

对莫烦第一个强化学习实例分析
对莫烦第一个强化学习实例分析
1 源码
链接如下所示:
小例子
2 分析
2.1 变量
N_STATES = 6 # the length of the 1 dimensional world
ACTIONS = ['left', 'right'] # available actions
EPSILON = 0.9 # greedy police
ALPHA = 0.1 # learning rate
GAMMA = 0.9 # discount factor
MAX_EPISODES = 13 # maximum episodes
FRESH_TIME = 0.3 # fresh time for one move
N_STATES:代表有多少个state,如下图所示,在这个小例子中,它代表的是冒险者(图中的O)所能到达的位置,一共有6个。
ACTIONS:冒险者所能采取的动作,即向左(left)或向右(right)。
EPSILON:贪婪度,实际上这是一个用来控制随机探索概率的。什么意思?就是说在每次选择动作之前,都会获得一个随机的概率(这个概率大于0小于1),然后程序会用它和EPSILON进行一个比较,当这个概率小于EPSILON时,采用当前state下值最大的动作(也就是我们学习到的值),否则,随机选择一个动作。
ALPHA:学习率,个人理解是确定将每次学到的值保留多少的变量,比如说这一次学到了100,但我的学习率为0.1,那么就只保留100*0.1=10
GAMMA:奖励递减值,这个值会导致离terminal越远,获得的值越小。
MAX_EPISODES:最大训练轮次。
2.2 创建一个q表
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
#print(table) # show table
return table
上面的代码主要是用pandas库来创建一个q表,q表示q_learning算法里面会用到的一个表格,它主要用来存储state-action对应值(在每个state下每个action对应的值,它代表的是状态state下采取动作action所能获得收益的预期)
上述代码创建的表格格式如下:

它的行数为state数,列数为action数,q表的大小就是action数量*state数量。在现实的一些应用中,q表可能会非常非常巨大,所以大部分强化学习其实不会用q_learning算法。
2.3 选择动作
def choose_action(state, q_table):
# This is how to choose an action
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
action_name = np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
这个函数的输入为state,q_table,输出则为action_name。
下面再来细看代码,首先是第一行
state_actions = q_table.iloc[state, :]
这一段代码的意思是取出当前q_table中的第state行,然后赋值给state_actions。
在下面的一个if...else判断句,显然就是根据随机生成的一个位于0与1之间的数,来判断是选择q_table中值较大的那个动作,还是随机选择一个动作。
2.4 获取环境反馈值
def get_env_feedback(S, A):
# This is how agent will interact with the environment
if A == 'right': # move right
if S == N_STATES - 2: # terminate
S_ = 'terminal'
R = 1
else:
S_ = S + 1
R = 0
else: # move left
R = 0
if S == 0:
S_ = S # reach the wall
else:
S_ = S - 1
return S_, R
输入值为S(state)和A(action),输出值则为S_(下个state)和R(reward),这里的下个其实理解成第n+1个比较好。
这段代码不用细讲,其实就是只有判断S到达了terminal,R才有不为0的返回值。
2.5 强化学习主循环
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
step_counter = 0
S = 0
is_terminated = False
#update_env(S, episode, step_counter)
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
q_predict = q_table.loc[S, A]
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_predict) # update
S = S_ # move to next state
#update_env(S, episode, step_counter+1)
step_counter += 1
return q_table
直接看代码
q_table = build_q_table(N_STATES, ACTIONS)
这一段就是建立一个N_STATES行,ACTION列,初始值全为0的表格,如图2所示。
for episode in range(MAX_EPISODES):
step_counter = 0
S = 0
is_terminated = False
这一段代表要训练多少轮次,并且每一轮次需要初始化的变量(注意,是每一轮次都要初始化,比如说轮次为13,那么S=0就要初始化13次)
step_counter:每一轮次探索者到达终点需要的步数
S:探索者初始位置,S=0时探索者位于一维世界最左边
is_terminated:用来判断是否到达终点的布尔值,为真时代表当前state位于终点
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
上述代表代表了每个轮次中,探索者是怎么行动,程序又是怎样更新q_table表格的。
第一行,第二行不用多说,主要就是获取A,S_,R这三个值。
q_predict = q_table.loc[S, A]
q_predict是q_table中的第S行,第A列的值
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
q_target = R # next state is terminal
is_terminated = True # terminate this episode
如果S_不是terminal,q_target则为q_table中第S_行的最大值乘上奖励递减值GAMMA再加上奖励值R;否则,q_target赋值为R,并且将is_terminated设为真值。
根据q_target的更新规则,不难发现距离terminal越远,q值便越小。
PS:q_target为实际q值,q_predict为预测q值。不管是q_predict还是q_target,两者都会不断更新。
下图是训练结束后的q_table
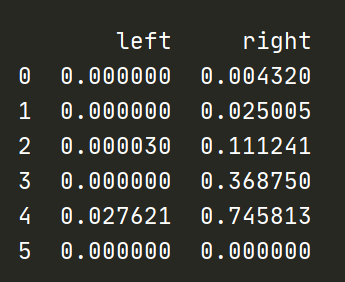
越是靠近terminal,q值就越大。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具