
MySQL 源码解读之-语法解析(二)
承接上一篇博客中提到了语法解析中涉及的数据结构。我们继续分析MySQL 在做语法分析的执行过程。MySQL的语法分析器是用bison工具生成的,bison是一个语法分析器生成工具。bison的规则文件是sql/sql_yacc.yy,经过编译后会生成sql/sql_yacc.cc文件。
sql_yacc.yy中,用熟悉的EBNF格式定义了MySQL的语法规则。我节选了与select语句有关的规则,如下所示,从中你可以体会一下,SQL语句的语法是怎样被一层一层定义出来的:
start_entry: sql_statement ; sql_statement: END_OF_INPUT | simple_statement_or_begin ; simple_statement_or_begin: simple_statement { *parse_tree= $1; } | begin_stmt ; simple_statement: alter_database_stmt { $$= nullptr; } | ... | alter_function_stmt { $$= nullptr; } | select stmt ; select_stmt: query_expression | ... | select_stmt_with_into ; query_expression: query_expression_body opt_order_clause opt_limit_clause | with_clause query_expression_body opt_order_clause opt_limit_clause | ... ; query_expression_body: query_primary | query_expression_body UNION_SYM union_option query_primary | ... ; query_primary: query_specification | table_value_constructor | explicit_table ; query_specification: ... | SELECT_SYM /*select关键字*/ select_options /*distinct等选项*/ select_item_list /*select项列表*/ opt_from_clause /*可选:from子句*/ opt_where_clause /*可选:where子句*/ opt_group_clause /*可选:group子句*/ opt_having_clause /*可选:having子句*/ opt_window_clause /*可选:window子句*/ ; ...
其中,query_expression就是一个最基础的select语句,它包含了SELECT关键字、字段列表、from子句、where子句等。
你可以看一下select_options、opt_from_clause和其他几个以opt开头的规则,它们都是SQL语句的组成部分。opt是可选的意思,也就是它的产生式可能产生ε(ε表示空串)。
