
day13-三元表达式,生成式,递归函数,匿名函数
其实学到这,函数部分的精髓你都已经学的差不多了,那今天的内容就再讲函数的其他方法使用介绍
今天讲的内容有,三元表达式,列表生成式,字典生成式集合生成式以及生成器表达式(生成器生成式),还有递归函数和匿名函数.
别看介绍这么多.其实除了递归函数有一点难运用,其他的都是和记用法一样.
话不多说.进入今日主题
一.三元表达式
概念:其实三元表达式就是一个对流程控制if,else的优化.
语法:一元 if 二元 else 三元
其中一元指的是当if后面的条件,成立的情况下,返回的值.
二元值的就是判断的条件
三元值的就是当if后面的条件,不成立的情况下,返回的值
返回的是一元或者三元的值
例子:比较俩个数字的大小,并返回大的数字
方法1:用函数
def max2(x,y):
if x > y:
return x
else:
return y
print(max2(111,432)) # 432
方式2:用三元表达式
x = 111
y = 432
res = x if x > y else y
print(res) # 432
即三元表达式就一个结论:# 即if中间的为判断条件,左边的为条件成立返回的值,右边为条件不成立返回的值
res1 = 'yes' if x > y else 'no'
接下来就是一些生成式
生成式
列表生成式
概念:在列表内做一些表达式操作,将返回的值添加到一个新列表
语法:[i for i in range(10) if i < 6]
- 中间为for循环执行的代码体
- if 后面表示的是循环体内的一个if分支,一个条件判断,可选参数
- 最前面的i表示的是要返回的值
案例:将0-9添加到一个列表中
方式1:平常的代码
l = []
for i in range(10):
l.append(i)
print(l)
方式2:列表生成式
l1 = [i for i in range(10)]
print(l1)
案例2:将0-9中大于6的添加到一个列表中
方式1:平常的代码
l2 = []
for i in range(10):
if i < 6:
l2.append(l2)
方式2:列表生成式,如何优雅的取代了for和if
l3 = [i for i in range(10) if i < 6]
print(l3)
案例3:将列表中的元素都加上'_sb'
方式1:平常的代码
names = ['song', 'liu', 'xiong']
names1 = []
for name in names:
name = name + '_sb'
names1.append(name)
print(names1)
方式2:列表生成式
l4 = [name+"_sb" for name in names]
print(l4)
案例4:将列表中带_sb的名字打印,用列表生成式实现
names2 = ['jkey', 'liu_sb', 'song_sb']
names4 = [name for name in names2 if name.endswith("_sb")]
print(names4)
其实,你可以发现,列表生成式其实就是一个精简代码的一个内置方法.一般都是搭配for 循环使用
那列表有生成器,其他的字典,元组,和集合呢??
对他们都有对应的生成式.值得一提的是python没有元组表达式因为元组就是一个不可变的列表.
如果你想要进行表达式 ,可以使用 list 和 tuple 之间的转换
所以()在外面python就有了另外一层表达式的意思,即我们的生成器表达式
那一步步来.让我们看看字典生成器怎么用
字典生成式案例:
dict1 = {f'k_{str(i)}': i**2 for i in range(10) if i > 3}
print(dict1) # {'k_4': 16, 'k_5': 25, 'k_6': 36, 'k_7': 49, 'k_8': 64, 'k_9': 81}
还有集合生成器的使用
集合生成器案例:
set1 = {i for i in range(10) if i > 3}
print(set1) # {4, 5, 6, 7, 8, 9}
和列表生成器的玩法差不多,所以大家看一下案例,知道怎么使用就可以了
还是就是我们的生成器表达式
生成器表达式(==>生成器生成式)
也放俩个案例,来帮助大家理解吧
案例1:生成器表达式的简单使用
res = (i for i in range(3)) # 这里的()表示的就是一个生成器表达式
print(res) # 返回的类型是 生成器对象,即自定义的迭代器对象<generator object <genexpr> at 0x0000029056119CC8>
# 那下面就可以使用next方法去遍历取值了
print(next(res)) # 0
print(next(res)) # 1
print(next(res)) # 2
print(next(res)) # StopIteration
案例2:统计一个文件的字符长度
with open('a.txt', mode='rt', encoding='utf-8') as f:
# 方法1:之间将其全部读到内存.再计算其文件的长度
res = f.read()
print(len(res))
# 方法2:用for循环一行一行的计算长度,并累加
res = 0
for line in f:
res += len(line)
# 方法3:用列表生成器进行上面的方式2操作
res1 = sum([len(line) for line in f])
# 进一步,用生成器
res2 = sum((len(line) for line in f))
# 俩层括号可以简化成一个,即
res3 = sum(len(line) for line in f)
那我们用生成器的一个好处是撒?是的那就是昨天讲的,节省内存空间,即这里因为是一个迭代器对象,所以它不会像列表(可迭代对象)一样,放的是一个个的值在内存中,而是一个可以产生值的对象,来一个就产生一个,要下一个值,上一个就以及在内存中释放了.
