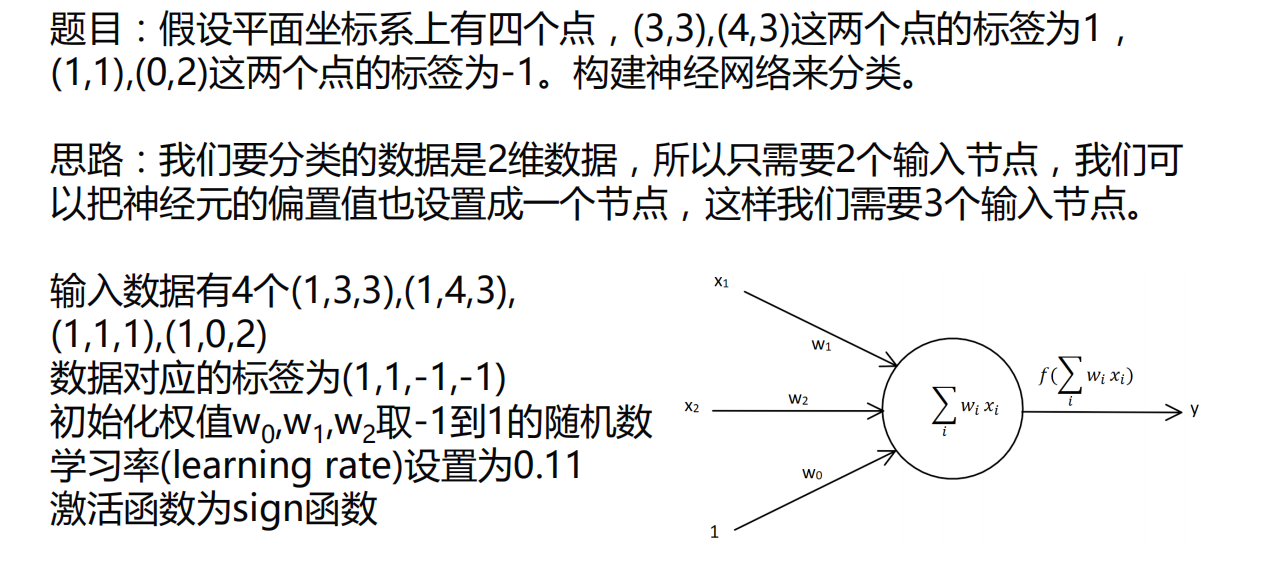
"""
# @Time : 2020/8/7
# @Author : Jimou Chen
"""
import numpy as np
import matplotlib.pyplot as plt
# 输入数据
X = np.array([[1, 3, 3],
[1, 4, 3],
[1, 1, 1],
[1, 0, 2]])
# 标签
Y = np.array([[1],
[1],
[-1],
[-1]])
# 初始化权值,3行1列,取值-1到1
W = (np.random.random([3, 1]) - 0.5) * 2
# 设置学习率
lr = 0.11
# 定义更新权值的函数
def update_weight():
global X, Y, W, lr
out = np.sign(np.dot(X, W)) # 神经网络输出,直接得到4个预测值
theta_w = lr * (X.T.dot(Y - out)) / int(X.shape[0]) # 数据量大时取平均
W = W + theta_w
for i in range(100):
update_weight()
print('第{}次迭代:'.format(i))
print(W)
out = np.sign(np.dot(X, W)) # 计算当前输出
# .all()只有输出的所有预测值都与实际输出一样,才说明模型收敛,循环结束
if (out == Y).all():
print('Finished , epoch:', i)
break
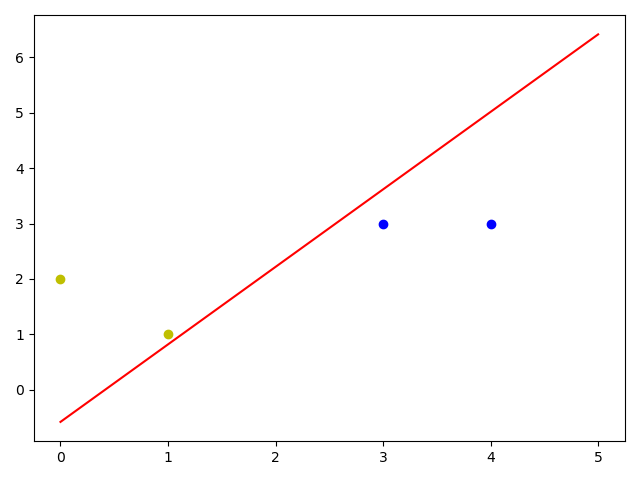
'''上面迭代到最后一次时,W就可以确定分界线的截距和效率了'''
# 计算分界线的斜率和截距
k = -W[1] / W[2]
b = -W[0] / W[2]
print('k = ', k)
print('b = ', b)
'''可以把图画出来'''
# 正样本
x1 = [3, 4]
y1 = [3, 3]
# 负样本
x2 = [1, 0]
y2 = [1, 2]
# 画图横坐标边界
x_range = (0, 5) # 或者x_range = [0, 5]
plt.figure()
plt.plot(x_range, x_range * k + b, 'r')
plt.scatter(x1, y1, c='b')
