

4. MySQL体系结构——InnoDB存储引擎表、页结构、行记录格式
本章将重点分析表的物理存储特征,即数据在表中是如何组织存放的。也就是说,表就是关于特定实体的数据集合,这也是关系型数据库模型的核心。
4.1 索引组织表
在 InnoDB存储引擎中,表都是按照主键顺序存放的,这样的存储方式的表称为索引组织表。如果创建表时没有显式的定义主键,则按照如下方式选择或创建主键:
- 判断表中是否有非空的唯一索引(Unique NOT NULL),如果有,则该列即为主键,如果有多个非空的唯一索引,则选择第一个定义索引的作为主键。
- 如果不符合上述条件,自动创建一个6字节的指针
_rowid 用于查看单个列作为主键的情况,对于多列,无能为力。
4.2 InnoDB逻辑存储结构
从InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑的存放在一个空间中,称之为表空间。表空间由段(segment)、区(extent)、页(page/block 块)组成。

4.2.1 表空间
可以看到,InnoDB存储引擎逻辑结构的最高层,所有数据都在表空间中。默认情况下,InnoDB有一个共享表空间(ibdata1),如果启用了参数 innodb_file_per_table,则每张表的数据都可以单独放到一个表空间内。但每张表的表空间内存放的只是数据、索引和插入缓冲 bitmap页。其他类型的数据,如回滚(undo)信息、插入缓冲索引页、系统事务信息、二次写缓冲(doublewrite buffer)还在共享表空间。
InnoDB存储引擎不会再执行 rollback 时去收缩 ibdata1 这个空间。虽然 InnoDB 不会回收这个空间,但是会自动判断这些undo 信息是否还需要,如果不需要,则会将这些空间标记为可用空间,供下次undo使用。
4.2.2 段
从上图可知,表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。其中数据段即为B+树的叶子节点(Leaf Node Segment),索引段即为 B+树的非索引节点(Non-leaf node segment),回滚段后续单独介绍。
4.2.3 区
区是连续的页组成的空间,在任何情况下,都是1MB。默认情况下,InnoDB存储引擎页的大小为 16 KB,即一个区中一共有 64 个连续的页。InnoDB 1.2.x 新增了参数 innodb_page_size ,通过该参数可以将默认页的大小设置为4K,8K,但页中的数据库不是压缩,但无论页的大小怎么变化,区的大小总是1MB
用户启用了参数 innodb_file_per_table后,创建的表的默认大小是96KB,区中有64个连续的页,应该是1M才对啊?因为在每个段开始时,先用32个页大小的碎片页(fragment page)来存放数据,在使用完这些页之后才是64个连续页的申请。这样做的目的是,对一些小表,或undo这类的段,可以在开始时申请较少的空间,节省磁盘开销。
4.2.4 页
页是InnoDB磁盘管理的最小单位 ,默认一个页大小为16 KB。InnoDB 常见的页类型有:
- 数据页(B-tree Node)
- undo页(undo log page)
- 系统页(system page)
- 事务数据页(Transaction system page)
- 插入缓冲位图页(insert buffer bitmap)
- 插入缓冲空闲列表页(insert buffer Free list)