是不是发现这些生成式很简单,只要记下怎么使用就好了.
那接下来就来一个带点难度的
递归函数
概念:在调用一个函数的内部又调用自己,所以递归调用的本质就是一个循环的过程
什么意思??循环??那我用while循环和for循环不可嘛
别着急
我们先来看看,递归函数长撒样
def func():
print("func")
func()
func()
上面就是一个简单的递归函数,即在函数体内部执行函数本身.
我们去执行看看
返回结果:
func
func
....
RecursionError: maximum recursion depth exceeded while calling a Python object
欸,它会报错是不是
那是因为我们只是让它执行了函数体本身,但是并没有结束条件啊,所以就相当于是一个死循环了.
而为何这里会报错呢?
是因为python以及为我们考虑到了,你可能会有一个死循环的函数.所以它给我们内部定义了一个可以循环的最大上限次数,一般为1000次.1000次过后则抛异常.为的就是优化内存
可以通过sys模块下的getrecursionlimit,查看最大循环次数
也可以通过setrecursionlimit来重新设置最大循环次数
即下方代码
import sys
sys.setrecursionlimit(2000) # 设置成最大次数为2000
print(sys.getrecursionlimit()) # 查看最大循环的次数(默认为1000)
所以我们递归函数有一个大前提:递归调用一定要在某一层结束
递归其实是有俩个阶段的
即回溯和递推
1、回溯:向下一层一层挖井
2、递推:向上一层一层返回
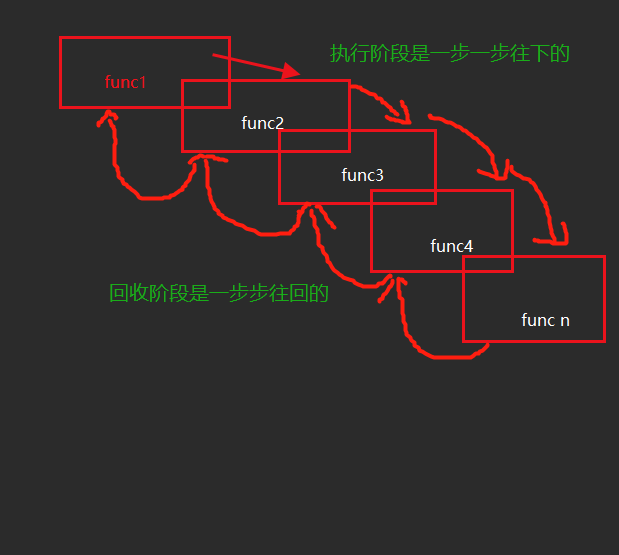
下面来俩个案例.方便大家理解
现在我有一个需求:
我去问一个人的年龄,第一个人说我的年龄是比第二个人大10岁,然后我们又去问第二个人,第二个人说:我的年龄比第三个人的年龄大10岁,然后我们又去问第三个人,第三个人说.我的年龄比第四个人的大10岁....,n次后,第n个人说我的年龄是18岁,算出第一个人的年龄
现在我们反向思维想一下,代码如下
age(n) = age(n-1) + 10
....
age(5) = age(4) + 10
age(4) = age(3) + 10
age(3) = age(2) + 10
age(2) = age(1) + 10
age(1) = 18
欸,我们看到这不就是一个循环的过程嘛?
