
Mysql 源码解读-优化器
一条 sql 执行过程中,首先进行词法分析和语法分析,然后将由优化器进行判断,如何执行更有效率,生成执行计划。在前几篇文章中,我们已经介绍了 AST 语法树是如何生成的,接下来我们探索一下 MySQL 的优化器,查询优化器是专门负责优化查询语句的优化器模块,通过计算分析收集的各种系统统计信息,为查询给出最优的执行计划——最优的数据检索方式。
MySQL的优化器主要是将SQL经过语法解析/词法解析后得到的语法树,通过MySQL的数据字典和统计信息的内容,经过一系列运算,从而得出一个执行计划树的构成。之后MySQL按照执行树的要求,计算得出结果。也就是说优化器的输入是一个语法树,输出是一个执行树(也称为执行计划),SQL优化器的具体模块参考如下图:
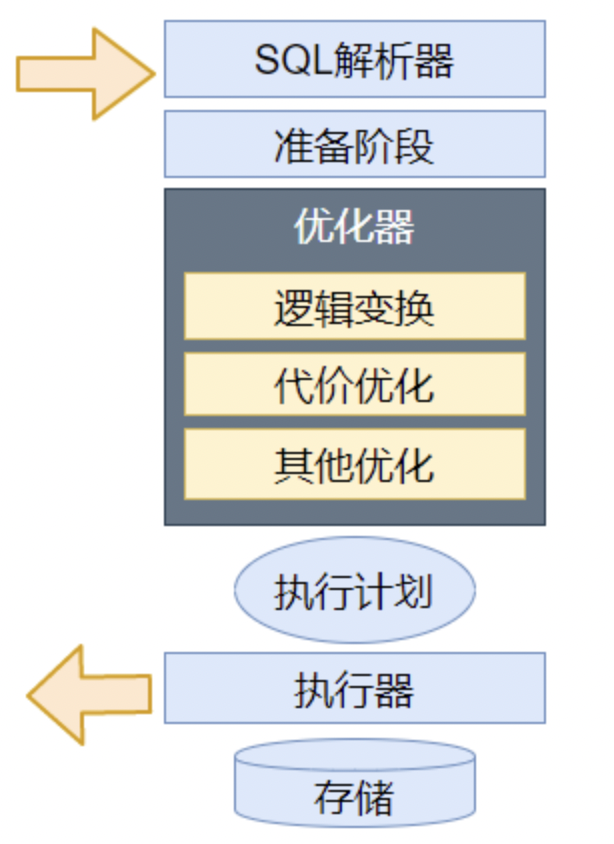
准备阶段
准备阶段是第一阶段,用于为整个查询做准备工作。其中包括准备表、检查表是否可以访问、检查字段、检查非 group 函数、准备 procedure 等工作。准备阶段的函数调用堆栈如下所示:
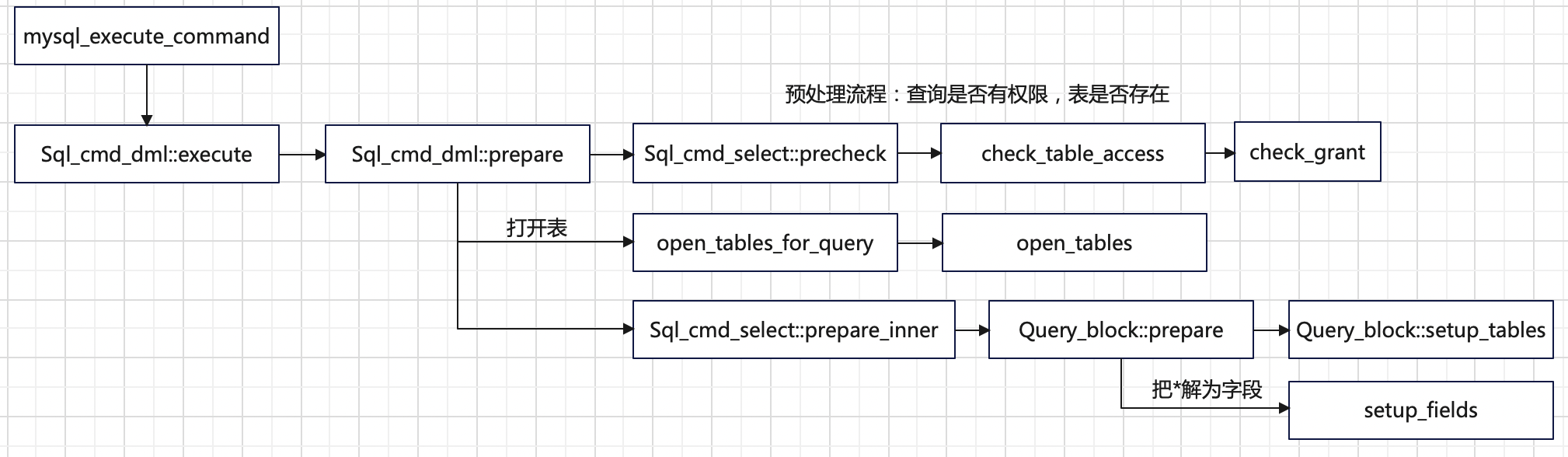
注意:本文只跟踪了prepare 的一部分代码,仅仅打开表操作就非常复杂,准备阶段不是我们分析的重点。不再继续向下深入。
参考文章:MySQL 简单查询语句执行过程分析(二)查询准备阶段
优化阶段
通过优化器模块我们看到,生成执行计划之前需要经过逻辑变换,代价优化,其他优化。
逻辑变换,逻辑优化阶段主要解决的问题是: 如何找出SQL语句等价的变换形式,使得SQL执行更高效 。主要包括:
1)否定消除:对于多个表达式的和取或析取范式前面有否定的情况,应将关系条件分解成一个一个的,将外面的NOT消除;
2)等值常量传递:利用了等值关系的传递特性,为了能够尽早执行下推运算(后面会讲到);
3)常量表达式计算:对于能够立刻计算出结果的表达式,直接计算结果,并将结果与其他条件尽量提前化简
代价优化也称物理优化阶段,主要是用来确定对于每个表,根据条件是否应用索引,应用哪个索引和确定多表连接的顺序等问题。MySQL的代价模型如下。一个查询最基础的就是计算两个表JOIN的代价,代价模型就是根据已知信息(元信息,统计信息等)计算该JOIN的代价,即该运算的预估行数✖️单位代价。
可以看到:优化器无论是在准备阶段还是优化阶段都是一个非常复杂的过程,本文的目的是为了跟进查看最终生产的执行计划是什么样的,并非分析优化器是如何实现的。因为笔者能力有限,且分析 MySQL 的优化器需要大量的时间和精力,因此我们不再具体跟进 mysql 的优化。
执行计划
在MySQL中,执行计划的实现是基于JOIN和QEP_TAB这两个对象。其中JOIN类表示一个查询语句块的优化和执行,每个select查询语句(即Query_block对象)在处理的时候,都会被当做JOIN对象,其定义在sql/sql_optimizer.h。