plt.scatter(x2, y2, c='y')
plt.show()
第0次迭代:
[[0.27110547]
[0.68355699]
[0.31271088]]
第1次迭代:
[[0.16110547]
[0.62855699]
[0.14771088]]
第2次迭代:
[[ 0.05110547]
[ 0.57355699]
[-0.01728912]]
第3次迭代:
[[-0.05889453]
[ 0.51855699]
[-0.18228912]]
第4次迭代:
[[-0.11389453]
[ 0.46355699]
[-0.23728912]]
第5次迭代:
[[-0.16889453]
[ 0.40855699]
[-0.29228912]]
Finished , epoch: 5
k = [1.39778378]
b = [-0.5778338]
Process finished with exit code 0
-
每次运行结果都不同,因为权值是随机设置的
-
单层感知器可以帮我们解决一些分类问题
-
缺点:
- 效果不是很好
- 不能解决非线性的问题,如异或问题
- 因为用的激活函数是sign,所以实际标签只能设1和-1
线性神经网络
-
线性神经网络在结构上与感知器非常相似,只是激活函数不同。
在模型训练时把原来的sign函数改成了purelin函数:y = x
-
也就是,把单层感知器的 out = np.sign(np.dot(X, W)) 改成 out = np.dot(X, W)即可
-
Delta学习规则,比单层感知器复杂
-
解决异或问题(分类)
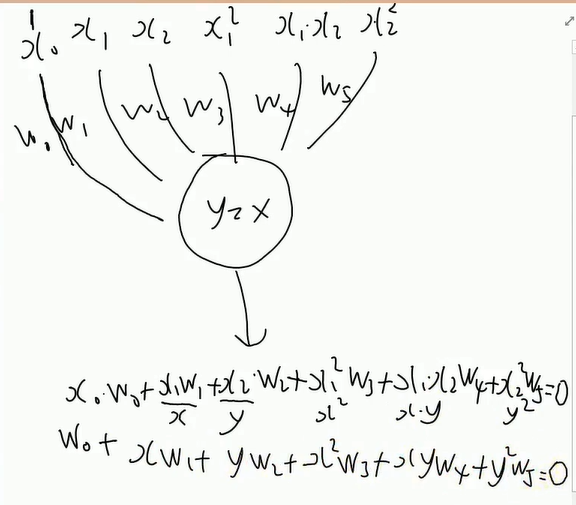
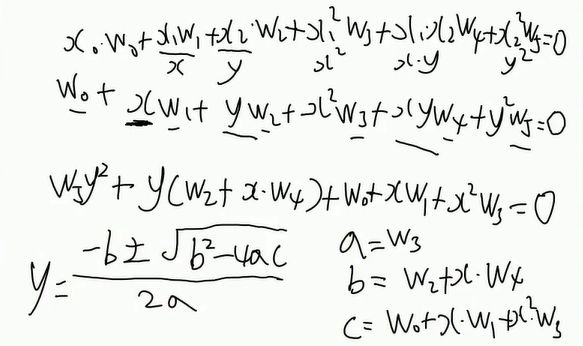
上面a算出来是 w5
"""
# @Time : 2020/8/8
# @Author : Jimou Chen
"""
import numpy as np
import matplotlib.pyplot as plt
'''x0,x1,x2,x1^2,x1x2,x2^2'''
# 输入数据
X = np.array([[1, 0, 0, 0, 0, 0],
[1, 1, 0, 1, 0, 0],
[1, 0, 1, 0, 0, 1],
[1, 1, 1, 1, 1, 1]])
# 标签
Y = np.array([-1, 1, 1, -1])
