
day20-继承于抽象,继承的应用,继承的实现原理,派生与方法重用,组合
温故而知新
昨天的最后我们学习了什么是继承?类分为俩种即新式类和经典类.它们的区别是什么?
即继承是一个新增类的一种方式,新建的类为子类,二被继承的类是一个父类,或者说是基类,超类
在python2中类可以分为新式类和经典类
新式类表示的是继承了object这个类的类,以及它的子子孙孙类都是新式类
经典类则表示的是没有继承object这个类的类以及它的子子孙孙类都是经典类
在python3中则都是新式类,那个没有继承任何类的类默认都会继承object类.
区别是:新式类多了一个基类object,就多了一个类的名称空间,即一个类的属性
那复习到这,其实继承还是很多的玩法,我们今天就接着讲讲我们的继承.继承具体到底是个什么玩意?它应该怎么玩?
一 继承与抽象
要找出类与类之间的继承关系,需要先抽象,再继承。抽象即总结相似之处,总结对象之间的相似之处得到类,总结类与类之间的相似之处就可以得到父类,如下图所示
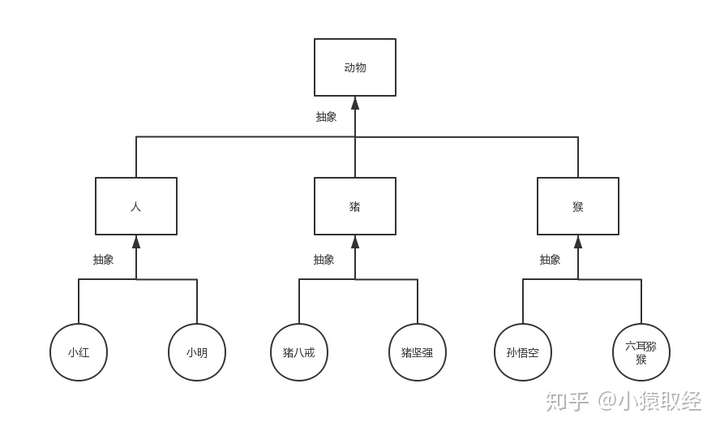
基于抽象的结果,我们就找到了继承关系
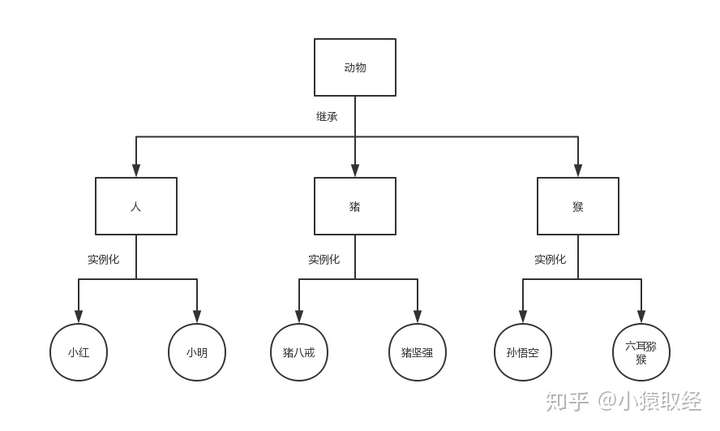
基于上图我们可以看出类与类之间的继承指的是什么’是’什么的关系(比如人类,猪类,猴类都是动物类)。子类可以继承/遗传父类所有的属性,因而继承可以用来解决类与类之间的代码重用性问题。
二 属性查找
有了继承关系,对象在查找属性时,先从对象自己的__init__中找,如果没有则去子类中找,然后再去父类中找
class Foo:
def f1(self):
print('Foo.f1')
def f2(self):
print('Foo.f2')
self.f1()
class Bar(Foo):
def f1(self):
print('Bar.f1')
obj=Bar()
print(Bar.__dict__)
#{'__module__': '__main__', 'f1': <function Bar.f1 at 0x000002C8D8ED8CA0>, '__doc__': None}
#obj.f1会先到本身 去找f1,本身有f1就返回
print(obj.f1())#Bar.f1
#obj.f2会先到本身去找f2,本身没有就去子类Bar中找,子类Bar中也没有f2,接着去
#父类Foo中找,Foo找找到f2,先打印Foo.f2,然后执行self.f1(),因为此时的self是obj
#所以会调用obj自己的f1,然后打印Bar.f1
print(obj.f2())#Foo.f2 Bar.f1
父类如果不想让子类覆盖自己的方法,可以采用双下划线开头的方式将方法设置为私有的。
class Foo:
def __f1(self): #变形为_Foo__f1
print('Foo.f1')
def f2(self):
print('Foo.f2')
self.__f1() #变形为self._Foo_f1,因而只会调用自己所在的类中的方法
class Bar(Foo):
def __f1(self): #变形为_Bar__f1
print('Bar.f1')
b=Bar()
print(b.__dict__)#{}
print(b.f2())#Foo.f2 Foo.f1 在父类中找到f2方法,进而调用b._Foo__f1()方法,同样是在父类中找到该方法
三. 继承的应用
我们都知道,继承是一个新增类的一种方式,即为了让新增的类,可以使用父类里面的功能和数据.那么我们怎么具体的在我们的类中去使用这种方式呢?
