分类
分类算法
逻辑回归
-
垃圾邮件分类
-
预测肿瘤是良性还是恶性
-
预测某人的信用是否良好
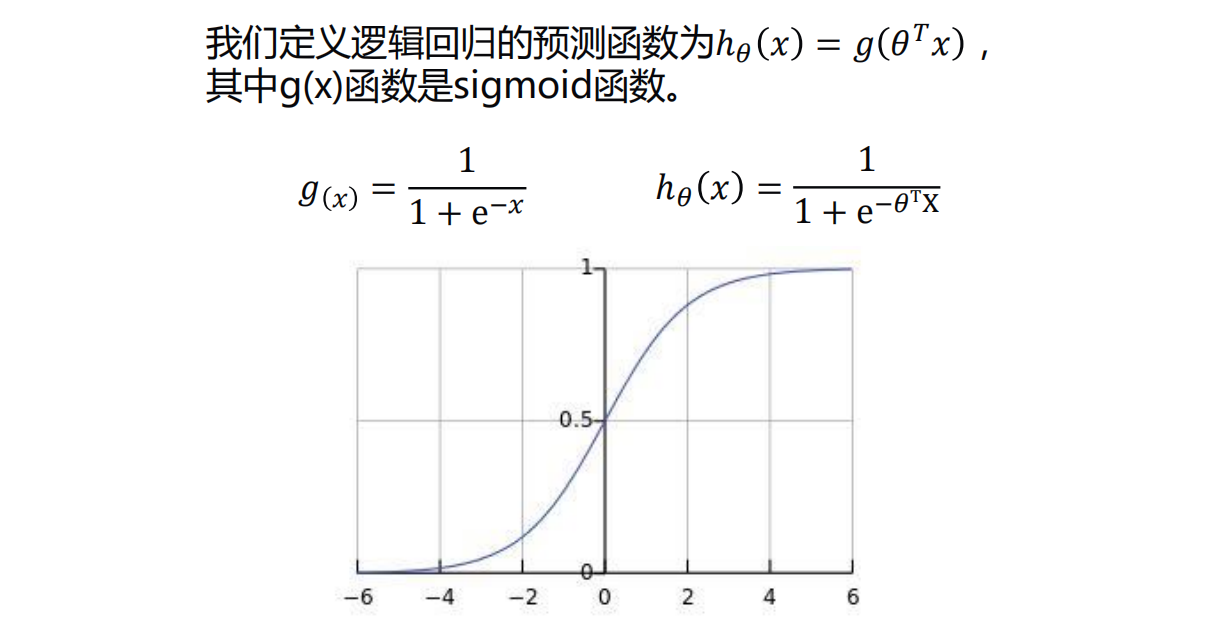
-
0.5是个分界,上面是g(x)图像
-
逻辑回归的代价函数
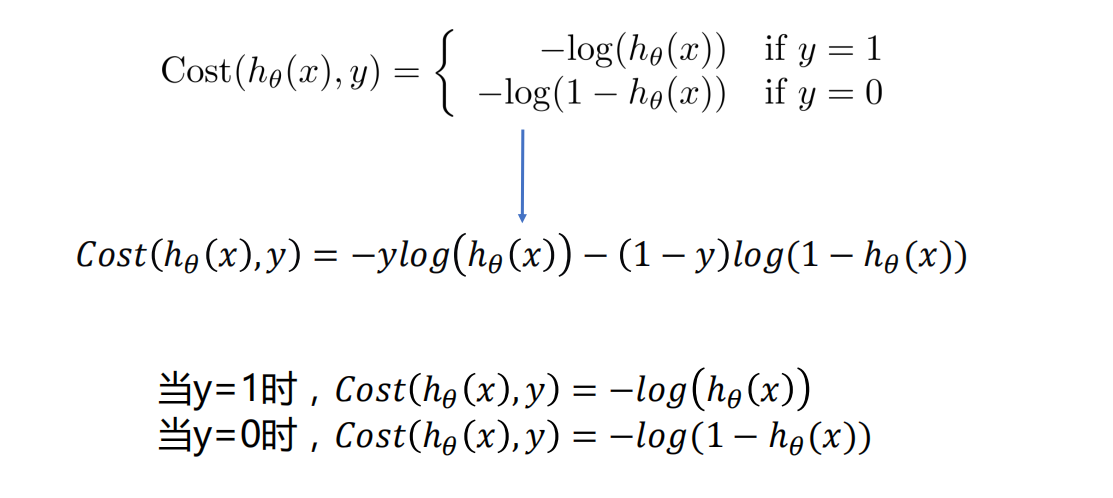
-
一般使用梯度下降法求解
评估分类的结果
- 正确率/召回率/F1指标
正确率就是检索出来的条目有多少是正确的
召回率就是 所有正确的条目有多少被检索出来了

-
这几个指标的取值都在0-1之间,数值越接近于1,效果越好
-
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。
撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标
分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
-
-
使用classification_report得到正确率/召回率/F1指标
-
eg
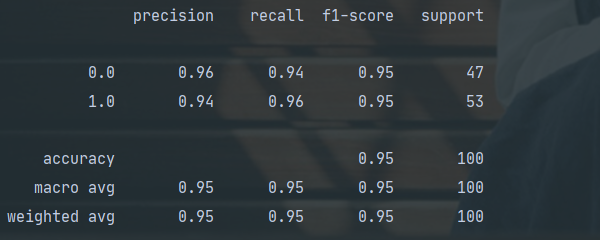
-
使用梯度下降法解决逻辑回归
"""
# @Time : 2020/8/6
# @Author : Jimou Chen
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
from sklearn import preprocessing
# False的话不做数据标准化
scale = False
# 逻辑回归预测函数
def sigmoid(x):
return 1.0 / (1 + np.exp(-x))
# 代价函数,传入训练数据,标签,权值,三者都是矩阵形式
def cost(x_mat, y_mat, ws):
left = np.multiply(y_mat, np.log(sigmoid(x_mat * ws)))
right = np.multiply(1 - y_mat, np.log(1 - sigmoid(x_mat * ws)))
return np.sum(left + right) / -(len(x_mat))
# 求梯度,用梯度改变权值
def gradAscent(xArr, yArr):
if scale:
xArr = preprocessing.scale(xArr)
xMat = np.mat(xArr)
yMat = np.mat(yArr)
lr = 0.001
epochs = 10000
costList = []
# 计算数据行列数
# 行代表数据个数,列代表权值个数
m, n = np.shape(xMat)
# 初始化权值
ws = np.mat(np.ones((n, 1)))
for i in range(epochs + 1):
# xMat和weights矩阵相乘
h = sigmoid(xMat * ws)
# 计算误差
ws_grad = xMat.T * (h - yMat) / m
ws = ws - lr * ws_grad
if i % 50 == 0:
costList.append(cost(xMat, yMat, ws))
return ws, costList
data = np.genfromtxt('LR-testSet.csv', delimiter=',')
x_data = data[:, :-1]
y_data = data[:, -1]
# 切分数据,并画出散点图
def split_plot():
# 切分成两种类别,0和1
# x0和y0是0类别的那两列数据,x1,y1同理
x0 = []
y0 = []
x1 = []
y1 = []
for i in range(len(x_data)):
