
大数据学习----day27----hive02------1. 分桶表以及分桶抽样查询 2. 导出数据 3.Hive数据类型 4 逐行运算查询基本语法(group by用法,原理补充) 5.case when(练习题,多表关联)6 排序
1. 分桶表以及分桶抽样查询
1.1 分桶表
对Hive(Inceptor)表分桶可以将表中记录按分桶键(某个字段对应的的值)的哈希值分散进多个文件中,这些小文件称为桶。
如要按照name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是之前所提到过的要确定合适的划分大小这个疑虑(可能某个分区的数据过大)。
分区针对的是数据的存储路径;分桶针对的是数据文件
把表或分区划分成bucket有两个理由
- 更快,桶为表加上额外结构,链接相同列划分了桶的表,可以使用map-side join更加高效。
- 取样sampling更高效。没有分区的话需要扫描整个数据集。
数据如下(student.txt)

(1)创建分桶表
create table buck_demo(id int, name string) clustered by(id) into 4 buckets row format delimited fields terminated by '\t';
(2)建一个普通的stu表
create table stu(id int, name string) row format delimited fields terminated by '\t';
(3)向普通的stu表中导入数据
load data local inpath "/root/hive/student.txt" into table buck_demo;
(4)设置分桶表的属性
set hive.enforce.bucketing=true; -- 开启分桶 set mapreduce.job.reduces=-1; -- 默认reduce个数
(5)将数据导入分桶表(不能用load直接导入,会报错)
insert into table buck_demo select id, name from stu;
(6)查看结果
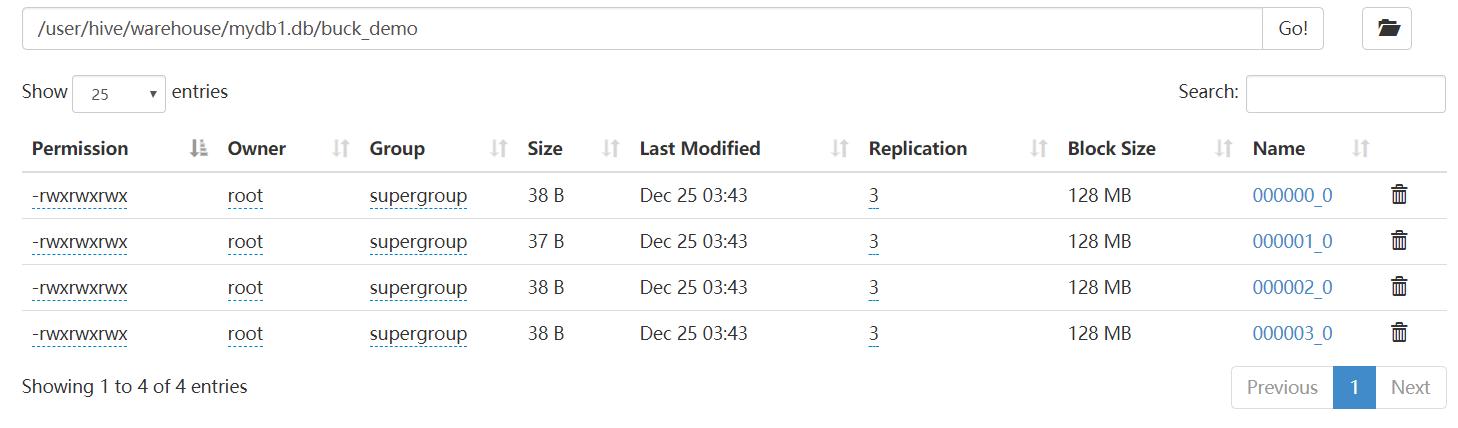
1.2 分桶抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
从大量的数据中根据某个字段的hashcode%y(样本的个数 ,桶数)获取部分样本数据,对抽样的表是没有要求的 , 分桶表普通表都可以
例:查询表buck_sku中的数据
hive (default)> select * from buck_demo tablesample(bucket 1 out of 4 on id);
注:tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y) ,其中y为数据按照字段分的份数,x为从数据中获取第几份,x<=y
查询结果:

2. 导出数据
2.1 将查询的数据导出到本地的文件夹中
insert overwrite local directory "路径" select * from tbname ;
例:将stu表中查出的数据导入/root/hive/stu中
(1)导出的数据无分割符
insert overwrite local directory "/root/hive/stu" select * from stu ;
结果

