SVM支持向量机基础
SVM
- 用于图像识别、人脸识别等复杂的分类情况
- 但是效果没有深度学习好,所以现在SVM的很多领域被深度学习取代了
"""
# @Time : 2020/8/21
# @Author : Jimou Chen
"""
from sklearn.svm import SVC # 导入svm的分类器SVC
# 二维的情况
x = [[3, 3], [4, 3], [1, 1]]
y = [1, 1, 0] # 分类标签,2个类
# 建模, 核函数为线性
model = SVC(kernel='linear')
model.fit(x, y)
# 打印支持向量
print('支持向量:\n', model.support_vectors_)
# 看看哪几个点是支持向量,打印出来是第2和第0个
print('第几个点是支持向量:\n', model.support_)
# 支持向量的分布情况,在分界线两端,这里打出来是各有1个
print('支持向量在分界线两端的分布情况\n', model.n_support_)
# 预测类别
print('预测坐标(%d, %d)的类别是:' % (-8, 3), model.predict([[-8, 3]]))
print('预测坐标(%d, %d)的类别是:' % (4, 3), model.predict([[4, 3]]))
# 看看系数和截距
print('系数:\n', model.coef_)
print('截距:\n', model.intercept_)
支持向量:
[[1. 1.]
[3. 3.]]
第几个点是支持向量:
[2 0]
支持向量在分界线两端的分布情况
[1 1]
预测坐标(-8, 3)的类别是: [0]
预测坐标(4, 3)的类别是: [1]
系数:
[[0.5 0.5]]
截距:
[-2.]
Process finished with exit code 0
svm处理非线性问题,低维映射到高维
- 如2维转3维,找到切平面,在投影到2维平面,可能是个圆或者椭圆的分界线
"""
# @Time : 2020/8/22
# @Author : Jimou Chen
"""
import matplotlib.pyplot as plt
from sklearn import datasets
'''用于解决非线性问题'''
# 制造数据
x_data, y_data = datasets.make_circles(n_samples=500, factor=0.3, noise=0.1)
# 画出来看看
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
'''接下来把2维映射到3维'''
z_data = x_data[:, 0] ** 2 + x_data[:, 1] ** 2
# 画3d图
ax = plt.figure().add_subplot(111, projection='3d')
ax.scatter(x_data[:, 0], x_data[:, 1], z_data, c=y_data, s=10) # s是大小
plt.show()
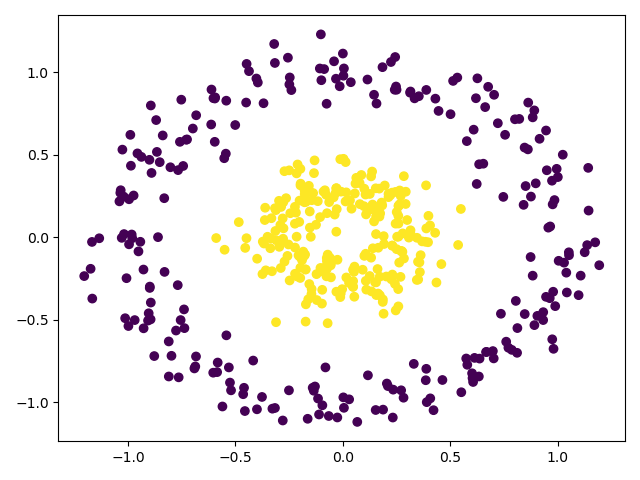
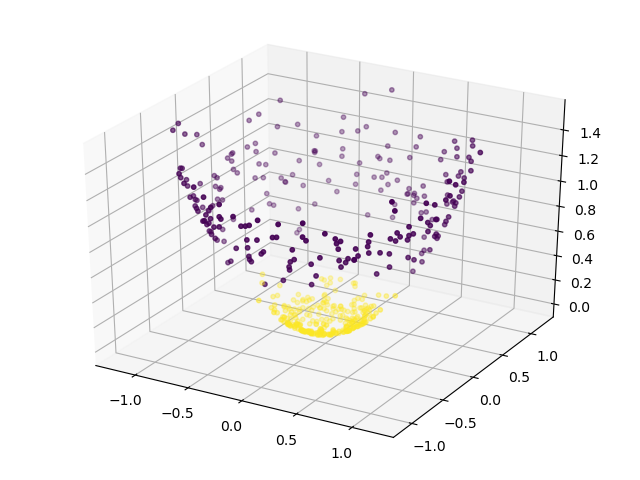
投影到二维平面
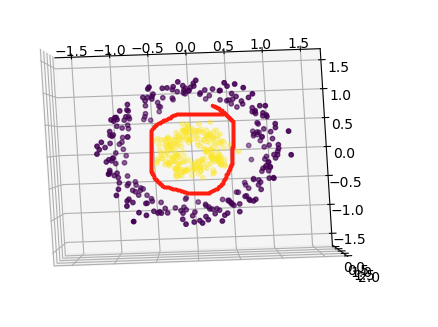
核函数

svm推导过程