if y_data[i] == 0:
x0.append(x_data[i, 0])
y0.append(x_data[i, 1])
else:
x1.append(x_data[i, 0])
y1.append(x_data[i, 1])
# 画出散点图
scatter0 = plt.scatter(x0, y0, c='b', marker='o')
scatter1 = plt.scatter(x1, y1, c='r', marker='x')
# 画图例
plt.legend(handles=[scatter0, scatter1], labels=['label0', 'label1'], loc='best')
# 切分数据,并画出散点图
split_plot()
plt.show()
# 把y_data变成二维
y_data = y_data[:, np.newaxis]
# 给样本提价偏置项
X_data = np.concatenate((np.ones((100, 1)), x_data), axis=1)
# 训练模型,得到权值和cost值的变化
ws, costList = gradAscent(X_data, y_data)
print(ws)
# 不做数据标准化时,才画出这个图
if not scale:
# 画图决策边界
split_plot()
x_test = [[-4], [3]]
# 这里ws[0],ws[1],ws[2]满足ws[0]+ws[1]*x+ws[2]*y = 0
# 而这条线就是两个类别的分界线
y_test = (-ws[0] - x_test * ws[1]) / ws[2]
plt.plot(x_test, y_test, 'k')
plt.show()
# 画图 loss值的变化
x = np.linspace(0, 10000, 201)
plt.plot(x, costList, c='r')
plt.title('Train')
plt.xlabel('Epochs')
plt.ylabel('Cost')
plt.show()
# 预测
def predict(x_data, ws):
if scale == True:
x_data = preprocessing.scale(x_data)
xMat = np.mat(x_data)
ws = np.mat(ws)
return [1 if x >= 0.5 else 0 for x in sigmoid(xMat * ws)]
predictions = predict(X_data, ws)
print(classification_report(y_data, predictions))
sklearn解决逻辑回归
- 比较方便
"""
# @Time : 2020/8/6
# @Author : Jimou Chen
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
from sklearn.metrics import classification_report # 用来对模型的预测效果做评估
data = np.genfromtxt('LR-testSet.csv', delimiter=',')
x_data = data[:, :-1]
y_data = data[:, -1]
# 切分有效数据,可以画出散点图
def show_scatter():
x0 = []
x1 = []
y0 = []
y1 = []
for i in range(len(x_data)):
if y_data[i] == 0:
x0.append(x_data[i, 0])
y0.append(x_data[i, 1])
else:
x1.append(x_data[i, 0])
y1.append(x_data[i, 1])