opt_from_clause: /* Empty. */ | from_clause ;
另外,你还可以看一下表达式部分的语法。在MySQL编译器当中,对于二元运算,你可以大胆地写成左递归的文法。因为它的语法分析的算法用的是LALR,这个算法能够自动处理左递归。
一般研究表达式的时候,我们总是会关注编译器是如何处理结合性和优先级的。那么,bison是如何处理的呢?
原来,bison里面有专门的规则,可以规定运算符的优先级和结合性。在sql_yacc.yy中,你会看到如下所示的规则片段:
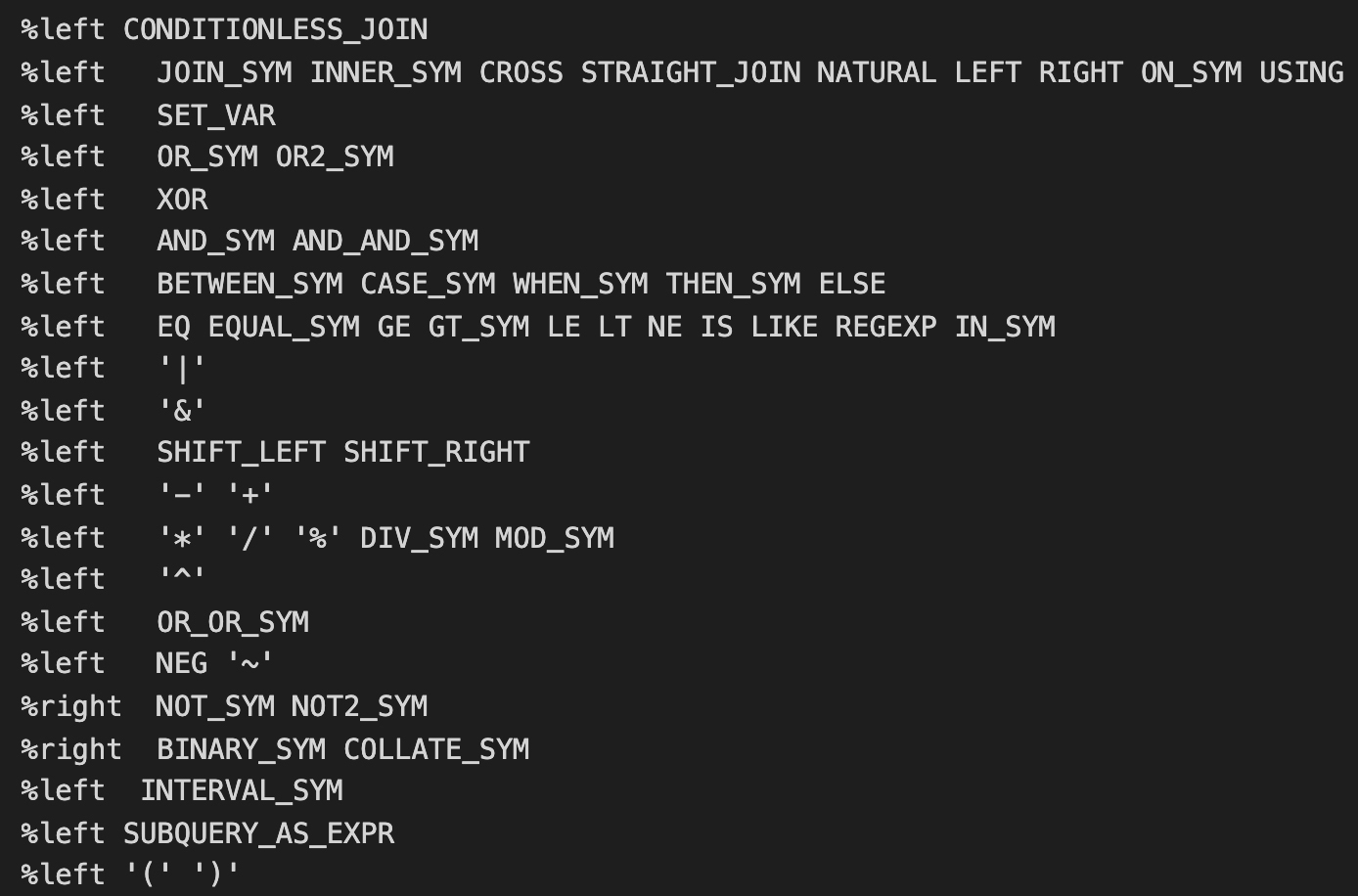
你可以看一下bit_expr的产生式,它其实完全把加减乘数等运算符并列就行了。
bit_expr : ... | bit_expr '+' bit_expr %prec '+' | bit_expr '-' bit_expr %prec '-' | bit_expr '*' bit_expr %prec '*' | bit_expr '/' bit_expr %prec '/' ... | simple_expr
如果你只是用到加减乘除的运算,那就可以不用在产生式的后面加%prec这个标记。但由于加减乘除这几个还可以用在其他地方,比如“-a”可以用来表示把a取负值;减号可以用在一元表达式当中,这会比用在二元表达式中有更高的优先级。也就是说,为了区分同一个Token在不同上下文中的优先级,我们可以用%prec,来说明该优先级是上下文依赖的。
好了,在了解了词法分析器和语法分析器以后,我们接着来跟踪一下MySQL的执行,看看编译器所生成的解析树和AST是什么样子的。
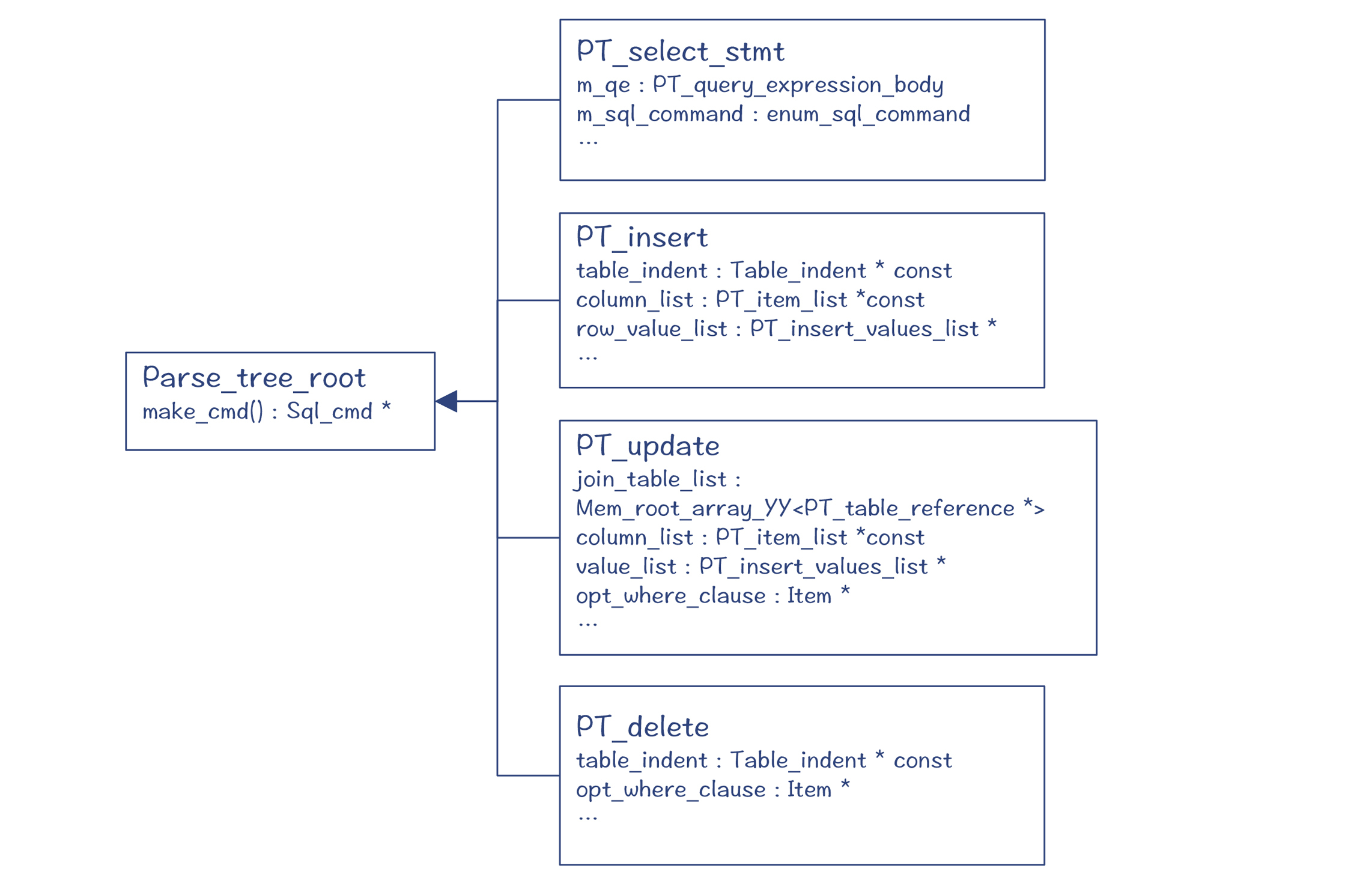
在sql_class.cc的sql_parser()方法中,编译器执行完解析程序之后,会返回解析树的根节点root,在GDB中通过p命令,可以逐步打印出整个解析树。你会看到,它的根节点是一个PT_select_stmt指针(见图3)。
解析树的节点是在语法规则中规定的,这是一些C++的代码,它们会嵌入到语法规则中去。
下面展示的这个语法规则就表明,编译器在解析完query_expression规则以后,要创建一个PT_query_expression的节点,其构造函数的参数分别是三个子规则所形成的节点。对于query_expression_body和query_primary这两个规则,它们会直接把子节点返回,因为它们都只有一个子节点。这样就会简化解析树,让它更像一棵AST
query_expression: query_expression_body opt_order_clause opt_limit_clause { $$ = NEW_PTN PT_query_expression($1, $2, $3); /*创建节点*/ } | ... query_expression_body: query_primary { $$ = $1; /*直接返回query_primary的节点*/ } | ... query_primary: query_specification { $$= $1; /*直接返回query_specification的节点*/ } | ...
