
如何处理千万级以上的数据
大数据处理是一个头疼的问题,特别当达不到专业DBA的技术水准时,对一些数据库方面的问题感到无赖。所以还是有必要了解一些数据库方面的技巧,当然,每个人都有自己的数据库方面的技巧,只是八仙过海,所用的武功不同而已。我把我最常用的几种方式总结来与大家分享,大家还有更多的数据库设计和优化的技巧,尽量的追加到评论中,有时一篇完整的博客评论比主题更为精彩。
方法1:采用表分区技术。
第一次听说表分区,是以前的一个oracle培训。oracle既然有表分区,就想到mssql是否有表的分区,当时我回家就google了一把,资料还是有的,在这我儿只是再作一次推广,让更多的人了解和运用这些技术。
表分区,就是将一个数据量比较大的表,用某种方法把数据从物理上分成若干个小表来存储,从逻辑来看还是一个大表。首先来个结构图:
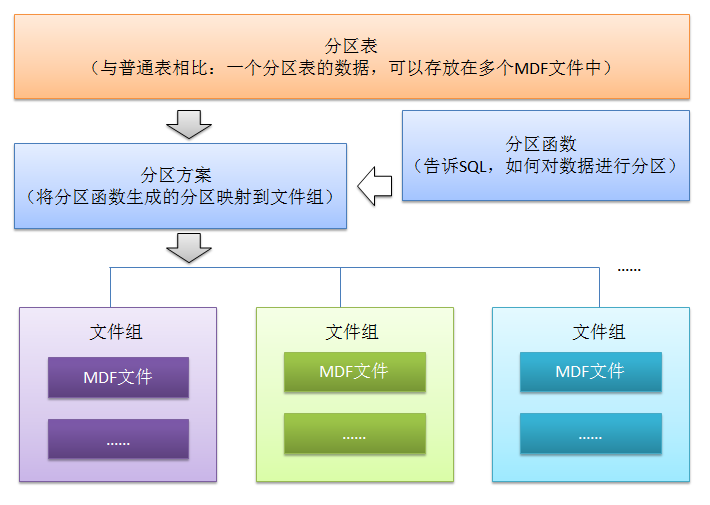
上图虽然不能很清晰的表达表分区的执行过程,但是可以看出表分区要用到那些对象,比如数据文件,文件组,分区方案,分区函数等。
我们以一个用户表(TestUser)为例,假设这个表准备用来存储中国部分公民的数据,每条数据记录着每个人所属的省份(Area),以及每个人的姓名(UserName),如下图所示。当数据量达到1千万的时候,查询就比较慢了,这时候的数据优化就迫在眉睫。