# plt.plot(x0, y0, 'b.')
# plt.plot(x1, y1, 'rx')
# plt.show()
# 画出散点图
scatter0 = plt.scatter(x0, y0, c='b', marker='o')
scatter1 = plt.scatter(x1, y1, c='r', marker='x')
# 画图例
plt.legend(handles=[scatter0, scatter1], labels=['label0', 'label1'], loc='best')
# 先把散点图画出来看看
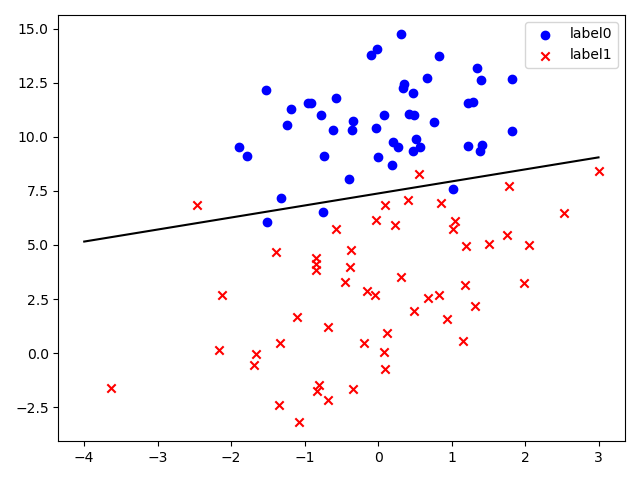
show_scatter()
plt.show()
# 建模,拟合
model = LogisticRegression()
model.fit(x_data, y_data)
# 画出决策边界,数据无标准化
show_scatter()
x_test = np.array([[-4], [3]])
y_test = (-model.intercept_ - x_test * model.coef_[0][0]) / model.coef_[0][1]
plt.plot(x_test, y_test, 'k')
plt.show()
# 如果要把这个模型拿来预测,可以这样做
prediction = model.predict(x_data)
print(prediction)
# 对预测模型进行评估
print(classification_report(y_data, prediction))

[0. 1. 1. 0. 0. 1. 0. 0. 0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1.
1. 0. 0. 1. 1. 0. 1. 0. 0. 1. 1. 0. 0. 0. 0. 0. 1. 1. 0. 1. 1. 0. 1. 1.
0. 0. 0. 0. 0. 0. 1. 1. 0. 1. 0. 1. 1. 1. 0. 0. 0. 1. 1. 0. 0. 0. 0. 1.
0. 1. 0. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 0. 1. 1. 1. 0. 0. 1. 1. 1.
0. 1. 0. 0.]
