机器学习算法基础概览
 机器学习印象总览
机器学习印象总览
机器学习算法
基础部分
- 建模之前,我们可以把数据分为三个部分
训练集
验证集
测试集
- 训练集(train)用来训练,构建模型
- 验证集是用来在模型训练阶段测试模型好坏
- 等模型训练好后,再用测试集(test)来评估模型好坏
有时候,我们会偷懒直接分成训练集和测试集
监督学习
- 训练带有标签的数据集就是监督学习
如下

- 比如 3 和 dog就是标签,标签可以理解为类别
- 一般用来分类
无监督学习
- 不含有标签的数据集
- 一般用来聚类,因为没有标签(类别),所以需要聚类成一个类别
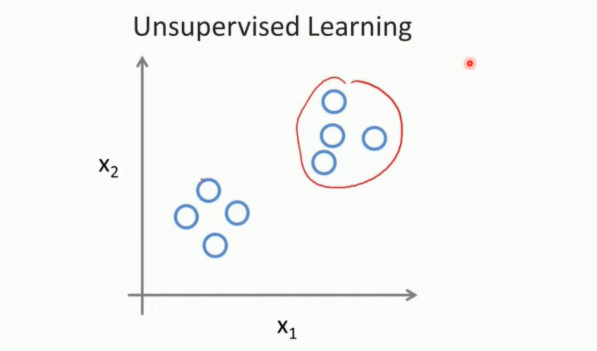
- 比如要为上面的圈圈分两个类别,即聚成两个类
半监督学习
- 用的比较少
- 介于监督学习和无监督学习之间
应用类别
回归
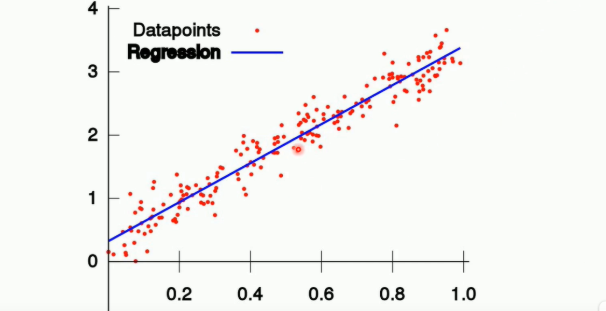
分类(带有标签的,一般属于监督学习)
- 垃圾邮箱分类
- 文本分类
- 图像识别(手写体识别)
聚类
- 无标签
下面是用聚类算法分成3个类别
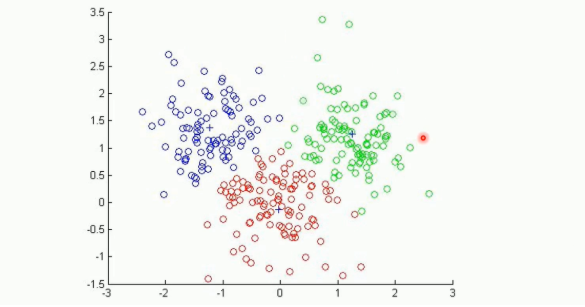
总结
- 回归:预测数据是连续型数值
- 分类:预测数据是类别型(离散)数值,并且类别已知
- 聚类:预测数据是类别型数值,并且类别未知

 浙公网安备 33010602011771号
浙公网安备 33010602011771号