老惯例:来个需求
我们有一个简单的选课系统,需求是,学生可以选课,可以绑定校区,老师可以为学生打分,可以绑定校区
根据需求代码如下:
class Student:
school = "上海校区"
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def choose(self):
print("%s 选课成功" %self.name)
stu1 = Student("jack",18,"male")
class Teacher:
school = "上海校区"
def __init__(self,name,age,gender,level):
self.name = name
self.age = age
self.gender = gender
self.level = level
def score(self):
print("%s 正在为学生打分" %self.name)
tea2 = Teacher('lxx',38,"male",3)
我们可以发现,其中,学生和老师这俩个类里面,有很多重复的代码,比如绑定的学校是一样的,个人信息都有名字年龄性别.于是我们就可能会想到,解决代码的冗余嘛,那直接来一个函数来封装不就好了.是,可以这样想.但是我们函数只是一个功能的集合体,我们的学校这个数据怎么办呢?其实也可以,定义成一个全局的变量.再将__init__方法拿到外面
于是代码变成了这样
school = '上海校区'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student:
def __init__(self, name, age, gender):
__init__(self, name, age, gender)
def choose(self):
print('学生正在选课')
class Teacher:
def __init__(self, name, age, gender, level):
__init__(self, name, age, gender)
self.level = level
def scored(self):
print('正在给学生打分')
再实例化看看
stu1 = Student("jack",18,"male")
tea2 = Teacher('lxx',38,"male",3)
发现还是可以实现我们的需求的
但是我们可以发现随着我们公用的功能和数据越来越多,提取到全局变量会越来越多,既然是一个功能和数据的集合体,这时候我们就又可以想到,应该用我们的类来将这些功能和数据封装起来.
于是代码进一步改良,
class People:
school = '上海校区'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student:
def __init__(self, name, age, gender):
People.__init__(self, name, age, gender) # # 点名道姓的向People这个类要__init__这个方法,此时的__init__是一个普通函数,该怎么传参就怎么传
def choose(self):
print('学生正在选课')
class Teacher:
def __init__(self, name, age, gender, level):
People.__init__(self, name, age, gender) # 点名道姓的向People这个类要__init__这个方法,此时的__init__是一个普通函数,该怎么传参就怎么传
self.level = level
def scored(self):
print('正在给学生打分')
stu1 = Student('jkey', 18, 'male')
print(stu1.__dict__)
teacher1 = Teacher('egon', 18, 'male', 10)
print(teacher1.__dict__)
但是呢?这样做还是不够好,因为我们就单单是将全局名称空间变成了类的名称空间调用而已,没有把python给我们提供的操作类的原理应用上.我们可以直接将 学生类里面的__init__方法拿掉,当实例化一个学生时,在自己这找不到,就会去基类那里找__init__的方法
于是.我们代码可以进一步改良,
class People:
school = '上海校区'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def choose(self):
print('学生正在选课')
class Teacher(People):
def __init__(self, name, age, gender, level):
People.__init__(self, name, age, gender) # 点名道姓的向People这个类要__init__这个方法,此时的__init__是一个普通函数,该怎么传参就怎么传
self.level = level
def scored(self):
print('正在给学生打分')
这就是我们的第一种继承方式的应用,但这种实现,底层原理还是指名道姓去类的名称空间拿.和继承这个思想没多大关系.
