Hadoop3.1.4高可用环境搭建
规划部署节点
HDFS高可用至少有两个NameNode(NN),副本存三份有 三个DataNode(DN)。Yarn高可用至少有两个Resource Manager(RM),计算向存储移动需要在每个DataNode上部署NodeManager(NM)。Zookeeper(ZK)三节点选主。JournalNode(JN)三节点才有过半成功。基于以上考虑,规划部署节点如下:
| 主机 |
ip |
NN | RM | ZKFC | DN | NM | JN | ZK |
| master1 | 10.0.0.69 | √ | √ | √ | ||||
| master2 | 10.0.0.70 | √ | √ | √ | ||||
| slave1 | 10.0.0.71 | √ | √ | √ | √ | |||
| slave2 | 10.0.0.72 | √ | √ | √ | √ | |||
| slave3 | 10.0.0.73 | √ | √ | √ | √ |
注意:1.ZKFC与NameNode必须同节点才能选主。
2.DataNode与NodeManager必须同节点,体现计算向数据移动。
节点免密和网络配置
先要关闭五台机的防火墙,这一点非常重要。否则后面启动zookeeper后,zkServer.sh status不能正常查看zk状态,三个zk之间无法通讯。第二个Namenode也无法同步第一个Namenode的数据。
systemctl stop firewalld
systemctl disable firewalld
按照规划修改/etc/hostname文件中的主机名,在/etc/hosts文件中增加五台机的主机名解析。
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.0.69 master1 10.0.0.70 master2 10.0.0.71 slave1 10.0.0.72 slave2 10.0.0.73 slave3
节点免密
由于master1、master2上可能会启动其他节点的脚本,所以master1和master2要对其他节点免密。
以master1为例,依次输入以下命令,将master1的公钥分发给其他节点,达到免密登录的目的。
注意一点,ssh-copy-id生成的authorized_keys权限是600,如果权限是644就没办法免密登录,这个文件权限要求很苛刻。ssh-keygen -t dsa -f ~/.ssh/id_dsa -P""
ssh-copy-id -i ~/.ssh/id_dsa.pub root@master2
scp ~/.ssh/id_dsa root@master2
zookeeper分布式集群搭建
从官网上下载apache-zookeeper-3.5.8-bin.tar.gz, 将文件解压到/usr/local/zookeeper,复制zoo_sample.cfg到同一目录,命名为zoo.cfg.然后在文件里配置
dataDir=/usr/local/zookeeper/data
server.1=slave1:2888:3888 server.2=slave2:2888:3888 server.3=slave3:2888:3888
然后在创建文件/usr/local/zookepper/data/myid,并写入相应的id【例如1】
其他2节点重复上面步骤,然后在各机器上执行/usr/local/zookeeper/bin/zkServer.sh start来启动zookeeper集群。
Hadoop分布式集群搭建
Hadoop基于Java开发,必须先安装jdk。本次实验使用的版本是jdk-11.0.8,安装完成后需要在环境变量里加入JAVA_HOME。
下载Hadoop
从官网下载hadoop-3.1.4.tar.gz,解压到/usr/local/hadoop目录下
配置Hadoop
1. 修改/usr/local/hadoop/etc/hadoop/hadoop.env.sh