precision recall f1-score support
0.0 0.96 0.94 0.95 47
1.0 0.94 0.96 0.95 53
accuracy 0.95 100
macro avg 0.95 0.95 0.95 100
weighted avg 0.95 0.95 0.95 100
Process finished with exit code 0
-
由于上面的show_scatter是针对于只有两列特征的,如果是多列特征的话,还要继续切分,道理一样的
-
model.coef_里面包含了所有带x和y项的系数
-
model.intercept_是个常数
非线性逻辑回归
-
数据的扁平化:
-
eg:[[1, 2], [3, 4]]————>扁平化得到:[1, 2, 3, 4]
-
非线性逻辑回归可以用梯度下降法或者sklearn实现
-
sklearn:会更加方便些
sklearn非线性逻辑回归分类
-
有个更加方便的产生数据的方法:
- 样本的n_samples,n_features,n_classes可以自己设
- 相应地,画图时,x_data[:, 0], x_data[0:, 1]也相应的修改
from sklearn.datasets import make_gaussian_quantiles # 用于产生数据集 # 生成数据集,生成的是2维正态分布,可以自己设置类别 # 这里设为500个样本,2个样本特征,类别是2类,也可以设为多类 x_data, y_data = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2) # 可以画出来看看,分类传到颜色c plt.scatter(x_data[:, 0], x_data[0:, 1], c=y_data) plt.show() -
在使用model = LogisticRegression()和model.fit(x_poly, y_data)建模之前,要产生非线性特征:
-
# 定义多项式回归,用degree来调节多项式特征 poly_reg = PolynomialFeatures(degree=5) # 特征处理 x_poly = poly_reg.fit_transform(x_data)
-
-
模型评估可以使用model.score(x_poly, y_data),记住是传x_poly
"""
# @Time : 2020/8/7
# @Author : Jimou Chen
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_gaussian_quantiles # 用于产生数据集
from sklearn.preprocessing import PolynomialFeatures
# 生成数据集,生成的是2维正态分布,可以自己设置类别
# 这里设为500个样本,2个样本特征,类别是2类,也可以设为多类
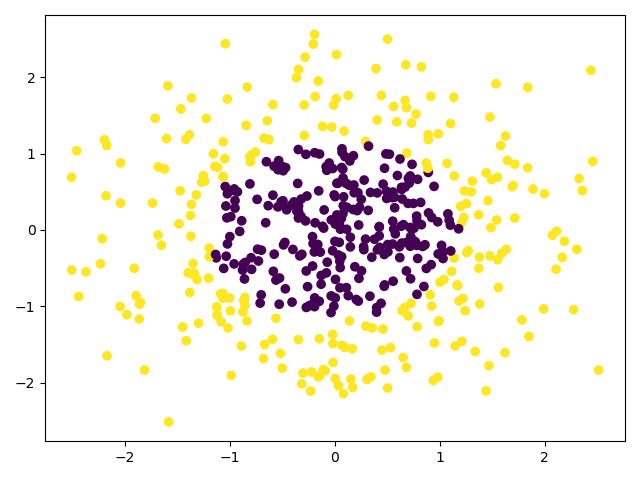
x_data, y_data = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2)
# 可以画出来看看,分类传到颜色c
plt.scatter(x_data[:, 0], x_data[0:, 1], c=y_data)
plt.show()
'''因为是非线性的,所以需要产生非线性特征'''
# 定义多项式回归,用degree来调节多项式特征
poly_reg = PolynomialFeatures(degree=5)
# 特征处理
x_poly = poly_reg.fit_transform(x_data)
# 建模拟合
model = LogisticRegression()
model.fit(x_poly, y_data)
# 评估
print('score: ', model.score(x_poly, y_data))
# 预测测试
print('原来的分类结果:\n', y_data)
print('预测第5行的结果是', model.predict(x_poly)[5])
print('所有的预测结果: \n', model.predict(x_poly))
'''上面已经建好模型了,可以直接去预测了,接下来是画图'''
# 获取数据值所在的范围,这里是确定图的边框范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵,即很多点构成的背景图,尽量密集些
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# 预测,ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = model.predict(poly_reg.fit_transform(np.c_[xx.ravel(), yy.ravel()]))
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 散点图
plt.scatter(x_data[:, 0], x_data[0:, 1], c=y_data)
plt.show()
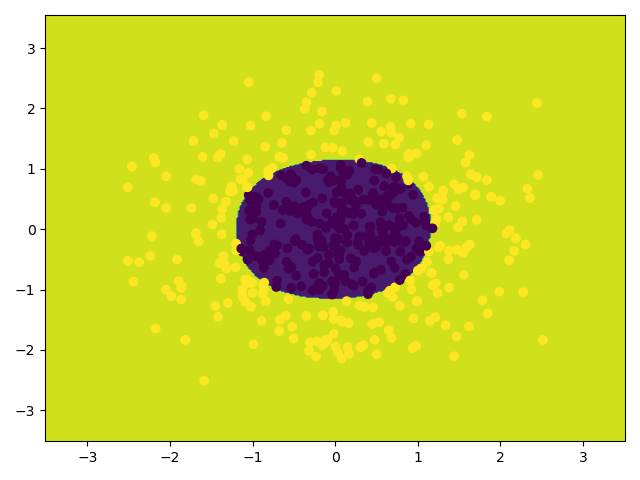