# 初始化权值,有6个权值
W = (np.random.random(6) - 0.5) * 2
# 设置学习率
lr = 0.11
# 定义更新权值的函数
def update_weight():
global X, Y, W, lr
out = np.dot(X, W.T) # 计算当前输出 # 神经网络输出,直接得到4个预测值
theta_w = lr * ((Y - out.T).dot(X)) / int(X.shape[0]) # 数据量大时取平均
W = W + theta_w
# 定义计算预测结果的函数
def calculate(x, root_num):
global W
a = W[5]
b = W[2] + x * W[4]
c = W[0] + x * W[1] + x * x * W[3]
if root_num == 1:
return (-b + np.sqrt(b * b - 4 * a * c)) / (2 * a)
if root_num == 2:
return (-b - np.sqrt(b * b - 4 * a * c)) / (2 * a)
# 通过增加循环次数,使得分类效果越好
for i in range(10000):
update_weight()
'''上面迭代到最后一次时,W就可以确定分界线的截距和效率了'''
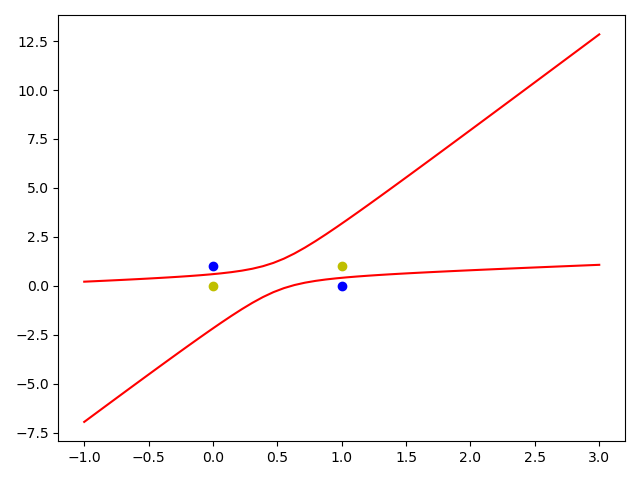
'''可以把图画出来'''
# 正样本
x1 = [0, 1]
y1 = [1, 0]
# 负样本
x2 = [1, 0]
y2 = [1, 0]
# 画图横坐标边界
x_range = np.linspace(-1, 3) # 或者x_range = [0, 5]
plt.figure()
plt.plot(x_range, calculate(x_range, 1), 'r')
plt.plot(x_range, calculate(x_range, 2), 'r')
plt.plot(x1, y1, 'bo')
plt.plot(x2, y2, 'yo')
plt.show()
# 看一下预测结果,迭代次数越多,预测结果越精确
out = np.dot(X, W.T)
print(out)
[-1. 1. 1. -1.] #迭代10000次
BP神经网络
- 公式推导部分参考教程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号