我们是不是可以用递归函数试试?
说了就干
def age(n): # n 表示有n个人
if n == 1: # 即是我们告诉了实际年龄的那个人
return 18
return age(n-1) + 10 # 这里表示执行的循环关系
我们调用试试
res = age(5)
print(res) # 58
输出58 是不是没问题
如果这个你没理解,没关系,我们还有案例
当然这个案例,就更好的说明了递归函数使用的恰到好处
案例需求: 一个列表 nums = [1,[2,[3,[4,[5,[6,[7,]]]]]]],我们取出列表的每一个值.
我靠.这不是玩我们嘛?谁没事套这么多列表,是的,我就是玩你.来试着实现吧.
我想我们大家一开始都会想到我们熟悉的for循环,对 for 循环是可以取出来.
for循环代码
for num in l:
if type(num) is list:
for num1 in num:
if type(num) is list:
for num2 in num1:
...
else:
print(num)
我靠,这什么玩意?有几个列表我for几次???
明显这不行.
我们看看根本,我们是一个个拿到新的列表,每次都对新列表做一样的操作,但里面执行的明明是一样的,那个新列表来自的就是上一个的列表中的第二个值.
所以这时候我们想到了我们的递归函数.
代码示例:
nums = [1,[2,[3,[4,[5,[6,[7,]]]]]]]
def get(l):
for num in l:
if type(num) is list:
get(num) # 让他每一次来的都是一个新列表,这不久满足了我们的要求嘛
else:
print(num)
get(nums) # 1,2,3,4,5,6,7
递归函数还有一个用处
我们看看下面一个列表
nums = [-3,1,3,7,13,23,37,43,57,63,77,91,103]
我要看看一个数在不在这个列表里面
很简单嘛
find_num = 65
for num in nums:
if nm == find_num:
print('you got it')
break
else:
print('no exitc')
但你想想如果你查找的值在列表的前面还好,就遍历了,几次,如果是最后面呢?我们是不是要遍历很多次?而且前面的都是无效的遍历.
这时候,用我们的递归函数就有一个好处了.
我们可以拿到中间的那个值,然后再判断,要查找的这个数,和中间这个数比较,大了的话,我就再在中间这个数的右边查找,小了的话,就走这个数的左边查找.依次类推,是不是就很大程度上加快了查询,这就是我们传说中的二分法
来我们用代码实现:
二分法
nums = [-3,1,3,7,13,23,37,43,57,63,77,91,103]
find_num = 64
def find(nums,find_num):
print(nums)
if len(nums) == 0: # 当这个列表被分为空了还没找到,那说明这个要查找的数不在这个列表中
print("not exists")
return # 就不会往下执行了,解决了如果列表为空,还根据索引1取值的异常
mid_index = len(nums) // 2 # 拿到列表的中间索引
if find_num > nums[mid_index]:
# in the right
find(nums[mid_index+1:],find_num)
elif find_num < nums[mid_index]:
# in the left
find(nums[:mid_index], find_num)
else:
print('you got it')
find(nums,find_num)
这个递归函数是不是很有意思.
接下来,还有更有意思的.
我们之前用的函数是不是都带一个名称的.例如 def func():pass 其中的func就是这个函数的名字.那我们是不是也可以有没有名称的函数呢?是的,它就是我们的匿名函数
匿名函数 lambda
概念:一个没有名字的函数,功能却和函数一样
语法: lambda x,y:x + 2 * y
- lambda 后面的 x,y 表示的是匿名函数的参数,
:后面的表示的是函数的返回值
特点:用于临时用一次的
使用场景:一般搭配内置的函数使用.