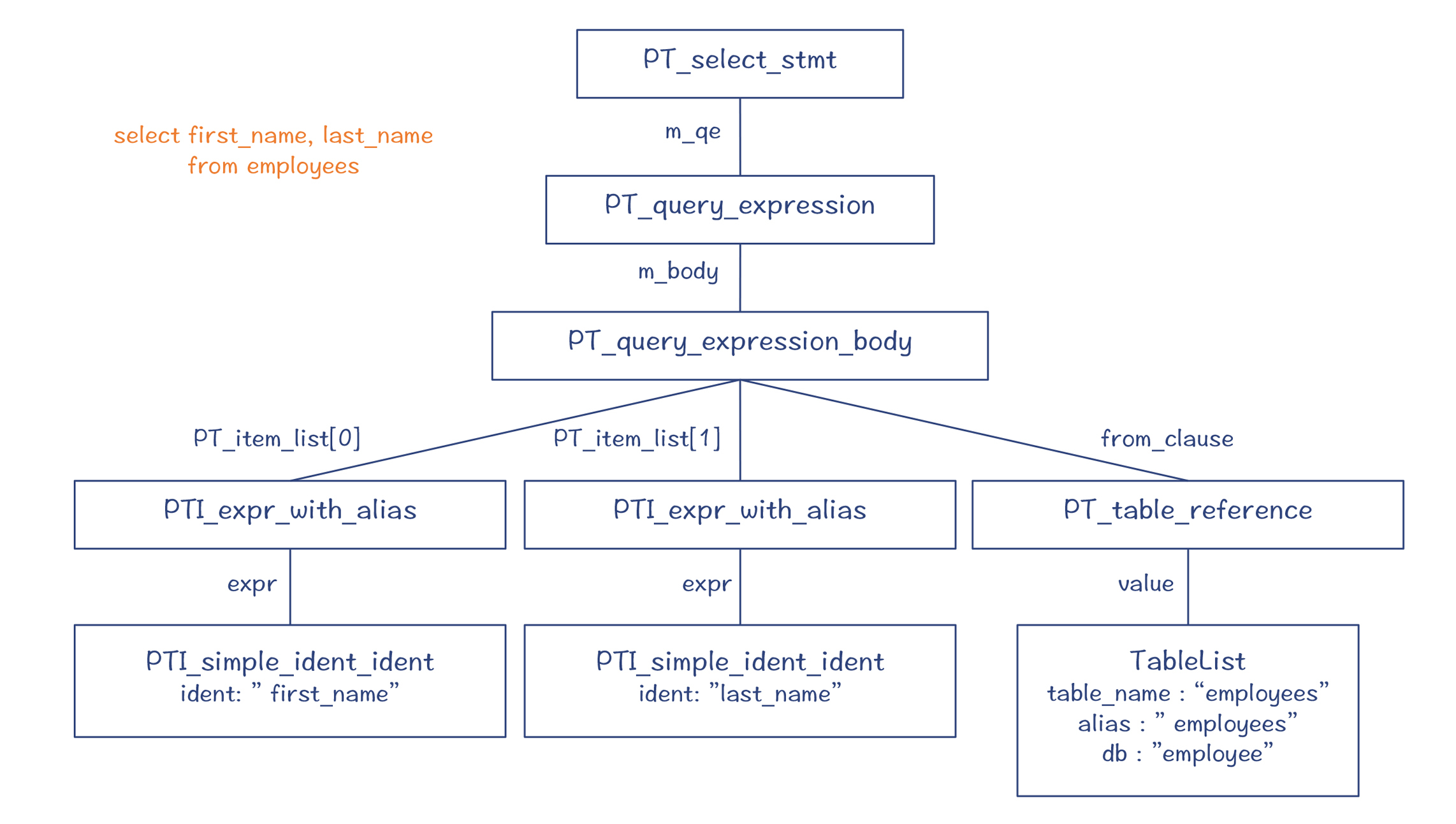
最后,对于“select first_name, last_name from employees”这样一个简单的SQL语句,它所形成的解析树如下:
而对于“select 2 + 3”这样一个做表达式计算的SQL语句,所形成的解析树如下。你会看到,它跟普通的高级语言的表达式的AST很相似:
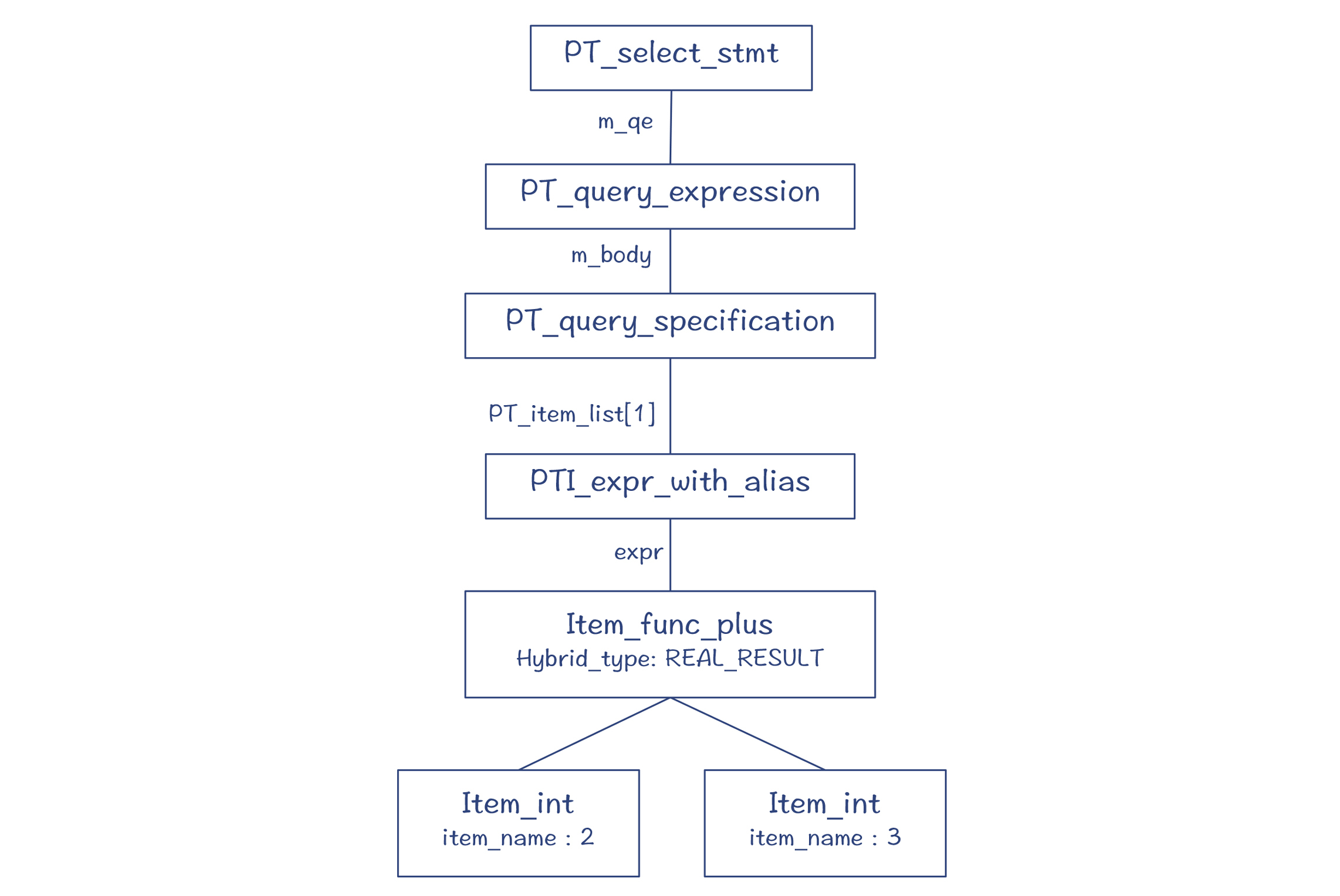
图4中的PT_query_expression等类,就是解析树的节点,它们都是Parse_tree_node的子类(PT是Parse Tree的缩写)。这些类主要定义在sql/parse_tree_nodes.h和parse_tree_items.h文件中。