在优化之前,根据数据的结构,读写操作等,肯定会提出若干个解决方案。在这儿就以分区表的方案来优化数据库的查询,这儿以区域来分别存储数据,比如广东的公民存放在AreaFile01.MDF文件中,湖南的公民存放在AreaFile02.MDF的文件中,四川的公民存放在AreaFile03.MDF的文件中,以此类推其它省份,为了实现这个功能我们就得做分区方案。在做分区方案时,首先要搞清楚分区方案要涉及到的四个对象:文件组,文件,分区函数,分区方案。
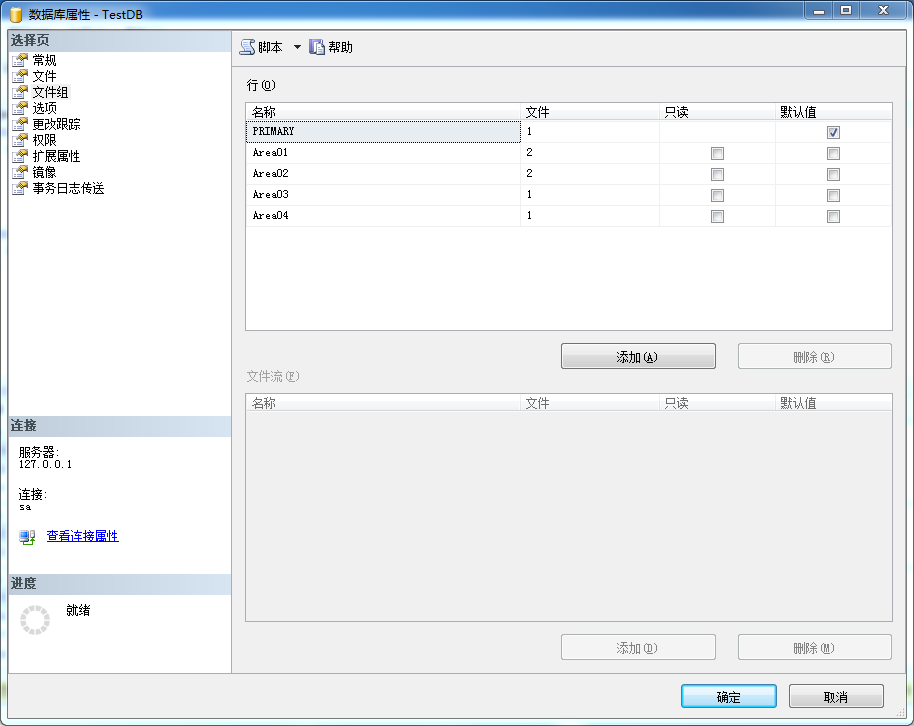
a:文件组,用来组织数据文件(.MDF)的一个虚拟名称,一个文件组可以添加多个数据文件(.MDF)。打开SQL管理器,找到具体的数据库,然后右键【属性】,进入到【文件组】选项卡,添加Area01,Area02,Area03,Area04四个文件组。如图:
b:然后选择中【文件】选项卡,添加AreaFile01,AreaFile02,AreaFile03,AreaFile04,AreaFile05,AreaFile06六个数据文件(.MDF),然后指定每个文件属于那个文件组(一个文件组可以存储多个数据文件),以及这个文件的物理路径。在这儿大家已经看明白了,这些数据文件,就是物理上来分割一个数据表的数据的。也就是说一个表的数据有可能存储在AreaFile01中,也有可能存储在AreaFile02中,只要用某种方法来指定他们的存储规则就行了。

c:分区函数,就是指定数据的存储规则。就是告诉SQL,把新增的数据如何分区。创建一个分区函数,可以用下边的SQL语句来实现。
CREATE PARTITION FUNCTION partitionFunArea (nvarchar(50))
AS RANGE Left FOR VALUES ('广东','湖南','四川')
d:辛苦的创建了文件,又为其指定文件组,还建一个分区函数,目的只有一个,就是为了创建一个分区方案。分区方案可以用以下代码来创建。