那我们python有没有一个方法让我们刚好的去使用继承这个思想呢?
有的,但是,要了解这个方法,我们得知道,继承的实现原理
四. 继承的实现原理
4.1 菱形问题
大多数面向对象语言都不支持多继承,而在python中,一个子类可以同时继承对个父类,这顾然可以带来一个子类可以对多个不同父类加以重用的好处,但也有可能引发著名的菱形问题(或称钻石问题,也被称为“死亡钻石”),菱形其实就是对下面这种继承结构的形象比喻:
A类在顶部,B类和C类分别位于其下方,D类在底部将两者连接在一起形成菱形。
这种继承结构下导致的问题称之为菱形问题:如果A中又一个方法,B和C都重写了该方法,而D没有重写它,那么D继承的是哪个版本的方法,如下所示
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B,C):
pass
obj=D()
print(obj.test()) # from B
要想明白obj.test()是如何找到方法test的,需要了解python的继承实现原理
4.2继承原理
python到底是如何实现继承的呢,对于你定义的每一个类,python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下:
>>> D.mro() # 新式类内置了mro方法可以查看线性列表的内容,经典类没有该内置该方法
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>,
<class '__main__.A'>, <class 'object'>]
python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不必去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表,并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,会优先选择第一个父类
所以obj.test()的查找顺序是,先从对象obj本身的属性里找方法test,没有找到,则参照属性查找的发起者(即obj)所处的类D的MRO列表来依次检索,首先在类D中未找到,然后再B中找到方法test
ps:
1.由对象发起的属性查找,会从对象自身的属性里检索,没有则会按照对象的类.mro()规定的顺序依次找下去
2.由类发起的属性查找,会按照当前类.mro()规定的顺序依次找下去
4.3深度优先和广度优先
参照下述代码,多继承结构为非菱形结构,此时,会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序知道找到我们想要的属性。
class E:
def test(self):
print('from E')
class F:
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D:
def test(self):
print('from D')
class A(B, C, D):
# def test(self):
# print('from A')
pass
print(A.mro())
'''
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class 'object'>]
'''
obj = A()
obj.test() # 结果为:from B
# 可依次注释上述类中的方法test来进行验证
如果继承关系为菱形结构,那么经典类与新式类会有不同MRO,分别对应属性的两种查找方式,深度优先和广度优先
class G: # 在python2中,未继承object的类及其子类,都是经典类
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->G->C->F->D
# 可依次注释上述类中的方法test来进行验证,注意请在python2.x中进行测试
class G(object):
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->C->F->D->G->object
# 可依次注释上述类中的方法test来进行验证
4.4 python Mixins机制
一个子类可以同时继承多个父类,这样的设计常被人诟病,一来它有可能导致可恶的菱形问题,二来在人的世界观里继承应该是个”is-a”关系。 比如轿车类之所以可以继承交通工具类,是因为基于人的世界观,我们可以说:轿车是一个(“is-a”)交通工具,而在人的世界观里,一个物品不可能是多种不同的东西,因此多重继承在人的世界观里是说不通的,它仅仅只是代码层面的逻辑。不过有没有这种情况,一个类的确是需要继承多个类呢?
答案是有,我们还是拿交通工具来举例子:
民航飞机、直升飞机、轿车都是一个(is-a)交通工具,前两者都有一个功能是飞行fly,但是轿车没有,所以如下所示我们把飞行功能放到交通工具这个父类中是不合理的
class Vehicle: # 交通工具
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(Vehicle): # 民航飞机
pass
class Helicopter(Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车并不会飞,但按照上述继承关系,汽车也能飞了
pass
但是如果民航飞机和直升机都各自写自己的飞行fly方法,又违背了代码尽可能重用的原则(如果以后飞行工具越来越多,那会重复代码将会越来越多)。
怎么办???为了尽可能地重用代码,那就只好在定义出一个飞行器的类,然后让民航飞机和直升飞机同时继承交通工具以及飞行器两个父类,这样就出现了多重继承。这时又违背了继承必须是”is-a”关系。这个难题该怎么解决?