QEP_TAB是Query Execution Plan Table的缩写,这里的表Table对象主要包含物化表、临时表、派生表、常量表等。JOIN::optimize()是优化执行器的统一入口,在这里会把一个查询语句块Query_block最终优化成QEP_TAB。
在MySQL-8.0.22版本之后,又引入访问方式AccessPath和执行迭代器Iterator对象,再结合JOIN和QEP_TAB对象,最终得到整个解析计划的执行路径。
数据结构
类QEP_shared,保存JOIN_TAB和QEP_TAB公用的成员。QEP_shared类的函数都是一些getter和setter,它的成员如下:
JOIN *m_join; plan_idx m_idx; // 数组中的索引结构,如果在get_best_combination()之前,则为NO_PLAN_IDX。JOIN::best_ref数组中指向此JOIN_TAB的指针索引。在JOIN::QEP数组中,为QEP_TAB的索引 TABLE *m_table; // 对应的表。可能是内部的临时表 POSITION *m_position; // 指向best_positions数组。包括成本信息。 Semijoin_mat_exec *m_sj_mat_exec; // 半联接实体化所需的结构。为物化临时表设置,为所有其他join_tabs设置NULL(除非正在进行物化,请参见join_materialize_mijoin())。 plan_idx m_first_sj_inner, m_last_sj_inner; // 此表周围的半联接内部表的边界。仅在选择最终QEP后有效。根据策略,它们可能会定义一个间隔(内部的所有表都在半联接内部)而不是。 // last_sj_inner未为Duplicates Weedout设置 plan_idx m_first_inner; // 包含外部联接的第一个内部表 plan_idx m_last_inner; // 用于嵌入外部联接的最后一个表 plan_idx m_first_upper; // 用于嵌入外部联接的第一个内部表 TABLE_REF m_ref; // 用于基于键值进行基于索引的查找。当我们读取常量表时,在其他优化(如remove_cast())和执行中使用 uint m_index; // 用于索引扫描或半联接LooseScan的索引ID enum join_type m_type; // 所选访问方法的类型(扫描等)。 Item *m_condition; // 表条件,即要为该表中的一行计算的条件。请注意,该条件可能引用联接前缀中先前表中的行以及外部表。 /** m_condition中的条件是否在排序之前求值,以便不需要再次求值(除非它是内部联接的外部;请参阅SortingIterator::Init()中的相关注释。 请注意,在这种情况下,m_condition保持为非空ptr,这是为了(非树)EXPLAIN和filesort构建其读取映射。 */ bool m_condition_is_pushed_to_sort = false; Key_map m_keys; // 可以使用带有的所有键。由add_key_field()(优化时间)和动态范围(DynamicRangeIterator)的执行以及EXPLAIN使用。 ha_rows m_records; // 表中的行数,常量表的行数为1. 用于优化,也用于FOUND_ROWS()的执行 AccessPath *m_range_scan = nullptr; // 如果使用快速选择,则为非NULL。填充优化,在执行前转换为RowIterator(用于查找行),并在EXPLAIN中 /* 下面的映射是由于动态范围而共享的:在执行过程中,它需要知道前缀表,以找到可能的QUICK方法。 */ table_map prefix_tables_map; // 此表的联接前缀中可用的所有表的集合,包括此join_TAB处理的表。 table_map added_tables_map; // 与联接前缀中的前一个表相比,为此表添加的表集 Item_func_match *m_ft_func; // 全文函数 bool m_skip_records_in_range; // 设置此查询是否可以跳过索引俯冲, 请参见check_skip_records_in_range_qualification的注释。
类QEP_shared_owner。QEP_shared的所有者;JOIN_TAB和QEP_TAB的父类。
class QEP_shared_owner { public: QEP_shared_owner() : m_qs(nullptr) {} /// Instructs to share the QEP_shared with another owner void share_qs(QEP_shared_owner *other) { other->set_qs(m_qs); } void set_qs(QEP_shared *q) { assert(!m_qs); m_qs = q; } ... protected: QEP_shared *m_qs; // qs stands for Qep_Shared };
类JOIN_TAB,查询优化计划节点。指定:此节点指定的表上的表访问操作,以及上一组计划节点的结果与此计划节点之间的联接。
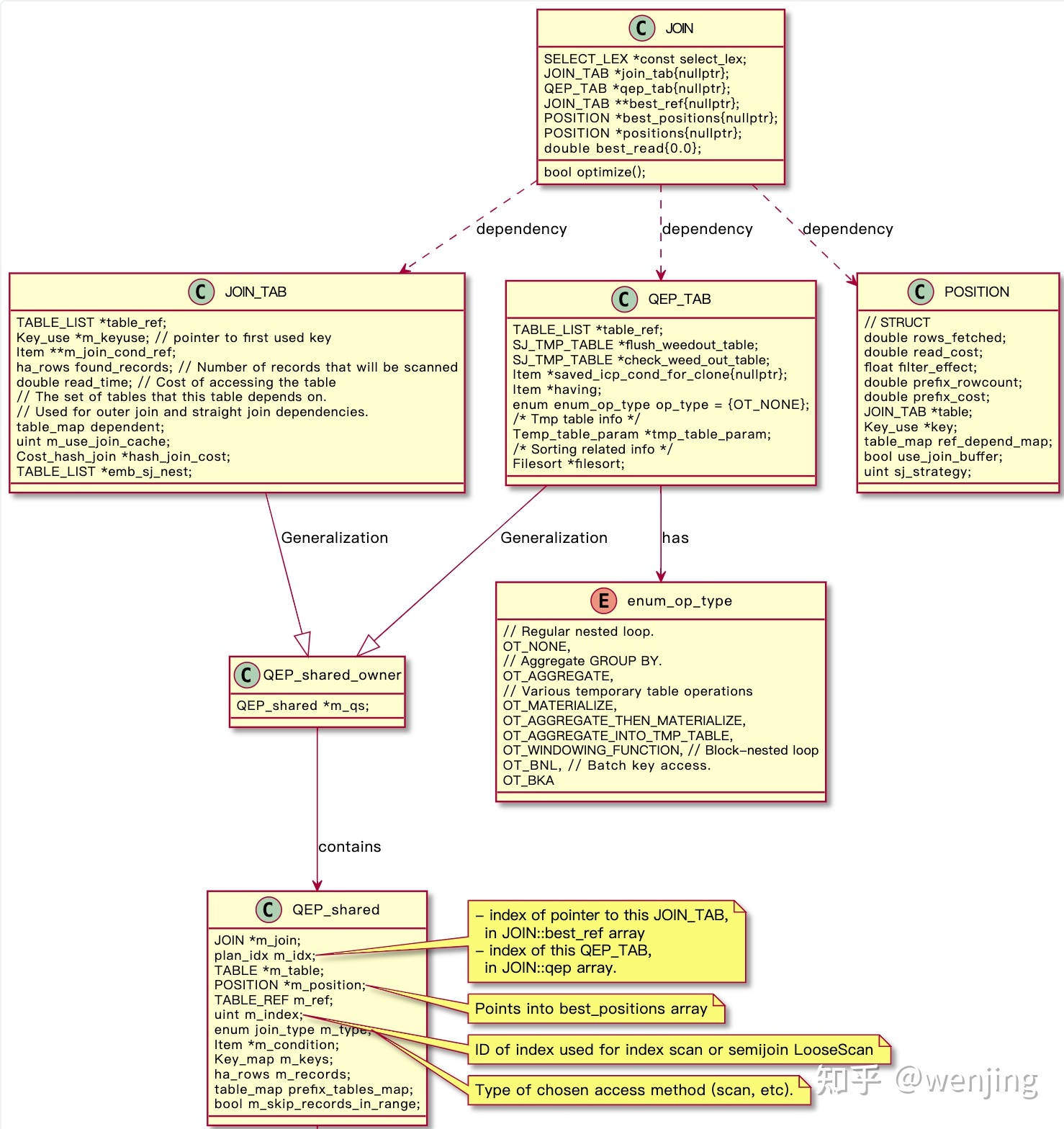
