机器学习|我们在UCL找到了一个糖尿病数据集,用机器学习预测糖尿病(一)
作者:Susan Li
编译:袁雪瑶、吴双、姜范波
根据美国疾病控制预防中心的数据,现在美国1/7的成年人患有糖尿病。但是到2050年,这个比例将会快速增长至高达1/3。我们在UCL机器学习数据库里一个糖尿病数据集,希望可以通过这一数据集,了解如何利用机器学习来帮助我们预测糖尿病,让我们开始吧!
https://github.com/susanli2016/Machine-Learning-with-Python/blob/master/diabetes.csv
数据:
糖尿病数据集可从UCI机器学习库中获取并下载。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
diabetes=pd.read_csv('C:\Download\Machine-Learning-with-Python-master\Machine-Learning-with-Python-master\diabetes.csv')
print(diabetes.columns)
Index(['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin',
'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'], dtype='object')
特征(怀孕次数,血糖,血压,皮脂厚度,胰岛素,BMI身体质量指数,糖尿病遗传函数,年龄,结果)
diabetes.head()
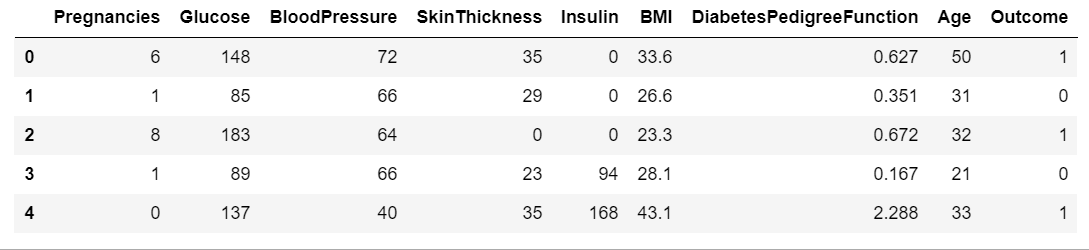
print(diabetes.groupby('Outcome').size())
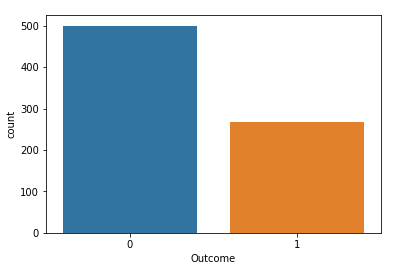
Outcome 0 500 1 268 dtype: int64 “结果”是我们将要预测的特征,0意味着未患糖尿病,1意味着患有糖尿病。在768个数据点中,500个被标记为0,268个标记为1。
print("dimennsion of diabetes data:{}".format(diabetes.shape))
dimennsion of diabetes data:(768, 9),糖尿病数据集由768个数据点组成,各有9个特征。
import seaborn as sns sns.countplot(diabetes['Outcome'],label="Count")
KNN算法:
k-NN算法几乎可以说是机器学习中最简单的算法。建立模型只需存储训练数据集。而为了对新的数据点做出预测,该算法会在训练数据集中找到与其相距最近的数据点——也就是它的“近邻点”。首先,让我们研究一下是否能够确认模型的复杂度和精确度之间的关系:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(diabetes.loc[:,diabetes.columns !='Outcome'],diabetes['Outcome'],stratify=diabetes['Outcome'],random_state=66)
from sklearn.neighbors import KNeighborsClassifier
training_accuracy=[]
test_accuracy=[]
#try n_neighbors from 1 to 10
neighbors_settings=range(1,11)
for n_neighbors in neighbors_settings:
#build the model
knn=KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(x_train,y_train)
#record training set accuracy
training_accuracy.append(knn.score(x_train,y_train))
#record test set accuracy
test_accuracy.append(knn.score(x_test,y_test))
plt.plot(neighbors_settings,training_accuracy,label="training accuracy")
plt.plot(neighbors_settings,test_accuracy,label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
plt.savefig('knn_compare_model')
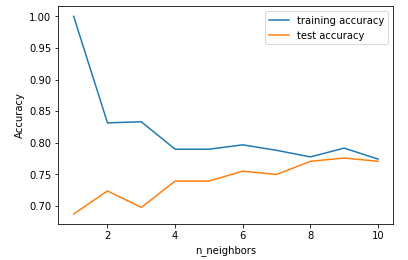
上图展示了训练集和测试集在模型预测准确度(y轴)和近邻点个数设置(x轴)之间的关系。如果我们仅选择一个近邻点,那么训练集的预测是绝对正确的。但是当更多的近邻点被选入作为参考时,训练集的准确度会下降,这表明了使用单一近邻会导致模型太过复杂。这里的最好方案可以从图中看出是选择9个近邻点。
图中建议我们应该选择n_neighbors=9,下面给出:
knn=KNeighborsClassifier(n_neighbors=9)
knn.fit(x_train,y_train)
print('Accuracy of K-NN classifier on training set:{:.2f}'.format(knn.score(x_train,y_train)))
print('Accuracy of K-NN classifier on training set:{:.2f}'.format(knn.score(x_test,y_test)))
Accuracy of K-NN classifier on training set:0.79 Accuracy of K-NN classifier on training set:0.78

 浙公网安备 33010602011771号
浙公网安备 33010602011771号