python提供了mixins机制,简单来说mixins机制指的是子类混合(mixin)不同类的功能,而这些类采用统一的命名规范(例如Mixin后缀),以此标识这些类只是用来混合功能的,并不是用来标识子类的从属“is -a”关系的,所以Mixins机制本质仍是多继承,但同样遵守“is - a”关系,如下:
class Vehicle: # 交通工具
pass
class FlyableMixin:
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(FlyableMixin, Vehicle): # 民航飞机
pass
class Helicopter(FlyableMixin, Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车
pass
# ps: 采用某种规范(如命名规范)来解决具体的问题是python惯用的套路
可以看到,上面的CivilAircraft、Helicopter类实现了多继承,不过它继承的第一个类我们起名为FlyableMixin,而不是Flyable,这个并不影响功能,但是会告诉后来读代码的人,这个类是一个Mixin类,表示混入(mix-in),这种命名方式就是用来明确地告诉别人(python语言惯用的手法),这个类是作为功能添加到子类中,而不是作为父类,它的作用同Java中的接口。所以从含义上理解,CivilAircraft、Helicopter类都只是一个Vehicle,而不是一个飞行器。
使用Mixin类实现多重继承要非常小心:
1.首先它必须标识某一种功能,而不是某个物品,python对于mixin类的命名方式一般以Mixin,able,ible为后缀
2,其实它必须责任单一,如果有多个功能,那就写多个Mixin类,一个类可以继承多个Mixin,为了保证遵循继承的“is -a ”原则,只能继承一个标识其归属含义的父类
3.它不依赖于子类的实现
4.子类即便没有继承Mixin类,也照样可以工作,就是缺少了某个功能。(比如飞机照样可以载客,就是不能飞了)
Mixins是从多个类中重用代码的好方法,但是需要付出相应的代价,我们定义的Minin类越多,子类的代码可读性就会越差,并且更恶心得是,在继承的层级变多时,代码的阅读者在定位某一个方法到底在何处处调用时会晕,如下:
class Displayer:
def display(self, message):
print(message)
class LoggerMixin:
def log(self, message, filename='logfile.txt'):
with open(filename, 'a') as fh:
fh.write(message)
def display(self, message):
super().display(message) # super的用法请参考下一小节
self.log(message)
class MySubClass(LoggerMixin, Displayer):
def log(self, message):
super().log(message, filename='subclasslog.txt')
obj = MySubClass()
obj.display("This string will be shown and logged in subclasslog.txt")
属性查找的发起者是obj,所以会参照MySubClass的MRO来检索属性
[<class '__main__.MySubClass'>, <class '__main__.LoggerMixin'>, <class '__main__.Displayer'>, <class 'object'>]
1、首先会去对象obj的类MySubClass找方法display,没有则去类LoggerMixin中找,找到开始执行代码
2、执行LoggerMixin的第一行代码:执行super().display(message),参照MySubClass.mro(),super会去下一个类即类Displayer中找,找到display,开始执行代码,打印消息"This string will be shown and logged in subclasslog.txt"
3、执行LoggerMixin的第二行代码:self.log(message),self是对象obj,即obj.log(message),属性查找的发起者为obj,所以会按照其类MySubClass.mro(),即MySubClass->LoggerMixin->Displayer->object的顺序查找,在MySubClass中找到方法log,开始执行super().log(message, filename=‘subclasslog.txt’),super会按照MySubClass.mro()查找下一个类,在类LoggerMixin中找到log方法开始执行,最终将日志写入文件subclasslog.txt
五 派生与方法重用
子类可以派生出自己的新属性,在进行属性查找时,子类中的属性会优先于父类被查找,例如每个老师还有职称这一属性,我们就需要在Teacher类中定义该类自己的__init__覆盖父类的
>>> class People:
... school='清华大学'
...
... def __init__(self,name,sex,age):
... self.name=name
... self.sex=sex
... self.age=age
...
>>> class Teacher(People):
... def __init__(self,name,sex,age,title): # 这一步就是派生
... self.name=name
... self.sex=sex
... self.age=age
... self.title=title
... def teach(self):
... print('%s is teaching' %self.name)
...