代码概览
优化器的入口函数:bool JOIN::optimize(),对应代码文件sql/sql_optimizer.cc。
// 主要功能是把一个查询块Query_block优化成一个QEP_TAB,得到AccessPath bool JOIN::optimize() { ... // 下面主要是为了可以借助INFORMATION_SCHEMA.OPTIMIZER_TRACE表,跟踪优化器的执行状态和执行步骤 Opt_trace_context *const trace = &thd->opt_trace; Opt_trace_object trace_wrapper(trace); Opt_trace_object trace_optimize(trace, "join_optimization"); trace_optimize.add_select_number(Query_block->select_number); Opt_trace_array trace_steps(trace, "steps"); ... // 窗口函数装配优化 if (has_windows && Window::setup_windows2(thd, m_windows)) ... // 拷贝Query_block上的条件副本到JOIN结构关联的成员对象,为后续优化做准备 if (Query_block->get_optimizable_conditions(thd, &where_cond, &having_cond)) ... // 统计抽象语法树中的叶节点表,其中leaf_tables是在Query_block::setup_tables中进行装配 tables_list = Query_block->leaf_tables; ... // 分区裁剪 if (Query_block->partitioned_table_count && prune_table_partitions()) { ... // 尝试把聚合函数COUNT()、MIN()、MAX()对应的值,替换成常量 if (optimize_aggregated_query(thd, Query_block, *fields, where_cond, &outcome)) { ... // 采用超图算法生成执行计划,注意超图算法通过set optimizer_switch="hypergraph_optimizer=on"方式启用 if (thd->lex->using_hypergraph_optimizer) { FindBestQueryPlan(thd, Query_block, /*trace=*/nullptr); // 如果Join优化器是超图算法,处理结束直接返回 return false; } ...
