B树和B+树
1. 首先在介绍B树前,先看一个基础数据结构—二叉排序树。它的定义如下:
若左子树不空,则左子树上所有节点的值均小于它的根节点的值
若右子树不空,则右子树上所有节点的值均大于它的根节点的值
它的左、右子树也分别为二叉排序数(递归生成),如下图:
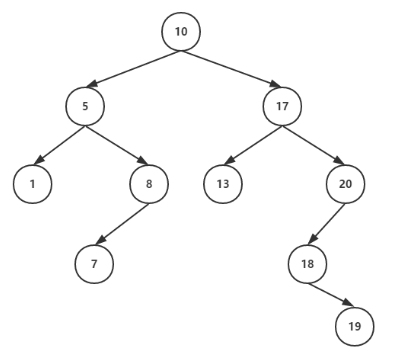
这样的数据结构能够帮助我们在O(logn) 的时间复杂度找到一个树,但是有个情况是如果这颗树的结构出现问题,出现一条支路非常长的情况下,就会出现失衡这种情况。所以因此延伸出平衡二叉树。而B树和B+树是一个平衡的多叉查找树。
2. B树:m阶平衡多叉查找树。样例如下:

性质如下:
1.根结点至少有两个子女(如果根节点是叶子节点,那么这颗树只有根节点这一个结点);
2.每个结点的值的个数为 1 <= n < m;
3.所有的叶子结点都位于同一层;
4.除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子。
5.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
6.每个结点中的值都按照从小到大的顺序排列,每个值的左子树中的所有的值都小于它,而右子树中的所有的值都大于它。
以一个3阶的B树为例插入思想:首先插入都是插入到叶子结点的。
1.该结点的关键字个数没有到达2个,那么直接插入即可;
2.该结点的关键字个数已经到达了2个,那么根据B树的性质显然无法满足,需要将其进行分裂,该结点分成两半,将中间的关键字进行提升,加入到父亲结点中,但是这又可能存在父亲结点也满员的情况,则不得不向上进行回溯,甚至是要对根结点进行分裂,那么整棵树都加了一层。
图解可以看:https://blog.csdn.net/m0_38075425/article/details/81777364
删除的话:http://www.cainiaoxueyuan.com/suanfa/4547.html 看这个就能清楚了。
2. B+树:
性质如下:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
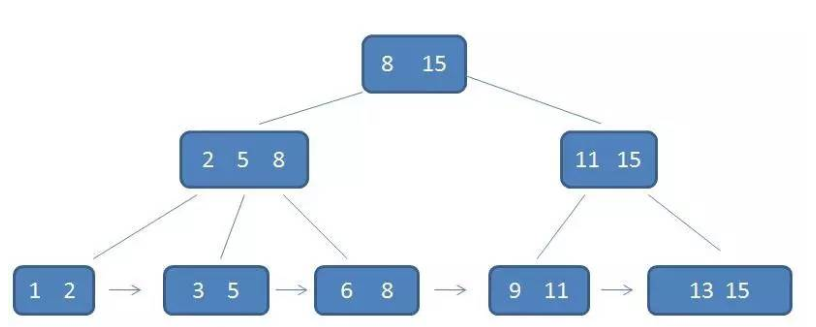
B+树相比B树的优势:IO 次数更少;查询性能更稳定(B+树的查询最终必须查找到叶子结点,而B树只要找到匹配元素即可);范围查询更简单(因为所有叶子节点形成有序链表)。
3. 为什么数据库索引中用B+数而不用B树
1.B+树的磁盘读写代价更低同时并没有解决元素遍历的效率低下的问题,
2.B+树的查询效率更加稳定
3.B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的