其中,Item代表了与“值”有关的节点,它的子类能够用于表示字段、常量和表达式等。你可以通过Item的val_int()、val_str()等方法获取它的值。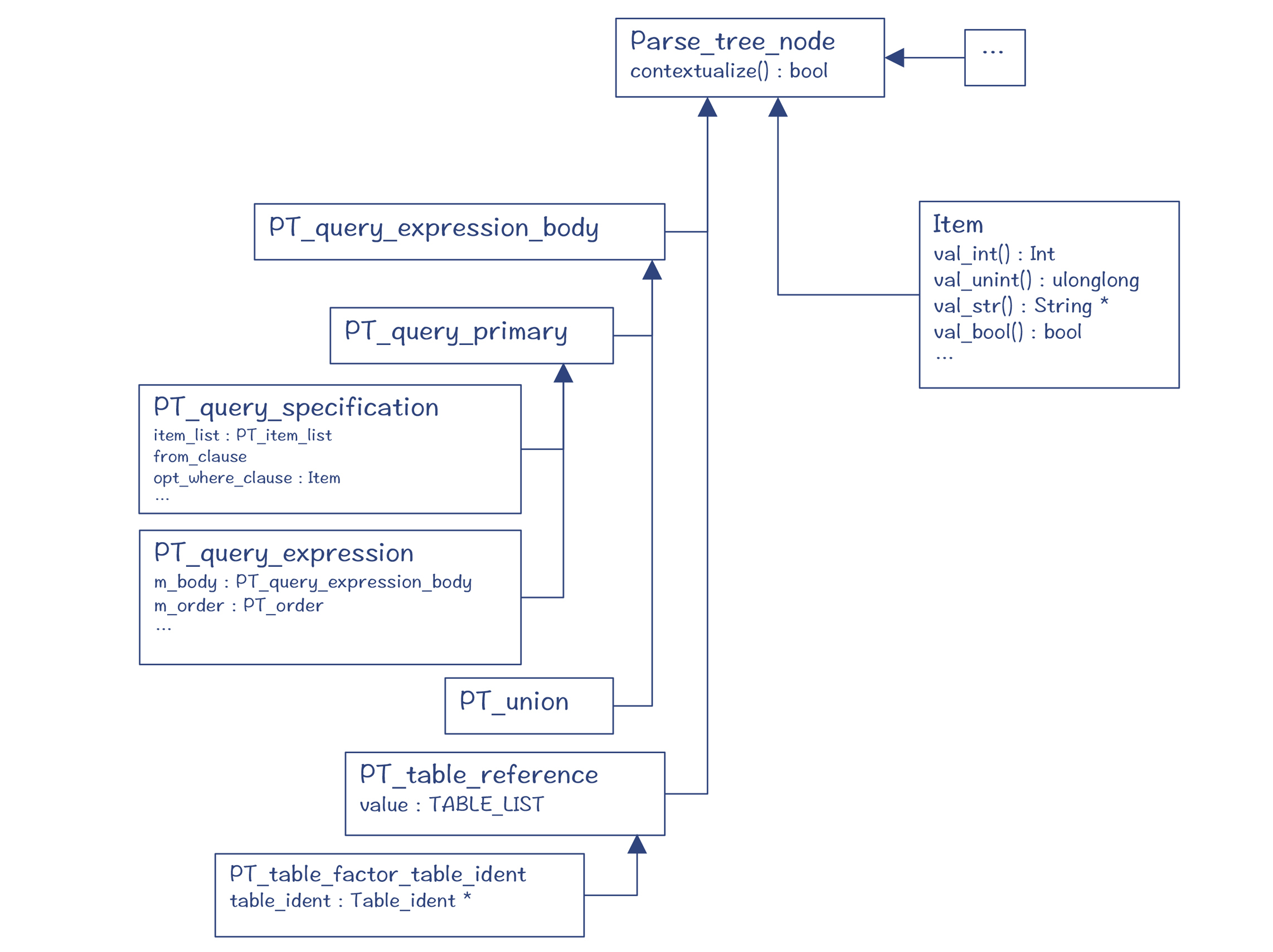
由于SQL是一个个单独的语句,所以select、insert、update等语句,它们都各自有不同的根节点,都是Parse_tree_root的子类。
好了,现在你就已经了解了SQL的解析过程和它所生成的AST了。前面我说过,MySQL采用的是LALR算法,因此我们可以借助MySQL编译器,来加深一下对LR算法家族的理解。
重温 LR 算法
你在阅读yacc.yy文件的时候,在注释里,你会发现如何跟踪语法分析器的执行过程的一些信息。
你可以用下面的命令,带上“-debug”参数,来启动MySQL服务器:
mysqld --debug="d,parser_debug"
或者
set debug = "d,parser_debug";
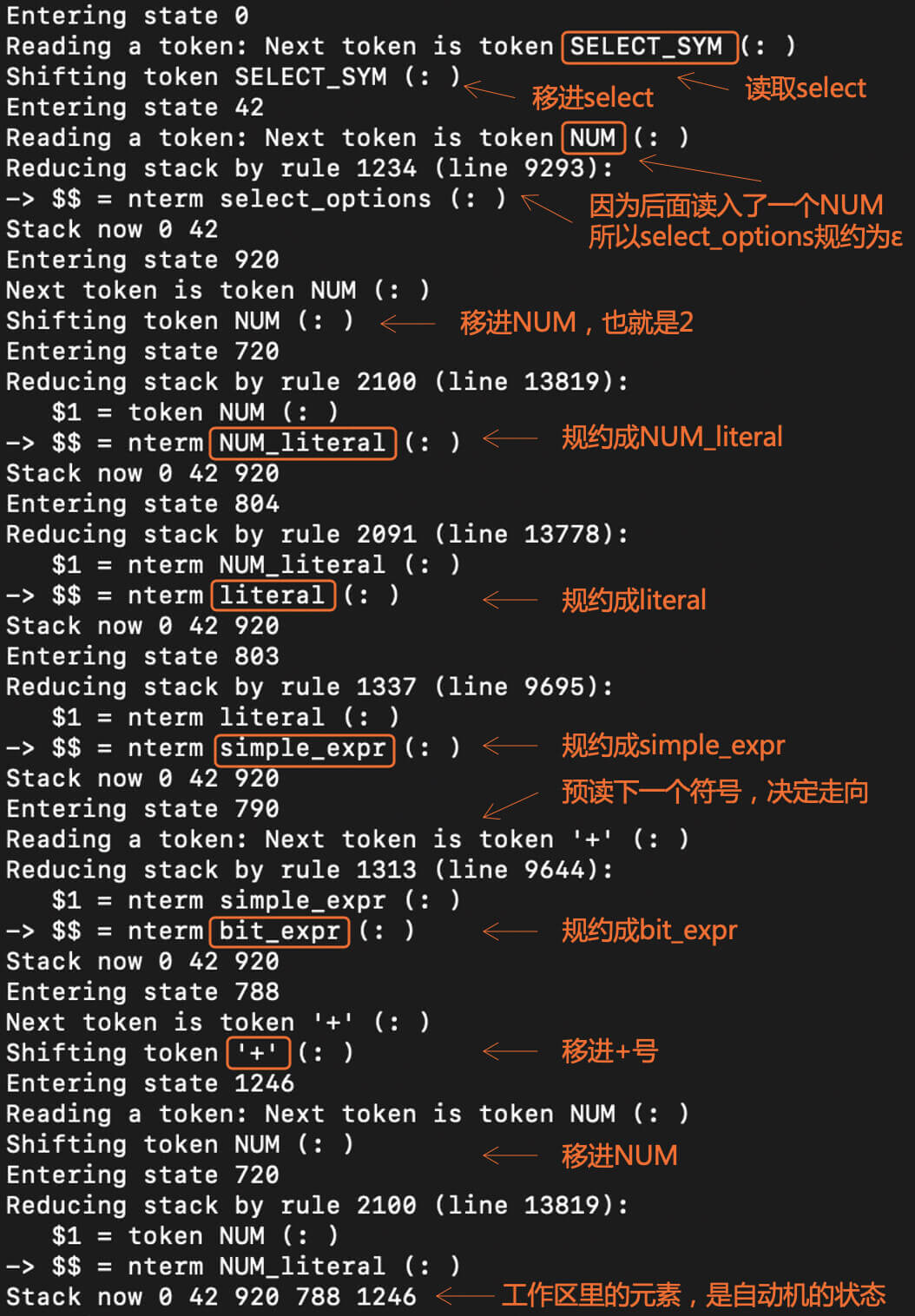