下面代码主要涉及Join优化器连接方式为左深树的情况,主要用到join_tab数组来进行组织关联
根据代价计算表的连接方式,核心函数make_join_plan(),实现非常复杂。比较关键的函数是bool Optimize_table_order::choose_table_order()
其主要思想是通过贪婪搜索Optimize_table_order::greedy_search,根据最小的连接代价,进行有限的穷举搜索(细节参考Optimize_table_order::best_extension_by_limited_search)最终找到近似最优解的连接排列组合
if (make_join_plan()) { ... // 语句块谓词条件下推,提升过滤性能 if (make_join_Query_block(this, where_cond)) { ... // 优化order by/distinct语句 if (optimize_distinct_group_order()) return true; ... // 分配QEP_TAB数组 if (alloc_qep(tables)) return (error = 1); /* purecov: inspected */ ... // 执行计划细化,优化子查询和半连接的情况,具体策略可以参考mariadb的文档: // https:// mariadb.com/kb/en/optimization-strategies/ // 关键代码是setup_semijoin_dups_elimination,主要对半连接关联的策略进行装配 if (make_join_readinfo(this, no_jbuf_after)) ... // 为处理group by/order by创建开辟临时表空间 if (make_tmp_tables_info()) return true; ... // 生成访问方式AccessPath,供后续迭代器Iterator访问使用 create_access_paths(); ... return false; }
优化器最终生成AccessPath。
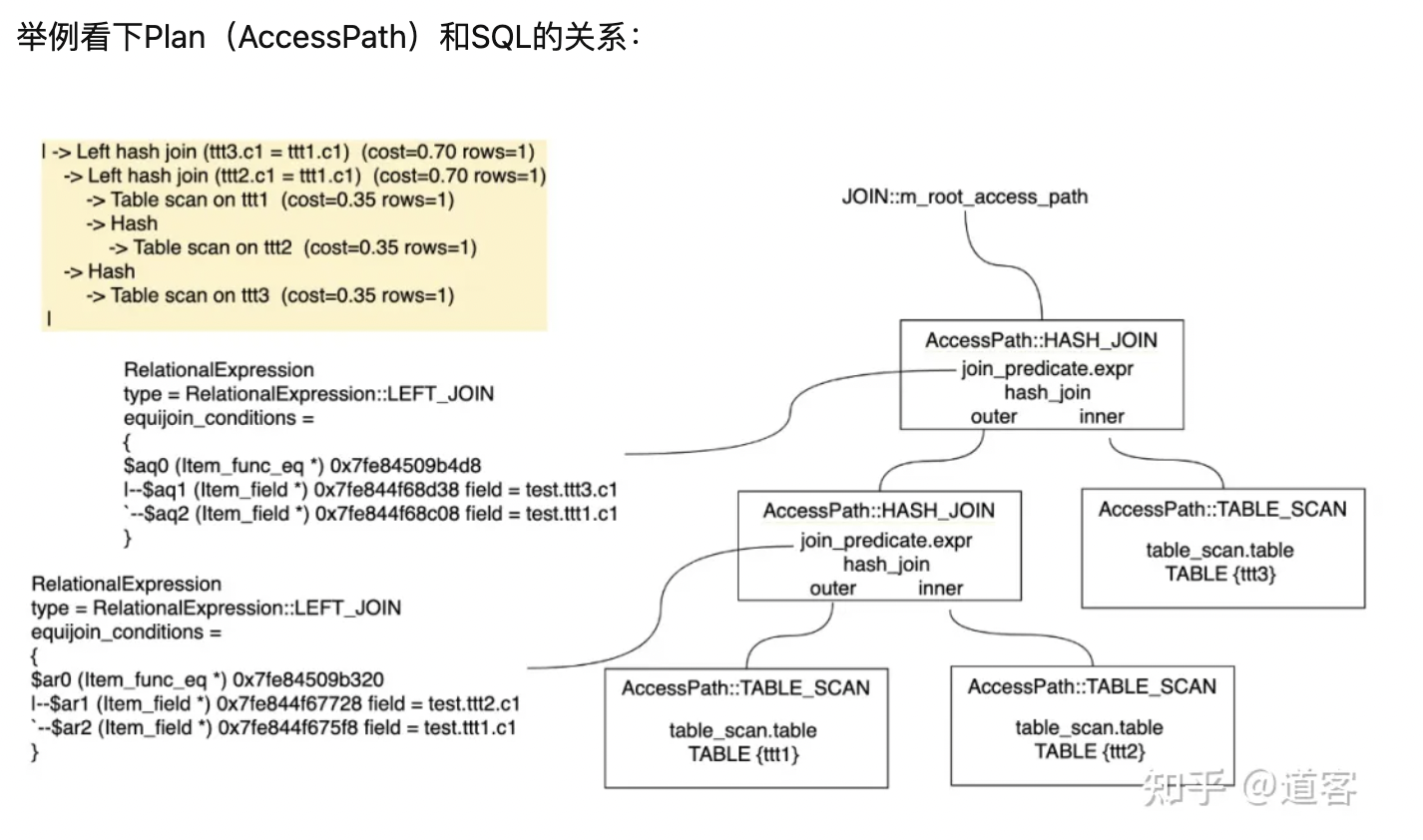

在我们示例中的 sql,可以看到了生成了 TABLE_SCAN 的访问路径 。
在优化器的最后,生成Iterator执行器框架需要的Iterator执行载体,AccessPath和Iterator是一对一的关系。
Query_expression::m_root_iterator = CreateIteratorFromAccessPath(......)
参考博客:MySQL 查询优化器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号