
Mysql 源码解读-执行器
一条 sql 执行过程中,首先进行词法分析和语法分析,然后将由优化器进行判断,如何执行更有效率,生成执行计划,后面的任务就交给了执行器。在执行的过程中,执行器就会和存储引擎交互了,交互是以记录为单位的。本文我们介绍下 MySQL8的执行器。
在前几篇文章中,我们讲述了 MySQL 的词法分析和语法分析,以及一条 sql 语句是如何生产 AST 树的。MySQL 在做完语法解析后,调用函数 mysql_execute_command 进入查询优化器。查询优化器对 sql 语句进行了一系列的转换,重写,优化最终生产了 AccessPath(访问路径),并且根据AccessPath创建Iterator迭代器。
火山模型
火山模型是数据库查询执行最著名的模型,也是在各种数据库系统中应用最广泛的模型。SQL语句在数据库中经过语法解析生产 AST 语法树,然后遍历语法树,生成执行树。执行树的每个节点为代数运算符(Operator)。火山模型把Operator看成迭代器,每个迭代器都会提供一个next() 接口。一般Operator的next() 接口实现分为三步
(1)调用子节点Operator的next() 接口获取一行数据(tuple)
(2)对tuple进行Operator特定的处理(如filter 或project 等)
(3)返回处理后的tuple
因此,查询执行时会由查询树自顶向下的调用next() 接口,数据则自底向上的被拉取处理。这种处理方式也称为拉取执行模型(Pull Based)。例如以下 SQL:
SELECT Id, Name, Age, (Age - 30) * 50 AS Bonus FROM People WHERE Age > 30
对应火山模型如下:
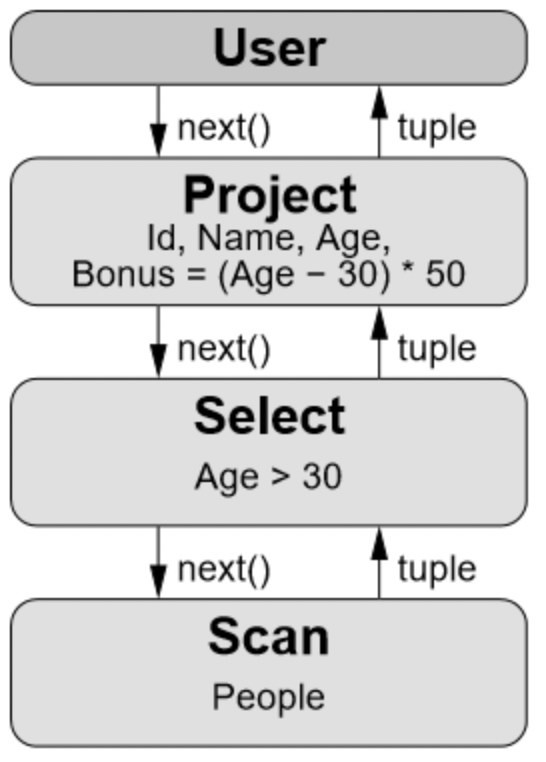
其中——
User:客户端;
Project:垂直分割(投影),选择字段;
Select(或 Filter):水平分割(选择),用于过滤行,也称为谓词;
Scan:扫描数据。
这里包含了 3 个 Operator,首先 User 调用最上方的 Operator(Project)希望得到 next tuple,Project 调用子节点(Select),而 Select 又调用子节点(Scan),Scan 获得表中的 tuple 返回给 Select,Select 会检查是否满足过滤条件,如果满足则返回给 Project,如果不满足则请求 Scan 获取 next tuple。Project 会对每一个 tuple 选择需要的字段或者计算新字段并返回新的 tuple 给 User。当 Scan 发现没有数据可以获取时,则返回一个结束标记告诉上游已结束。
为了更好地理解一个 Operator 中发生了什么,下面通过伪代码来理解 Select Operator:
Tuple Select::next() { while (true) { Tuple candidate = child->next(); // 从子节点中获取 next tuple if (candidate == EndOfStream) // 是否得到结束标记 return EndOfStream; if (condition->check(candidate)) // 是否满足过滤条件 return candidate; // 返回 tuple } }
可以看出火山模型的优点在于:简单,每个 Operator 可以单独抽象实现、不需要关心其他 Operator 的逻辑。
那么缺点呢?也够明显吧?每次都是计算一个 tuple(Tuple-at-a-time),这样会造成多次调用 next ,也就是造成大量的虚函数调用,这样会造成 CPU 的利用率不高。当然也有优化方式,请参考: SQL优化之火山模型、向量化、编译执行
迭代器模式介绍
MySQL8.0对执行器进行了改进,创建一个新的用于迭代访问记录的API,它足够通用。主要实现了一个通用的 C++ 类接口,叫做 RowIterator,它具有以下成员和函数:
构造和析构函数
| 迭代器类型 | 说明 |
| TableScanIterator | 顺序扫描,调用存储引擎接口ha_rnd_next获取一行记录 |
| IndexScanIterator | 全量索引扫描,根据扫描顺序,分别调用ha_index_next或者ha_index_prev来获取一行记录 |
| IndexRangeScanIterator | 范围索引扫描,包装了下QUICK_SELECT_I,调用QUICK_SELECT_I::get_next来获取一行记录 |
| SortingIterator | 对另一个迭代器输出进行排序 |
| SortBufferIterator | 从缓冲区读取已经排好序的结果集,(主要给SortingIterator调用) |
| SortBufferIndirectIterator | 从缓冲区读取行ID然后从表中读取对应的行(由SortingIterator和某些形式的unique操作使用) |