- 未压缩的二进制大对象页(Uncompressed BLOB page)
- 压缩的二进制大对象页(compressed BLOB page)
4.3 InnoDB行记录格式
InnoDB 存储引擎的记录是以行的方式存储的。InnoDB提供了 compact 和 redundant 两种格式来存放行记录数据,Redundant 格式是为了兼容之前版本而保留的。在 MySQL 5.1 中,默认设置为 Compact 格式。
4.3.1 compact 行记录格式
compact 行记录的存储方式如下所示:
compact 行记录格式的首部是一个非 NULL 的变长字段长度列表。并且是按照列的顺序逆序放置的。
第二个部分是NULL标志位,该位指示了该行数据中是否有NULL值,有则用1标识。
接下来是记录头信息(record header),固定占用5个字节,40位,每位的含义如下:
| 名称 | 大小(bit) | 描述 |
| 0 | 1 | 未知 |
| 0 | 1 | 未知 |
| deleted_flag | 1 |
该行是否被删除 |
| min_rec_flag | 1 | 为1,表示该记录是预先被定义为最小的记录 |
| n_owned | 4 |
该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该记录的排序记录 |
| record_type | 3 | 记录类型,000标识普通,001标识B+树节点指针,010标识 Infimum,011标识Supremum,1xx标识保留 |
| next_record | 16 | 页中下一条记录的相对位置 |
| total | 40 |
record header 最后两个字节是 next_record,代表下一个记录的偏移量,即当前记录的位置加上偏移量就是下条记录的起始位置。所以InnoDB存储引擎是在页内部是通过一种链表的结构来串联各个行记录的。
最后的部分就是实际每个列的数据,NULL不占用该部分任何空间,即NULL除了占用NULL标志位,实际存储不占用任何空间。另外,每行数据除了用户定义的列外,还有两个隐藏列,事务ID列和回滚指针列。若表没有定义主键,还会增加一个6字节的rowid列。
4.3.2 Redundant 行记录格式
Redundant 是 MySQL5.0 版本之前 InnoDB的行记录存储方式。存储格式如下:

不同于compact,首部是一个字段长度偏移列表,按照列的顺序逆序放置的。
第二个部分是记录头信息,不同于 compact格式,Redundant 的记录头占用6个字节,其中 n_fields 值代表一行中列的数量,占用10 位,很好的解释了为什么 MySQL数据库一行支持最多的列为 1023
| 名称 | 大小(bit) | 描述 |
| 0 | 1 | 未知 |
| 0 | 1 | 未知 |
| deleted_flag | 1 |
该行是否被删除 |
| min_rec_flag | 1 | 为1,表示该记录是预先被定义为最小的记录 |
| n_owned | 4 |
该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该记录的排序记录 |
| n_fields | 10 | 记录中列的数量 |
| 1byte_offs_flag | 1 | 偏移列表为1字节还是2个字节 |
| next_record | 16 | 页中下一条记录的相对位置 |
| total | 48 |
Redundant 格式 的 CHAR 类型的NULL值需要占用空间。