可见,导入到本地后的数据是被格式化的(无分割符)
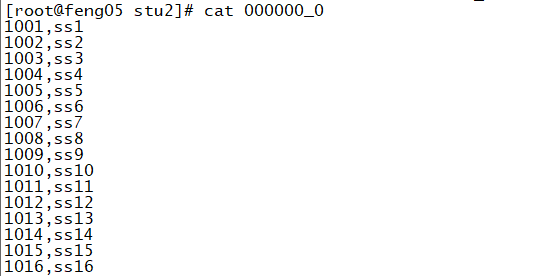
(2)导出的数据可以自定义分割符
1 insert overwrite local directory "/root/hive/stu2/" 2 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' 3 select * from stu ;
结果:
2.2 将数据导出到HDFS系统中
同2.1(只是去掉local)
2.3 直接在linux的终端执行hivesql命令的方式将数据导出数据
补充:
hive -e sql语句 hive -f sql内容的文件
例如,需求同2.1
hive -e "use mydb1;select * from stu;" > // >> /root/hive/res.txt
此处一个“>”表示覆盖导出,“>>”表示追加导出
2.4 export的形式
export 导出特殊格式 结合 inport导入使用
export table tbname to "文件夹"
3 Hive的数据类型(见文档)
3.1 基本数据类型
见文档
3.2 集合数据类型

Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套
4 逐行运算查询基本语法
4.1 select....from tb_name(省略号处的用法)
select 运算关键字 1 获取变量 2 打印常量 3 执行算术运算 4 调用函数 from 数据集 遍历每行执行一次
以查询stu表为例
select id , --表中的字段名 (遍历表中的每行数据 获取这个变量名的值 展示) name , id+1 newid1 , -- 1002.0 隐式类型转换 cast(id as int) +1 intid, -- 强制转换 1002 "hello"+name helloname ,-- null+any null concat("hello " , name) newname , -- 每行执行 "tomcat" , 1+1, current_database() -- 当前数据库 from stu ;
结果

4.2 where,group by的用法
(1) where......
where表示对表中所有原始数据的过滤,其后面可接:> >= < <= and or in like not null between and,与where对应的即是having,having表示对表中分组后的数据进行过滤
(2)group by 分组,在前面使用如下聚合函数
sum avg min max count
补充:group by 的用法和原理(https://blog.csdn.net/hengji666/article/details/54924387)
为什么不能够select * from Table group by id,为什么一定不能是*,而是某一个列或者某个列的聚合函数,group by 多个字段可以怎么去很好的理解呢?不过最后还是转过来了
=========正文开始===========
先来看下表1,表名为test:
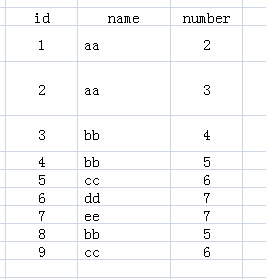
表1
执行如下SQL语句:
1 SELECT name FROM test
2 GROUP BY name
你应该很容易知道运行的结果,没错,就是下表2:

表2
可是为了能够更好的理解“group by”多个列“和”聚合函数“的应用,我建议在思考的过程中,由表1到表2的过程中,增加一个虚构的中间表:虚拟表3。下面说说如何来思考上面SQL语句执行情况:
1.FROM test:该句执行后,应该结果和表1一样,就是原来的表。
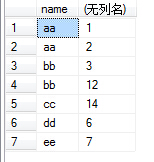
2.FROM test Group BY name:该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>与<2 aa 3>两行合并成1行,所有的id值和number值写到一个单元格里面。
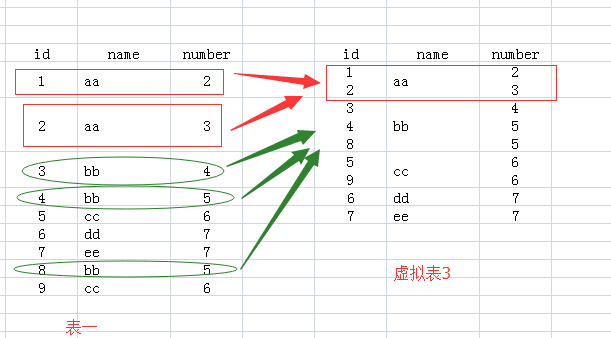
3.接下来就要针对虚拟表3执行Select语句了:
(1)如果执行select *的话,那么返回的结果应该是虚拟表3,可是id和number中有的单元格里面的内容是多个值的,而关系数据库就是基于关系的,单元格中是不允许有多个值的,所以你看,执行select * 语句就报错了。
(2)我们再看name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)那么对于id和number里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如cout(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
(4)例如我们执行select name,sum(number) from test group by name,那么sum就对虚拟表3的number列的每个单元格进行sum操作,例如对name为aa的那一行的number列执行sum操作,即2+3,返回5,最后执行结果如下:

(5)group by 多个字段该怎么理解呢:如group by name,number,我们可以把name和number 看成一个整体字段,以他们整体来进行分组的。如下图

(6)接下来就可以配合select和聚合函数进行操作了。如执行select name,sum(id) from test group by name,number,结果如下图:
例:
数据

创建表


create table groupdemo( uid string , name string , age int , gender string , address string ) row format delimited fields terminated by "," ; load data local inpath "/hive/groupdemo.txt" into table groupdemo ;
sql语句
select gender , address, count(*) num from groupdemo -- where.... group by gender , address -- having num >=2 -- 对分组后的数据进行过滤 order by num desc , address asc limit 1 , 2 -- 数字一 数据的起始行(0开始计数) 数字二是显示的行数
5. case when
案例:
数据

需求:
求出不同部门男女各多少人。结果如下:

(1)建表
create table case_demo( name string , dname string , gender string ) row format delimited fields terminated by "\t"; load data local inpath "/root/hive/case.txt" into table case_demo;
(2)初步尝试
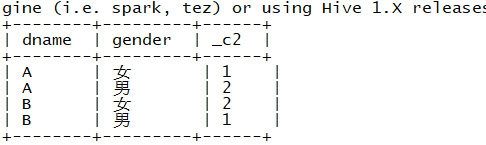
select dname , gender , count(*) // count(字段) 若字段为null 则不会统计 from case_demo group by dname , gender ;
此处的group by用法见4
(3)第一种语法
select dname , sum(case gender when "男" then 1 else 0 end) M , sum(case gender when "女" then 1 else 0 end) F from case_demo group by dname ;
结果(此案例答案)
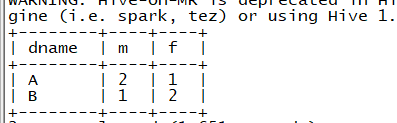
第二种语法
select * , case when dname="A" then "销售部" when dname="B" then "财务部" else "" end cname from case_demo ;
5.2 练习
有三张表,如下

准备:
建立三张表并导入相应的数据
工资表
create table gz( uid int, jb int, jj int, tc int, deptno int ) row format delimited fields terminated by ","; load data local inpath "/hive/salary.txt" into table gz;
部门表
create table bm( deptno string , name string ) row format delimited fields terminated by ","; load data local inpath "/hive/bm.txt" into table bm;
员工信息表
create table yg( uid int, name string, gender string, age int ) row format delimited fields terminated by ","; load data local inpath "/hive/yuangong.txt" into table yg;
(1)求出公司中每个员工的姓名和三类收入中最高那种收入的类型
sql语句(自己的写法)如下
select yg.name,greatest(gz.jb, gz.jj, gz.tc) max_salary, case when gz.jb == greatest(gz.jb, gz.jj, gz.tc) then "jb" when gz.jj == greatest(gz.jb, gz.jj, gz.tc) then "jj" when gz.tc == greatest(gz.jb, gz.jj, gz.tc) then "tc" else "" end category from yg join gz on gz.uid=yg.uid;
自己犯的错误:
when后面不能使用max_salary来代替greatest(gz.jb, gz.jj, gz.tc)
结果

改进:使用子查询
select yg.name, t.max_sal , t.category from yg join (select uid , greatest(jb , jj , tc) max_sal, case when jj == greatest(jb , jj , tc) then "jj" when jb == greatest(jb , jj , tc) then "jb" when tc == greatest(jb , jj , tc) then "tc" end category from gz ) t on yg.uid = t.uid;
(2)求出公司中每个岗位(部门)的薪资综合
自己犯的错:
select bm.name,sum(gz.jb+gz.jj+gz.tc) from bm join gz on bm.deptno = gz.deptno ;
sum(gz.jb+gz.jj+gz.tc)表示求选中的字段对应值的总和,其得到的时一个值,而bm.name为多个值,这样没法查询(sum一般时在分组后使用)
第一步:获取包含用户名,salary,部门编号的表
select * from bm join gz on bm.deptno = gz.deptno ;
结果