| SortFileIterator | 从文件中读取已经排好序的结果集(主要给SortingIterator调用) |
| SortFileIndirectIterator | 从文件读取行ID然后从表中读取对应的行(由SortingIterator和某些形式的unique操作使用) |
| RefIterator | 从连接右表中读取指定key的行 |
| RefOrNullIterator | 从连接右表中读取指定key或者为NULL的行 |
| EQRefIterator | 使用唯一key来从连接的右表中读取行 |
| ConstIterator | 从一个只可能匹配出一行的表(Const Table)中读取一行数据 |
| FullTextSearchIterator | 使用全文检索索引读取一行数据 |
| DynamicRangeIterator | 为每一行调用范围优化器,然后根据需要包装QUICK_SELECT_I或表扫描 |
| PushedJoinRefIterator | 读取已下推到NDB的连接的输出 |
| FilterIterator | 读取一系列行,输出符合条件的行,用来实现WHERE/HAVING |
| LimitOffsetIterator | 从offset开始读取行,直到满足limit限制,用来实现LIMIT/OFFSET |
| AggregateIterator | 实现聚集函数并且如果需要的话进行分组操作 |
| NestedLoopiterator | 使用嵌套循环算法连接两个迭代器(内连接,外连接或反连接) |
| MaterializeIterator | 从另一个迭代器读取结果,并放入临时表,然后读取临时表记录 |
| FakeSingleRowIterator | 返回单行,然后结束。 仅在某些使用const表情况下才使用(例如只有const表,仍然需要一个迭代器来读) |
函数调用栈
如下图所示:调用Query_expression::execute函数进入执行阶段:
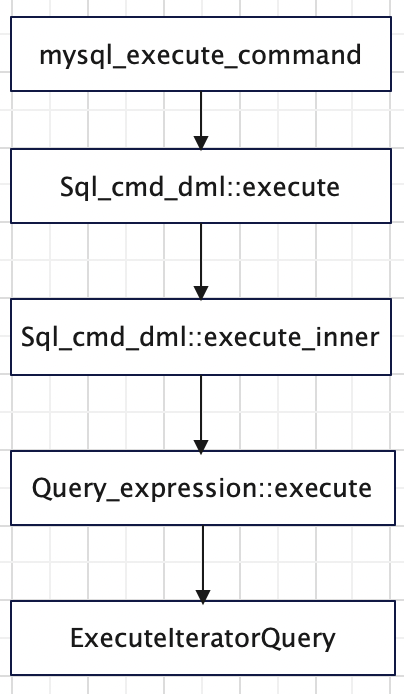
函数ExecuteIteratorQuery浅析
1、is_simple()函数用来判断一个查询表达式是否有union或者多级order,如果没有说明这个查询语句简单。就执行add_select_number。
2、运行ClearForExecution函数。在初始化root迭代器之前,把之前的执行迭代器的数据清除。
3、运行get_field_list(),获取查询表达式的字段列表,并将所有字段都放到一个deque中,即mem_root_deque<Item*>;对于查询块的并集,返回在准备期间生成的字段列表,对于单个查询块,尽可能返回字段列表
4、运行start_execution,准备执行查询表达式或DML查询
5、接下来的一些操作与第二引擎有关,关于该引擎见https://www.h5w3.com/123061.html。Secondary Engine实际上是MySQL sever上同时支持两个存储引擎,把一部分主引擎上的数据,在Secondary Engine上也保存一份,然后查询的时候会根据优化器的的选择决定在哪个引擎上处理数据。
6、如果该查询用于子查询,那么重新reset,指向子查询。
7、接下来是对于复杂句以及简单句的不同处理,从而给send_records_ptr赋值。
函数对于这个情况的解释如下:
We need to accumulate in the first join's send_records as long as we support SQL_CALC_FOUND_ROWS, since LimitOffsetIterator will use it for reporting rows skipped by OFFSET or LIMIT. When we get rid of SQL_CALC_FOUND_ROWS, we can use a local variable here instead.
情况一:如果该查询块具有UNION或者多级的ORDER BY/LIMIT的话 UNION with LIMIT的话,found_rows()用于最外层 LimitOffsetIterator跳过偏移量行写入send_records
情况二:如果是个简单句的话 found_rows()直接用到join上。LimitOffsetIterator跳过偏移量行写入send_records
情况三:如果是UNION,但是没有LIMIT。found_rows()用于最外层。
8、重置计数器
9、接下来是一个对查询块遍历,逐个释放内存的操作,用以增加并发性并减少内存消耗。
10、初始化根迭代器
11、然后for循环,从根迭代器一直到引擎的handler,调用读取数据。如果出错就直接返回。如果收到kill信号,也返回。在循环中对send_records_ptr进行累加。行计数器++,指向下一行。
12、将send_records_ptr赋值给该线程的current_found_rows

 浙公网安备 33010602011771号
浙公网安备 33010602011771号