export HADOOP_HOME=/usr/local/hadoop
export ZOOKEEPER_HOME=/usr/local/zookeeper
export HDFS_NAMENODE_USER=root # 为hadoop配置三个角色的用户
export HDFS_SECONDARYNAMEDODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_RESOURCEMANAGER_USER=root
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2. 修改/usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
3. 修改/usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>master2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>master2:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485;slave3:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/journaldata</value>
</property>
<property>
<name>dfs.ha.nn.not-become-active-in-safemode</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
4. 修改/usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
5. 修改/usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>这里配置为master1上执行hadoop classpath返回的内容</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
6. 修改/usr/local/hadoop/etc/hadoop/workers
slave1
slave2
slave3
启动Hadoop
1. 在slave1、slave2、slave3三台机执行/usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode命令,启动journalnode。
2. 在master1上执行/usr/local/hadoop/bin/hadoop namenode -format,对HDFS格式化【执行一次即可,后序无须执行】。
3. 第一次启动,在master1上执行/usr/local/hadoop/sbin/hadoop-daemon.sh start namenode。
4. 在master2上执行/usr/local/hadoop/bin/hadoop namenode -bootstrapStandby同步master1的信息。
5. 在master1上执行/usr/local/hadoop/bin/hdfs zkfc -formatZK格式化zkfc
6. 以上操作完成之后,在master1上执行/usr/local/hadoop/sbin/stop-all.sh,把相关的服务全部停掉。
7. 在master1上执行start-all.sh,启动集群。
此时hadoop高可用集群已经搭建完成,我们可以访问http://master1:9870,将会进入hadoop web UI
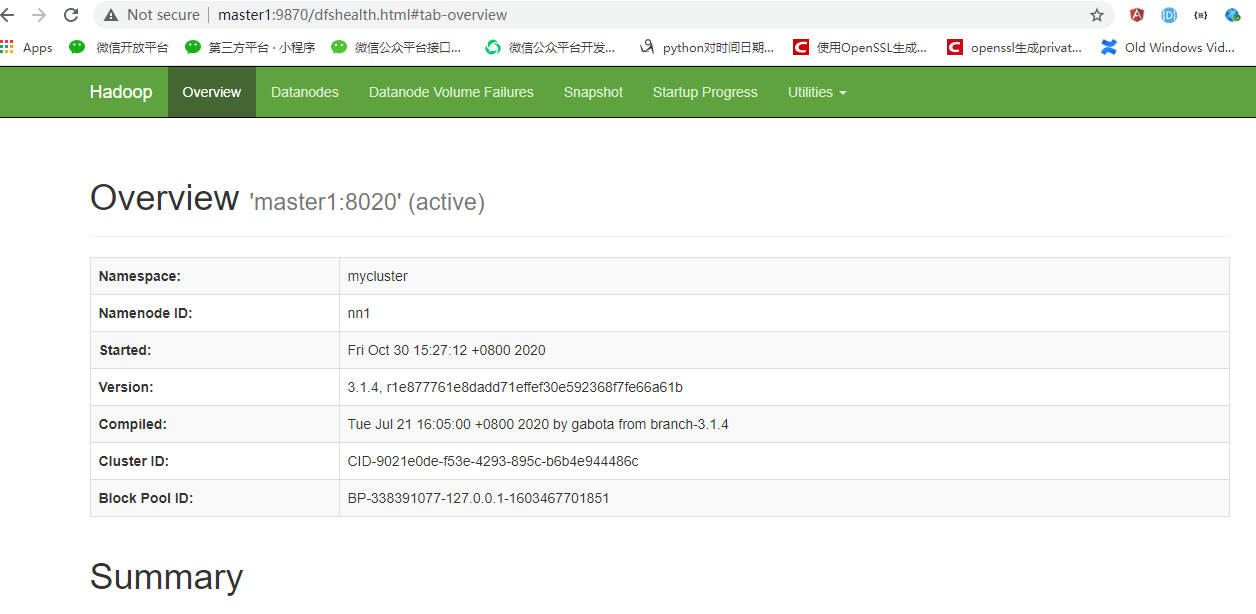
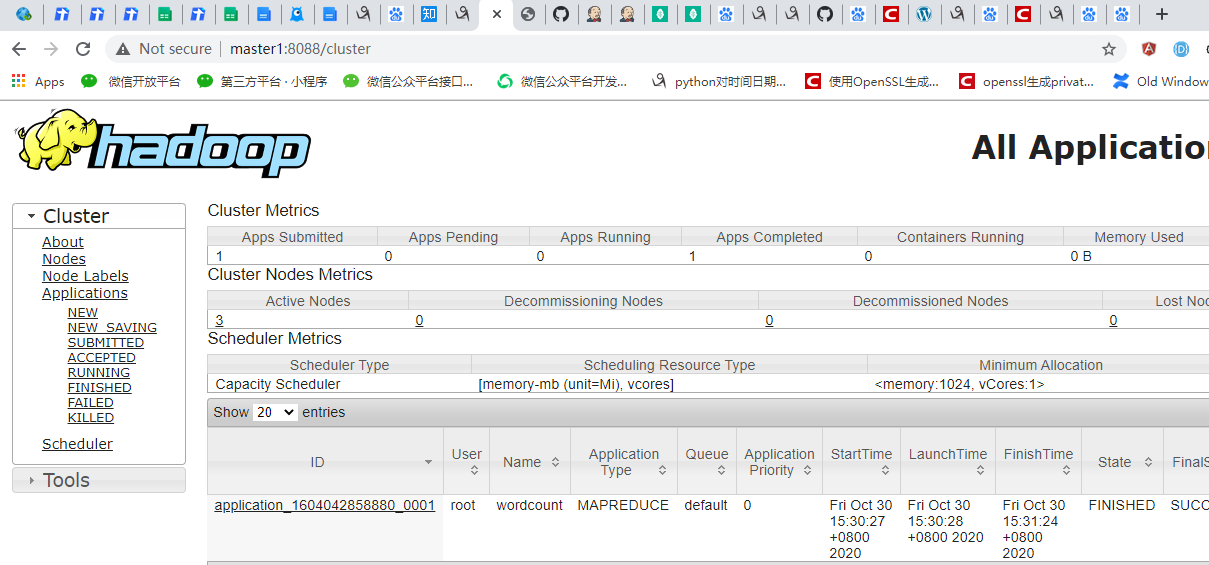
当然,我们也可以访问http://master1:8088可以访问yarn web


 浙公网安备 33010602011771号
浙公网安备 33010602011771号