score: 0.988
原来的分类结果:
[1 0 0 1 0 1 0 1 0 0 0 0 1 1 1 0 0 1 0 0 0 0 0 0 0 1 0 1 1 0 0 0 0 1 1 0 1
0 1 1 1 1 1 1 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 1 1 0 1 1 1 1 1 1 0 1 0 1 0 0
1 1 1 0 0 1 0 1 1 1 1 0 0 1 0 1 0 0 1 0 1 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 1
0 0 0 0 0 1 0 0 1 0 1 1 0 0 0 1 1 1 1 1 1 1 0 0 1 0 1 1 0 1 1 1 1 0 0 0 0
0 1 1 0 0 0 1 0 1 0 0 0 0 0 1 1 1 0 1 0 0 0 1 0 0 0 0 0 1 1 1 0 0 0 0 1 0
1 0 1 1 1 1 0 1 1 1 0 1 0 1 1 0 0 1 0 1 0 0 0 1 1 0 0 1 1 1 1 0 1 1 0 0 1
1 1 0 1 0 1 1 1 0 0 1 1 1 0 1 1 1 0 0 0 0 1 1 1 1 1 0 1 0 1 0 0 0 0 0 1 0
0 0 1 0 1 1 1 1 1 1 0 1 0 0 1 0 0 1 0 1 0 1 1 1 0 0 1 0 0 1 0 1 1 1 0 1 1
1 0 0 0 1 1 0 0 1 0 0 0 0 1 1 0 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 1 1 1 1 0
1 1 0 0 0 0 0 1 1 1 1 1 0 0 0 1 1 0 1 0 0 1 0 1 1 1 0 0 1 0 0 0 1 0 0 1 1
1 1 1 1 0 1 0 1 1 0 0 1 1 0 0 1 0 1 0 1 1 1 1 0 0 0 1 1 1 1 0 0 1 1 0 1 0
0 1 1 0 0 0 0 1 0 1 0 0 0 1 0 1 1 0 1 0 0 1 1 0 0 1 1 1 1 0 0 1 0 1 1 1 0
0 1 0 0 1 0 0 0 1 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 0 1 0 0 0 1 1 0 1 1 1 1
1 0 1 1 0 1 1 0 0 0 0 1 0 0 0 0 0 0 0]
预测第5行的结果是 1
所有的预测结果:
[1 0 0 1 0 1 0 1 0 0 0 0 1 1 1 0 0 1 0 0 0 0 0 0 0 1 0 1 1 0 0 0 0 1 1 0 1
0 0 1 1 1 1 1 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 1 0 0 1 1 1 1 1 1 0 1 0 0 0 0
1 1 1 0 0 1 0 1 1 1 1 0 0 1 0 1 0 0 1 0 1 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 1
0 0 0 0 0 1 0 0 1 0 1 1 0 0 0 1 1 1 1 1 1 1 0 0 1 0 1 1 0 1 1 1 1 0 0 0 0
0 1 1 0 0 0 1 0 1 0 0 0 1 0 1 1 1 0 1 0 0 0 1 0 0 0 0 0 1 1 1 0 0 0 0 1 0
1 0 1 1 1 1 0 1 1 1 0 1 0 1 1 0 0 1 0 1 0 0 0 1 1 0 0 1 1 1 1 0 1 1 0 0 1
1 1 0 1 0 1 1 1 0 0 1 1 1 0 1 0 1 0 0 0 0 1 1 1 1 1 0 1 0 1 0 0 0 0 0 1 0
0 0 1 0 1 1 1 1 1 1 0 1 0 0 1 0 0 1 0 1 0 1 1 1 0 0 1 0 0 1 0 1 1 1 0 1 1
1 0 0 0 1 1 0 0 1 0 0 0 0 1 1 0 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 1 1 1 1 0
1 1 0 0 0 0 0 0 1 1 1 1 0 0 0 1 1 0 1 0 0 1 0 1 1 1 0 0 1 0 0 0 1 0 0 1 1
1 1 1 1 0 1 0 1 1 0 0 1 1 0 0 1 0 1 0 1 1 1 1 0 0 0 1 1 1 1 0 0 1 1 0 1 0
0 1 1 0 0 0 0 1 0 1 0 0 0 1 0 1 1 0 1 0 0 1 1 0 0 1 1 1 1 0 0 1 0 1 1 1 0
0 1 0 0 1 0 0 0 1 1 1 0 0 1 0 1 1 1 1 1 1 0 0 0 0 0 1 0 0 0 1 1 0 1 1 1 1
1 0 1 1 0 1 1 0 0 0 0 1 0 0 0 0 0 0 0]
Process finished with exit code 0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号