- 推导过程理解起来较为复杂,见其他机器学习教材或者相关资料
svm处理多分类问题
- 一般svm是处理二值分类问题的,如果处理多个类别的,使用下面三种方法
model = svm.SVC(decision_function_shape='ovo')
model = svm.SVC(decision_function_shape='ovr')
model = svm.SVC(probability=True)
- 以下是先用pca降维后,再用svm进行分类的例子
"""
# @Time : 2020/8/30
# @Author : Jimou Chen
"""
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import svm
from sklearn.metrics import classification_report
data = pd.read_csv('data/wine.csv')
y_data = data.iloc[:, 0]
x_data = data.iloc[:, 1:]
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data)
pca = PCA(n_components=2)
new_data = pca.fit_transform(x_data)
# 画出来看一下
plt.scatter(new_data[:, 0], new_data[:, 1], c=y_data)
plt.show()
# 建模预测,多分类的三种方法,有时候会警告,不影响
# model = svm.SVC(decision_function_shape='ovo')
model = svm.SVC(decision_function_shape='ovr')
# model = svm.SVC(probability=True)
model.fit(x_train, y_train)
prediction = model.predict(x_data)
print(model.score(x_test, y_test))
print(classification_report(y_data, prediction))
# 画出预测的
plt.scatter(new_data[:, 0], new_data[0:, 1], c=prediction)
plt.show()
- 结果:
0.6888888888888889
precision recall f1-score support
1 0.89 0.85 0.87 59
2 0.70 0.72 0.71 71
3 0.49 0.50 0.49 48
accuracy 0.70 178
macro avg 0.69 0.69 0.69 178
weighted avg 0.71 0.70 0.70 178
Process finished with exit code 0
-
原始的
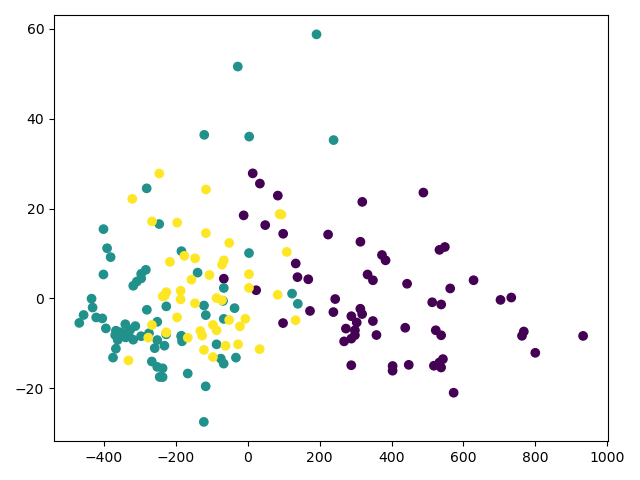
-
预测的
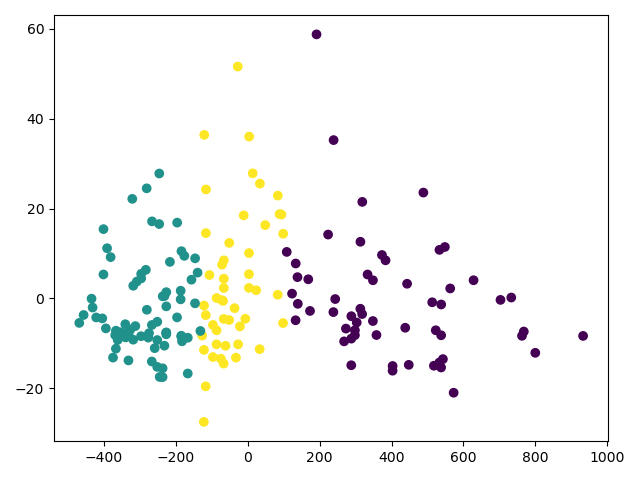
-
改进
上面这个题用随机森林的效果会更好,无论降到2/3/5维,预测效果几乎完美
model = RandomForestClassifier(n_estimators=100)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号