然后,你可以通过客户端执行一个简单的SQL语句:“select 2+3*5”。在MySQL 的错误日志,会输出语法分析的过程。这里我截取了一部分界面,通过这些输出信息,你能看出LR算法执行过程中的移进、规约过程,以及工作区内和预读的信息。
我来给你简单地复现一下这个解析过程。
第1步,编译器处于状态0,并且预读了一个select关键字。你已经知道,LR算法是基于一个DFA的。在这里的输出信息中,你能看到某些状态的编号达到了一千多,所以这个DFA还是比较大的。
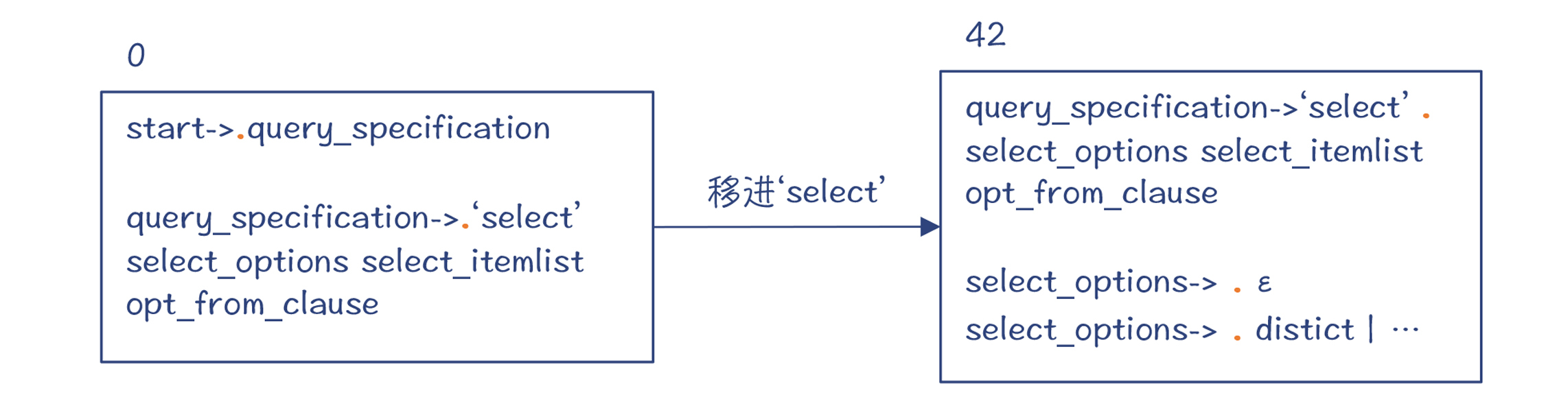
第2步,把select关键字移进工作区,并进入状态42。这个时候,编译器已经知道后面跟着的一定是一个select语句了,也就是会使用下面的语法规则:
query_specification: ... | SELECT_SYM /*select关键字*/ select_options /*distinct等选项*/ select_item_list /*select项列表*/ opt_from_clause /*可选:from子句*/ opt_where_clause /*可选:where子句*/ opt_group_clause /*可选:group子句*/ opt_having_clause /*可选:having子句*/ opt_window_clause /*可选:window子句*/ ;
为了给你一个直观的印象,这里我画了DFA的局部示意图(做了一定的简化),如下所示。你可以看到,在状态42,点符号位于“select”关键字之后、select_options之前。select_options代表了“distinct”这样的一些关键字,但也有可能为空。
第3步,因为预读到的Token是一个数字(NUM),这说明select_options产生式一定生成了一个ε,因为NUM是在select_options的Follow集合中。
这就是LALR算法的特点,它不仅会依据预读的信息来做判断,还要依据Follow集合中的元素。所以编译器做了一个规约,也就是让select_options为空。
也就是,编译器依据“select_options->ε”做了一次规约,并进入了新的状态920。注意,状态42和920从DFA的角度来看,它们是同一个大状态。而DFA中包含了多个小状态,分别代表了不同的规约情况。
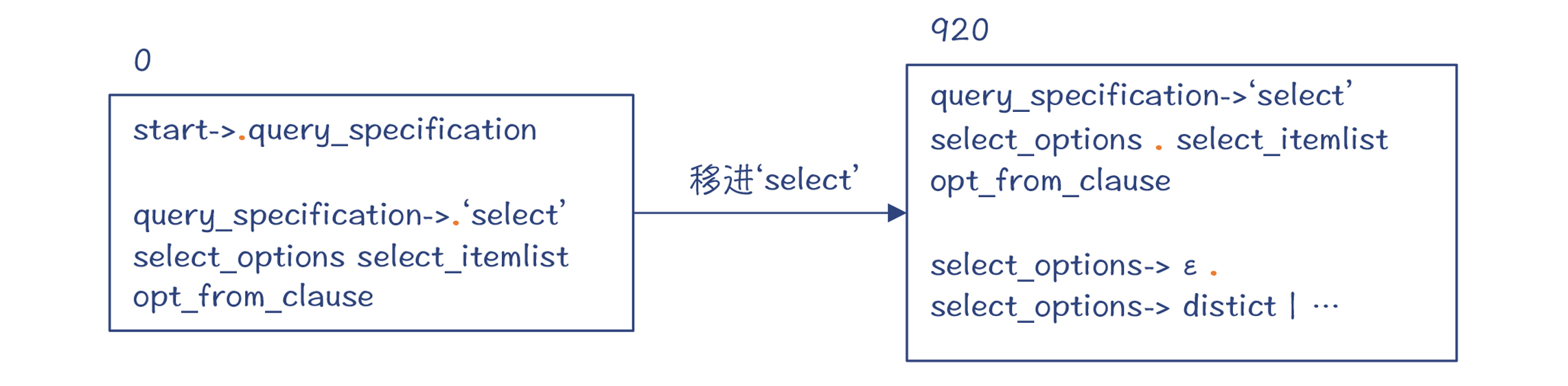
你还需要注意,这个时候,老的状态都被压到了栈里,所以栈里会有0和42两个状态。栈里的这些状态,其实记录了推导的过程,让我们知道下一步要怎样继续去做推导。

第4步,移进NUM。这时又进入一个新状态720。
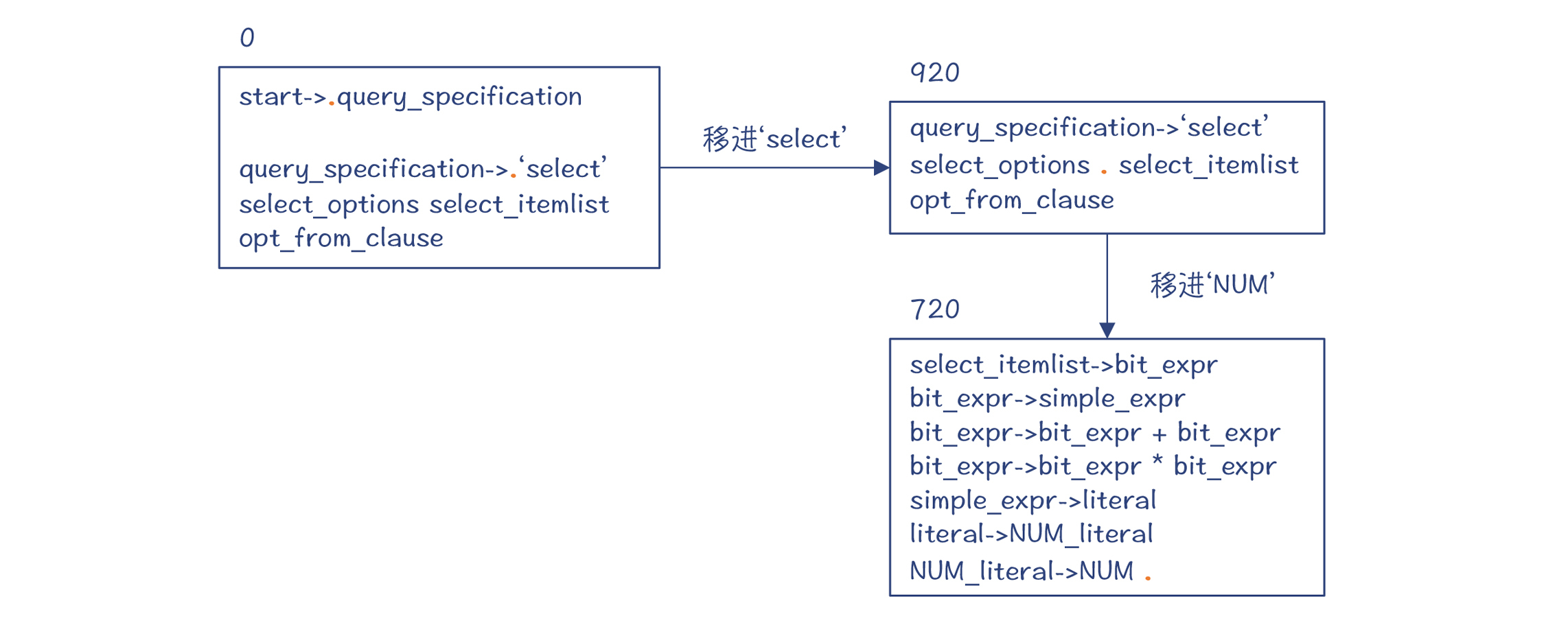