4.3.3 行溢出数据(待续……)
4.3.4 Compress 和 Dynamic 行记录格式(待续……)
4.3.5 CHAR 的行结构存储(待续……)
4.4 InnoDB数据页结构
InnoDB 数据页有以下7部分组成:
- File Header(文件头)
- Page Header(页头)
- Infimum 和 Supremum Records
- User Records(用户记录,即行记录)
- Free Space(空闲空间)
- Page Directory(页目录)

- File Trailer(文件结尾信息)
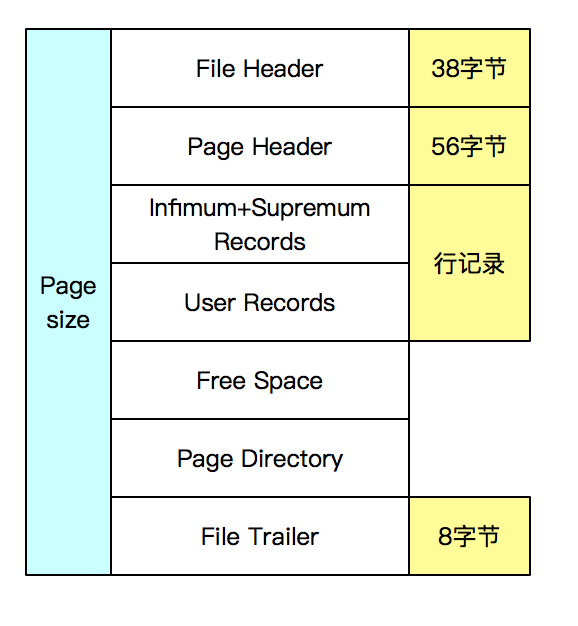
4.4.1 File Header
4.4.2 Page Header
4.4.3 Infimum 和 Supremum Record
在InnoDB存储引擎中,每个数据页中有两个虚拟的行记录,用来界定记录的边界。Infimum 是比该页中任何主键值都要小的值。Supremum 指的是比任何可能打的值还要大的值。这两个值在页创建时被建立,并且任何情况下不会删除。
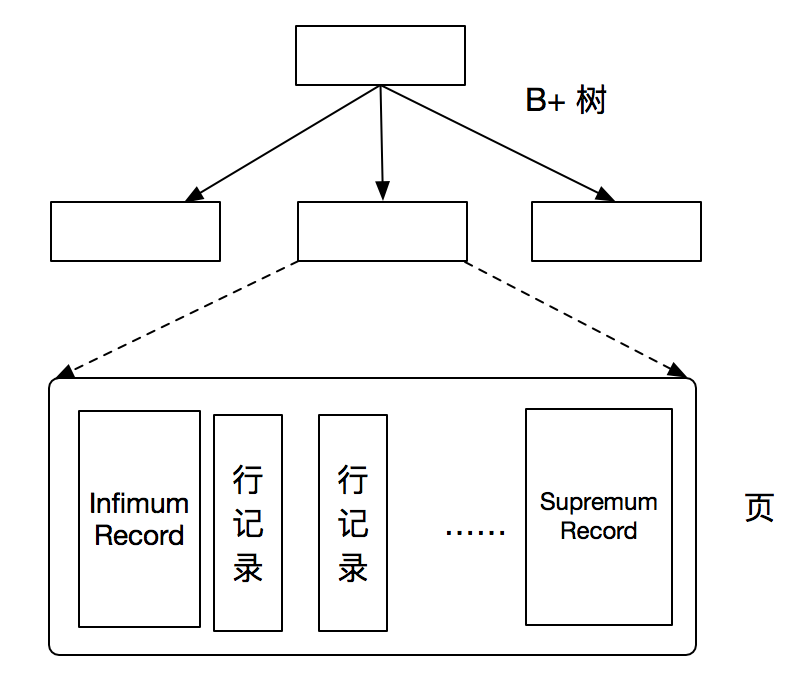
4.4.4 User Record 和 Free Record
User Record 是实际存储行记录的内容,而 Free Space 指的是空闲空间,也是个链表数据结构。在一条记录被删除后,会加入到空闲链表中。
4.4.5 Page Directory
页目录中存放了记录的相对位置,有时候,这些记录指针被称为Slots(槽)或目录槽(Directory Slots),InnoDB 存储引擎的槽是一个稀疏目录,即一个槽中有多个记录。
在 InnoDB中Page Directory 是稀疏目录,二叉查找的结果只是粗略的结果,因此 InnoDB 必须通过 record Header 中的 next_record 来继续查找相关记录。同时 Page Directory 很好的解释了 record header 中的 你_ownedzhi的含义,因为这些记录并不包含在 page Directory中
需要牢记的是,B+ 树索引本身并不能找到具体的一条记录,能找到的只是该记录所在的页。数据库把页载入内存,然后通过page Directory 再进行二叉查找。
4.4.6 File Trailer
为了检测页是否已经完整的写入磁盘(如可能发生的写入过程中的磁盘损坏,机器关机等),InnoDB的页中设置了 File Trailer 部分。
4.5 Name File Formats 机制(待续……)
4.6 约束
4.6.1 数据完整性
一般来说,数据完整性有以下三种形式:
- 实体完整性:保证表中有一个主键,用户可通过定义 Unique Key 或 Primary Key约束来保证
- 域完整性:保证数据每列的值满足特定的条件,如合适的数据类型,外键约束,编写触发器,default约束
- 参照完整性:保证两张表之间的关系,如外键或触发器
4.6.2 约束和索引的区别
当用户创建了一个唯一索引就创建了一个唯一的约束。但是约束更像是一个逻辑的概念,用来保证数据的完整性。而索引是一个数据结构,既有逻辑概念,也代表这物理存储的方式。
4.7 视图
视图是一个命名的虚表,,由一个SQL 查询来定义,可以当做表使用,视图中的数据没有实际的物理存储。视图在一定程度上起到了一个安全层的作用。
虽然视图是一个虚表,但用户可以对某些视图进行更新操作,本质就是通过视图的定义来更新基本表。
4.8 分区表(待续……)