CREATE PARTITION SCHEME partitionSchemeArea
AS PARTITION partitionFunArea
TO (
Area01,
Area02,
Area03,
Area04)
经过紧张的四步操作,一个分区方案就呈现在我们的眼前了。接下来的事,就是我们要怎样来消费这个分区方案。
首先我们创建一人普通的表,然后给这个表指定一个分区方案。如下代码。
CREATE TABLE TestUser(
[Id] [int] IDENTITY(1,1) NOT NULL,
[Area] nvarchar(50),
[UserName] nvarchar(50)
) ON partitionSchemeArea([Area])
为了能看到效果,再插入一些数据。
INSERT TestUser ([Area],[UserName]) Values('四川','肖一');
INSERT TestUser ([Area],[UserName]) Values('四川','肖二');
INSERT TestUser ([Area],[UserName]) Values('四川','肖三');
INSERT TestUser ([Area],[UserName]) Values('四川','肖四');
INSERT TestUser ([Area],[UserName]) Values('广东','张一');
INSERT TestUser ([Area],[UserName]) Values('广东','张二');
INSERT TestUser ([Area],[UserName]) Values('广东','张三');
INSERT TestUser ([Area],[UserName]) Values('湖南','杨一');
INSERT TestUser ([Area],[UserName]) Values('湖南','杨二');
查询所有的数据,可以用select * from TestUser; 按分区查询:就用如下方法:
select $PARTITION.partitionFunArea([Area]) as 分区编号,count(id) as 记录数 from TestUser group by $PARTITION.partitionFunArea([Area]) select * from TestUser where $PARTITION.partitionFunArea([Area])=1 select * from TestUser where $PARTITION.partitionFunArea([Area])=2 select * from TestUser where $PARTITION.partitionFunArea([Area])=3 select * from TestUser where $PARTITION.partitionFunArea([Area])=4
效果图:
你们看我一个简单的表的分区是不是就已经完成了。呵呵,当然在实际应用中,仅仅掌握这点是不够的,比如在原分区方案上添加一个分区,删除一个分区。
方法2:用xml类型代替主从表设计,从而达到提高查询性能。
优化和提高数据库的性能,是从一个良好的数据库设计开始的。以一个会议预订系统为例,一个预订会议系统包括了会议时间,会议地点,主持人,参与人,知会人,记录者等相关信息。在的TDD,DDD模型主导的时代,在这儿为了更好的想表达我要阐述的问题,还是以表驱动模型来进行开发。
用户需求:
a:一个会议可能有多个主持人,虽然这种情况比较少,但是也有可能有。
b:一个会议有多个参与人,这个不难理解。
c:一个会议有可能要让某人知晓,这人可以参与或不参与会议,一般为高层。
d:一个会议有可能有零个或者多个记录者。
e:一个会议需要远程视频,投影仪,电脑,麦克风等会议设备中的某些设备。
f:会议预订成功,或者会议时间,会议地点等重要信息修改后,邮件通知与会人员。
常规数据库设计:
a:建一个Meeting的主表,用于存放会议名称,会议地点,会议时间等的相关信息。
b:再建一个MeetingUser的表存储主持人,参与人,知会人,记录者。
c:同样,会议所需要的设备用MeetingDevice表来存储相关的信息。如图:

这样的表结构,是比较常规的设计方法,但是在实际应用中,你会发现一些待改进的问题。比如:
a:在提取一个会议的相关信息时,会连接多个表进行查询。这种查询在很大的程序上影响了数据库性能。
b:在做修改操作时也够呛的,先修改主表的相关信息,再把主表关联的子表信息全部删除重新插入一次,这样的操作是否够吐血了。当然有人精益求精,会比较修改前和修改后的数据,再用增加,删除,修改的手段达到子表数据的更新。这样的操作在有些ORM操作中已经实现了,但当自己code代码来实现的时候,特别是在多次code的时候,感觉总是那么烦心。
吐槽了这么多,是否有更好的解决方案呢?当然,在SQL里,我们可以XML数据类型来消除主从表的设计。如图:

上面的表结构设计,是不是有一个小清新的感觉呢?很明显,可以把第一种表的设计缺陷给消除了。一个会议的相关信息都存储在了一个表的一条记录中,这样的数据看起来是不是更直观呢?
a:获取一个预订会议的详细信息,我不需要进行多个表的连接查询,我要做的是只需用C#的Linq.Xml来解析查询出来的XML字符串即可。
b:修改操作时,我只需要重新组合XML数据,一个Update就更新了与会议相关的信息,操作是不是简单多了。
表面上看这种设计已经完美了,但是用户的需求是无止境的,有一天,你收到了一个需求,查询某个用户参与过的所有会议(就是只要主持人,参与人,或者记录者中包括了这个用户,就把这些记录都给查询出来),Oh!My God 这种表结构设计应该怎么解决这个问题呢?其实可以用XQuery解决这个问题,还没接触过XQuery的那得赶快充一下电了。XQuery中最常用的有exist(),value()这些函数,这儿就不详细的介绍了,网上搜索一下有很多相关资料,如果有必要,我会把以前项目中用的XQuery技巧与大家分享。
最后,如果博客对你有帮助,我将感觉到荣幸之至。别忘记了右下角的【推荐】,谢谢!