>>> obj=Teacher('egon','male',18,'高级讲师') # 只会找自己类中的__init__,并不会自动调用父类的
>>> obj.name,obj.sex,obj.age,obj.title
('egon','male',18,'高级讲师')
很明显子类Teacher中__init__内的前三行又是在写重复代码,若想在子类派生出的方法内重用父类的功能,有两种实现方式
方法一:“指名道姓”的调用某一个类的函数(前面有具体讲解)
>>> class Teacher(People):
... def __init__(self,name,sex,age,title):
... People.__init__(self,name,age,sex) #调用的是函数,因而需要传入self
... self.title=title
... def teach(self):
... print('%s is teaching' %self.name)
方法二: super()
调用super()会得到一个特殊对象,该对象专门用来引用父类的属性,且严格按照MRO的顺序向后查找
>>> class Teacher(People):
... def __init__(self,name,sex,age,title):
... super().__init__(name,age,sex) #调用的是绑定方法,自动传入self
... self.title=title
... def teach(self):
... print('%s is teaching' %self.name)
提示:在Python2中super的使用需要完整地写成super(自己的类名,self) ,而在python3中可以简写为super()。
这两种方式的区别是:方式一是跟继承没有关系的,而方式二的super()是依赖于继承的,并且即使没有直接继承关系的,super()仍然会按照该MRO继续往后查找
>>> #A没有继承B
... class A:
... def test(self):
... super().test()
...
>>> class B:
... def test(self):
... print('from B')
...
>>> class C(A,B):
... pass
...
>>> C.mro() # 在代码层面A并不是B的子类,但从MRO列表来看,属性查找时,就是按照顺序C->A->B->object,B就相当于A的“父类”
[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>,<class ‘object'>]
>>> obj=C()
>>> obj.test() # 属性查找的发起者是类C的对象obj,所以中途发生的属性查找都是参照C.mro()
from B
obj.teat()首先找到A下的test方法,执行super().test()会基于MRO列表(以C.mro()为准),当前所处的位置继续往后查找(),然后在B中找到了test方法并执行。
关于在子类中重用父类功能的这两种方式,使用任何一种都可以,但是,在最新的代码中还是推荐使用super()
六 组合
提一嘴:组合在做项目的时候,存数据和取数据都特别好用.
在一个类中以另外一个类的对象作为数据属性,称为类的组合。组合与继承都是用来解决代码的重用性问题,不同的是:继承是一种“是”的关系,比如老师是人,学生是人,当类之间有很多相同之处,应该使用继承;而组合则是一种“用”的关系,比如老师有生日,老师有许多课程,当类之间有显著的不同,并且较小的类时较大的类所需要的组件是,应该使用组合,如下实例;
class Course:
def __init__(self, name, period, price):
self.name = name
self.period = period
self.price = price
def tell_info(self):
print(f'{self.name} {self.period} {self.price}')
class Date:
def __init__(self, year, mon, day):
self.year = year
self.mon = mon
self.day = day
def tell_birth(self):
print(f'{self.year}-{self.mon}-{self.day}')
class People:
school = '清华大学'
def __init__(self, name, sex, age):
self.name = name
self.sex = sex
self.age = age
# Teacher类基于继承来重用Peaple的代码,基于组合来重用Date类和Course类的代码
class Teacher(People): # 老师是人
def __init__(self, name, sex, age, title, year, mon, day):
super().__init__(name, sex, age)
self.title = title
self.birth = Date(year, mon, day) # 老师有生日
self.courses = [] # 老师有课程,可以在实例化后,往该列表中添加Course类的对象
def teach(self):
print('%s is teaching' % self.name)
python = Course('python', '6mons', 19800)
linux = Course('Linux', '5mons', 16800)
tea1 = Teacher('egon', 'male', 18, '高级讲师', 2002, 3, 16)
# tea1 有两名课程
tea1.courses.append(python)#注意:这里是将python对象添加进列表中
tea1.courses.append(linux)
# 重用Date类功能
tea1.birth.tell_birth()
# 重用Course类功能
for obj in tea1.courses:
obj.tell_info()
此时对象tea1集对象独有的属性,teacher类中的内容,Course类中的内容于一身(都可以访问到),是一个高度整合的产物
本文大部分来自于老师的知乎,强力推荐: https://zhuanlan.zhihu.com/p/109331525

 浙公网安备 33010602011771号
浙公网安备 33010602011771号