第二步:在第一步的基础上进行分组聚合
select name, sum(jb+jj+tc) total_salary from (select * from bm join gz on bm.deptno = gz.deptno) t group by name;
结果
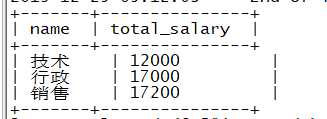
(3)求出公司中每个岗位不同性别员工薪资总和
知识补充:多表关联的两种方式(以此例为例)
// 第一种:from 表A join 表B on。。。join 表C on ... select yg.gender,gz.jj ,gz.jb,gz.tc,bm.name from gz join yg on gz.uid=yg.uid join bm on gz.deptno=bm.deptno // 第二种:from 表A join 表B join 表C on 表A与表B关联条件 and 与表C关联的条件 select yg.gender,gz.jj ,gz.jb,gz.tc,bm.name from yg join gz join bm on yg.uid = gz.uid and gz.deptno = bm.deptno
第二种关联形式一定要注意关联条件的顺序
思路:需求中存在三个表中的字段,所以先要将三张表管关联起来,然后进行分组聚合
select name,gender, sum(jb+jj+tc) total_salary from (select yg.gender,gz.jj ,gz.jb,gz.tc,bm.name from gz join yg on gz.uid=yg.uid join bm on gz.deptno=bm.deptno) t group by name,gender;
结果

(4)求出公司中不同性别、不同年龄阶段(20-30,31-40,41-50)的员工薪资总和
思路:先对表进行关联操作,获取包含性别,年龄阶段(使用case when 获取)工资的表,然后进行分组聚合
第一步:获取包含需要字段的表
select gender,age_level,gz.jb,gz.jj,gz.tc from (select gender,uid, case when age >=20 and age <=30 then "20~30" when age >=31 and age <=40 then "31~40" when age >=41 and age <=50 then "41~50" else "" end age_level from yg ) t join gz on gz.uid=t.uid
结果
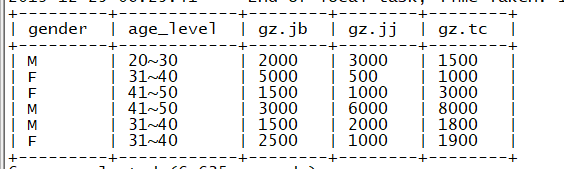
第二步:分组聚合
select gender, age_level, sum(jb+jj+tc) total_salary from (select gender,age_level,gz.jb,gz.jj,gz.tc from (select gender,uid, case when age >=20 and age <=30 then "20~30" when age >=31 and age <=40 then "31~40" when age >=41 and age <=50 then "41~50" else "" end age_level from yg ) t join gz on gz.uid=t.uid ) t1 group by gender, age_level
结果

6. 排序
order by:全局排序
sort by:每个区内排序
6.1 设置reduce的个数
set mapreduce.job.reduces=n;
查看reduce任务的个数
set mapreduce.job.reduces;
6.2 案例:以stu表为例,stu表结构如下

(1)不指定分区字段
设置reduce的个数为3(即3个分区)
sql语句:
insert overwrite local directory "/hive/stu_sort/" row format delimited fields terminated by "\t" select * from stu distribute by sname sort by sid desc ;
结果

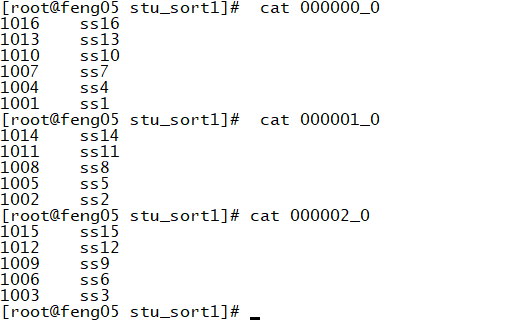
(2)指定分区字段 distribute by name(按照name的hashcode值 mod reduce任务的个数 从而得到分区数)
insert overwrite local directory "/root/hive/stu_sort1/" row format delimited fields terminated by "\t" select * from stu distribute by name sort by id desc ;
结果
(3)cluster by
当分区字段和排序字段相同时,可以直接使用cluster by 相同的字段,下面两种sql写法等价
select * from stu cluster by id; select * from emp distribute by id sort by id;
(4)小结
1 order by 全局排序 desc asc 2 sort by 区内排序 默认分区 3 distribute by 指定分区字段 结合 sort by 区内排序 4 cluster by 当 distribute by 和 sort by 是同一个字段 且升序的时候使用cluster by 替代 (只能升序)