而旧的状态也会入栈,记录下推导路径:

第5~8步,依次依据NUM_literal->NUM、literal->NUM_literal、simple_expr->literal、bit_expr->simple_expr这四条产生式做规约。这时候,编译器预读的Token是+号,所以你会看到,图中的红点停在+号前。
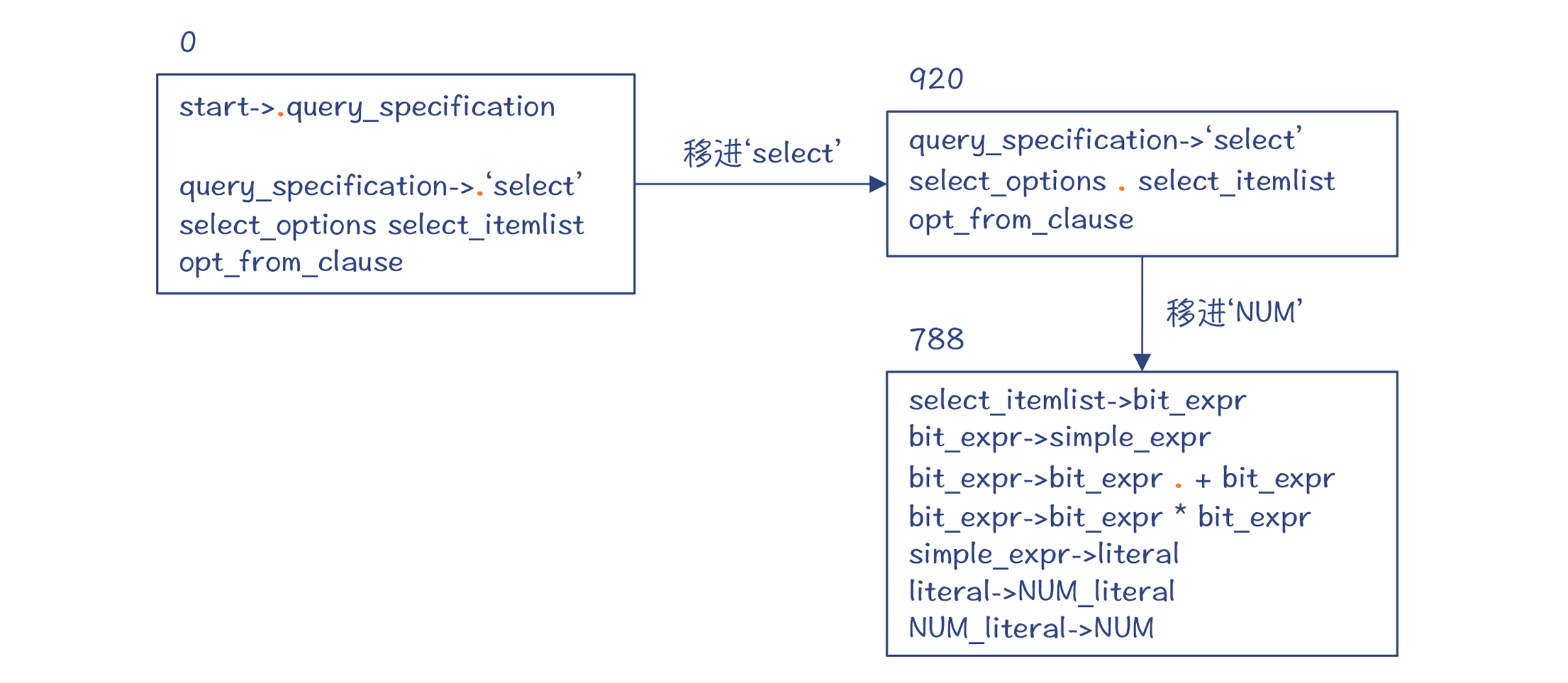
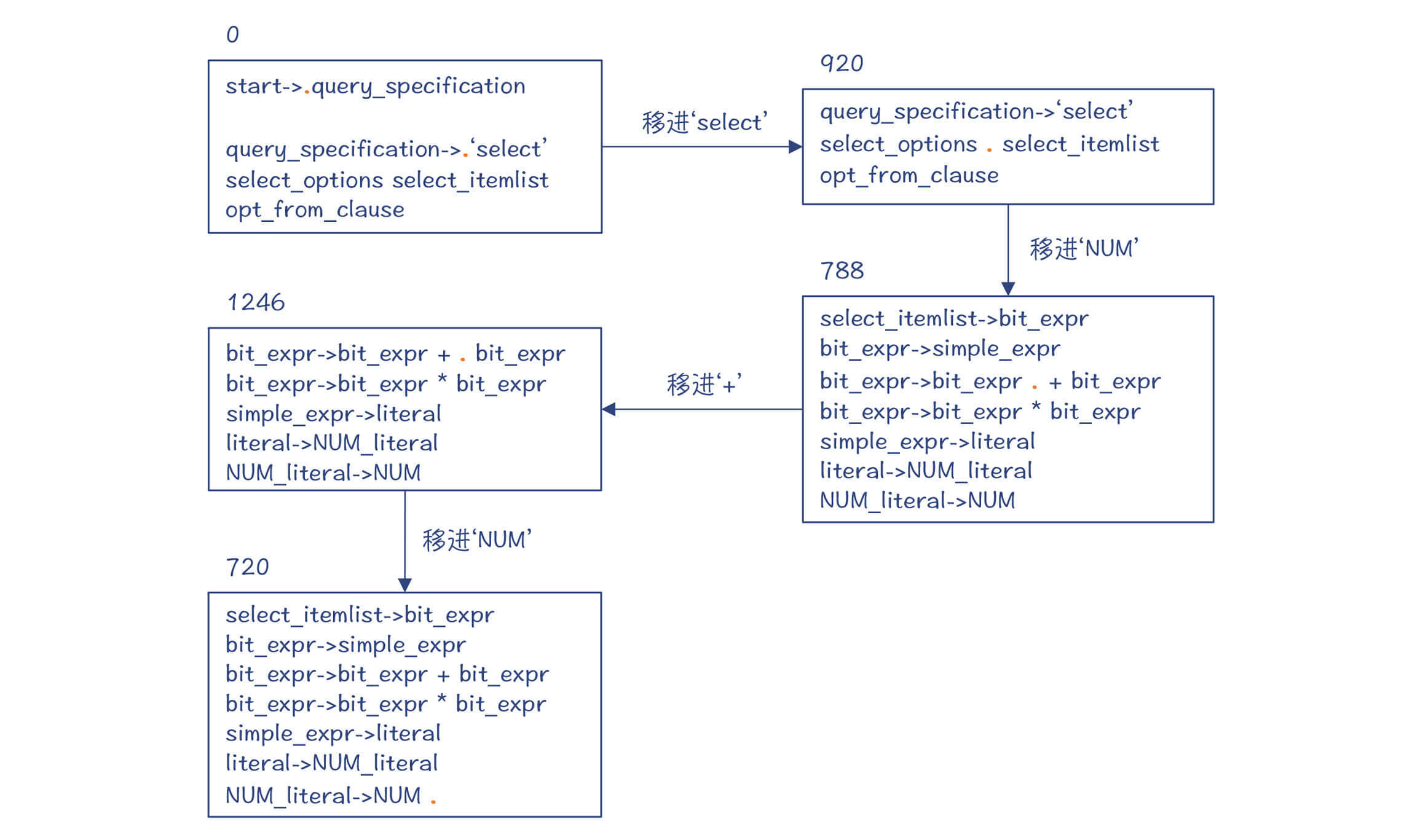
而栈里的目前有5个状态,记录了完整的推导路径。

到这里,其实你就已经了解了LR算法做移进和规约的思路了。不过你还可以继续往下研究。由于栈里保留了完整的推导路径,因此MySQL编译器最后会依次规约回来,把栈里的元素清空,并且形成一棵完整的AST。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号