HashMap
1. 我们知道Map是一个 key-val 的集合,HashMap是基于Hash表的Map接口的非同步实现。
2. HashMap的基本数据结构是数组和链表。(借鉴一张图)
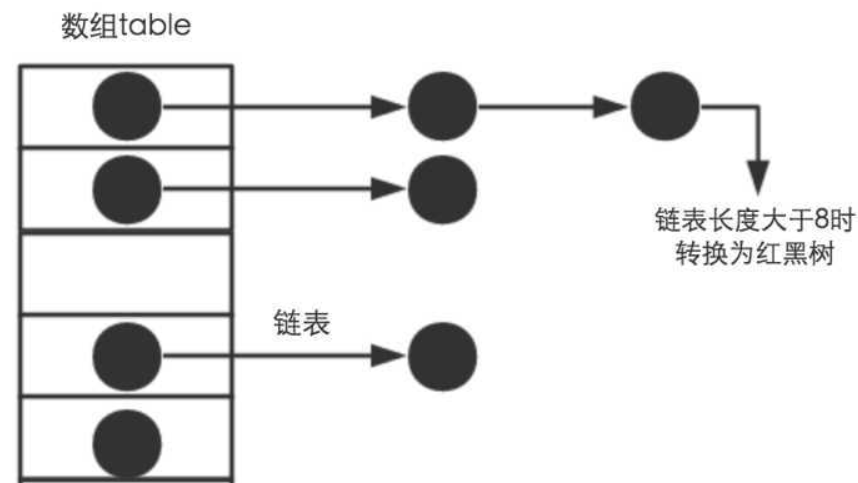
HashMap的存储原理:声明一个下标范围比较大的数组来存储元素,另外设计一个哈希函数获得每一个元素的Key(关键字)的函数值(即数组下标,hash值)相对应,数组存储的元素是一个Entry类,这个类有三个数据域,key、value(键值对),next(指向下一个Entry)。 当两个key通过哈希函数计算相同时,则发生了hash冲突(碰撞),HashMap解决hash冲突的方式是用链表。
例如, 第一个键值对A进来。通过计算其key的hash得到的index=0。记做:Entry[0] = A。
第二个键值对B,通过计算其index也等于0, HashMap会将B.next =A,Entry[0] =B,
第三个键值对 C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方事实上存取了A,B,C三个键值对,它们通过next这个属性链接在一起。所以当hash冲突很多时,HashMap退化成链表。
3. HashMap的存储过程
先判断键值对数组table[i] 是否为空否则进行扩容操作(resize());
根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加到最后一步,如果table[i]不为空进行下一步;
判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则进行下一步,这里的相同指的是hashCode以及equals;
判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则进行下一步;
遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
HashMap取值过程:
先通过key值进行哈哈希函数的运算得到hash值;
调用getNode(),得到桶号;
在桶里面找元素和key值相等的即可,未找到返回空。
4. HashMap的初始化容量为什么为2的次幂?
因为在get()方法中,获得元素的位置是通过(length- 1) & h 来得到的,其中 h:为插入元素的hashcode length:为map的容量大小。如果length为2的次幂 则length-1 转化为二进制必定是11111……的形式,在于h的二进制与操作效率会非常的快,而且空间不浪费。如果是其他的话,空间不够,碰撞的几率变大,查询变慢,空间会浪费。
5. 为什么HashMap是非线程安全的?
首先我们知道为了减少冲突,我们需要时刻留意当前的size是否太大,检查是否需要扩容,一旦超过设定的threshold,那么就要重新增大数组尺寸,此时所有元素都需要重新计算应该放置的下标。同时HashMap在扩容的时候,是通过重新创建一个新的hash表,把原来旧数组中的Entry一个个迁移到新数组的,注意一点就是计算在newTable中的位置,原来在同一条链上的元素可能被分配到不同的位置。
单线程的情况resize()是没有问题的,但是多线程的时候就可能会出现形成环形链表的情况,导致扩容失败。具体详细的图可以看https://blog.csdn.net/andy_budd/article/details/81413464
6. HashMap和HashTable的区别:
HashTable 是不能接受NULL,NULL值组合的,而HashMap可以。(因为HashMap做了对应的NULL值处理,会把NULL值的键值对放到hashcode 为0 的链表里面)。
HashTable是线程安全的,HashMap是线程非安全的。因为HashTable是synchronized,要想是HashMap线程安全Map m = Collections.synchronizeMap(hashMap);

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步