下面是匿名函数的俩种之间使用的案例:
方法1:看完就忘(因为这样用我还不如用有名函数)
d = lambda x,y:x + 2*y
print(d) # <function <lambda> at 0x000001CA0CBB7F78>
res = d(1,2)
print(res) # 5
方法2:可以这样用,但可读性差
res = (lambda x,y:x + 2 * y)(1,2)
print(res) # 5
所以还是之间来和我们的新朋友,几个内置函数一起来玩吧
那就边写案例,边介绍吧
案例1:下方有一个员工工资字典,我们根据工资的多少,分别将工资最高的和最低的员工姓名,以及给他们
按照多到少,少到多的员工信息
salaries = {
"egon": 3000,
"tom": 10000,
'zxx': 1000
}
取出最高的,这里先介绍一下,max()这个内置函数的作用
max函数
功能:返回一个可迭代的对象的最大值
语法: max(iteration, [key=func])
- 其中iteration表示的是可迭代对象
- key=func,可选参数,表示按照什么依旧来返回最大值
- func为一个函数内存地址
来加到我们的案例中
def func(k):
return salaries[k] # 依据是字典的value即薪资
print(max(salaries, key=func)) # 返回的是tom
我们再将函数变为匿名函数试试
print(max(salaries, key=lambda k: salaries[k])) # 是等同于 print(max(salaries, key=func))
ok,完成了需求1,返回最大薪资的员工姓名
需求2:返回薪资最低的员工姓名
先介绍min函数
和max函数的使用方法一样,但是它的功能是返回一个可迭代的对象的最小值
语法: max(iteration, [key=func])
- 其中iteration表示的是可迭代对象
- key=func,可选参数,表示按照什么依旧来返回最大值
- func为一个函数内存地址
加到我们案例中
print(min(salaries, key=lambda k: salaries[k]))
需求2也满足了
需求3和需求4,返回他们的顺序,即从低到高和从高到低
函数sorted
功能:返回一个排序后的可迭代对象
语法:max(iteration, [key=func],[reverse=False])
- 其中iteration表示的是可迭代对象
- key=func,可选参数,表示按照什么依旧来返回最大值
- func为一个函数内存地址
- reverse=False,表示默认的以升序排序
放到案例中
print(sorted(salaries, key=lambda k: salaries[k])) # ['zxx', 'egon', 'tom']
print(sorted(salaries, key=lambda k: salaries[k], reverse=True)) # ['tom', 'egon', 'zxx']
ok,需求都完善了
其他内置函数
下面还有一些其他内置函数的玩法.大家可以试着敲敲看看
# map
res = list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])) # map()返回的是 <map object at 0x00000227FF6FEBC8>
print(res)
names = ["lxx", 'hxx', "wxx", 'lili']
# 规则
# "lxx_sb","hxx_sb"
l = (name + "_sb" for name in names)
res = map(lambda name:name + "_sb",names)
print(list(res))
# filter # 过滤出某个元素
names = ["lxx_sb",'egon',"wxx_sb",'lili_sb']
print([name for name in names if name.endswith('sb')])
res = filter(lambda name:name.endswith('sb'),names)
print(list(res))
# reduce # 拼接元素
from functools import reduce
res = reduce(lambda x,y:x+y,[1,2,3])
res = reduce(lambda x,y:x+y,["aa","bb","cc"])
print(res)
res = pow(10,2,3) # 等同于 10 ** 2 % 3
print(res)
最后给大家来介绍一下什么是面向过程编程
面向过程编程:
核心是"过程"二字,过程就是解决问题的步骤.即先干啥,再干啥,后干啥
所以基于该思想编写程序就好比设计一条一条的流水线
优点:复杂的问题流程化,将一个大问题变成了一个个的小问题,进而就实现了简单化
缺点:牵一发而动全身,扩展性差
总结:
1.三元表达式 xxx if xxx else xxx 第一个xxx 为第二个xxx成立时返回的结果,第三个xxx表示的是第二个xxx不成立时返回的结果
2.生成式:[i for i in range(10) if i > 5] 这样一个模板实例
3.递归函数:在函数内调用函数本身,一定要有结束条件,才有意义.
4.匿名函数:lambda , lambda x,y:x+y,:前的为参数,后面的为返回值
5.一些内置方法
max()返回最大值
min()返回最小值
sorted()默认升序返回,当参数reverse=True时,为降序返回
以上内置都有key=func的参数可选 表示的比较的依据,func为一个函数内存地址
map() 映射,改变可迭代对象的值
filter() 过滤
reduce() 拼接元素

 浙公网安备 33010602011771号
浙公网安备 33010602011771号