大数据学习day17------第三阶段-----scala05------1.Akka RPC通信案例改造和部署在多台机器上 2. 柯里化方法 3. 隐式转换 4 scala的泛型
1.Akka RPC通信案例改造和部署在多台机器上
1.1 Akka RPC通信案例的改造(主要是把一些参数不写是)
Master


package com._51doit.akka.rpc import akka.actor.{Actor, ActorRef, ActorSystem, Props} import com.typesafe.config.ConfigFactory import scala.concurrent.duration._ import scala.collection.mutable // Actor编程模型进行通信,需要让其与AKKA发生点关系(此处实现Actor特质) class Master extends Actor { // 定义一个map,用来接收数据 val id2Worker = new mutable.HashMap[String, WorkerInfo]() // 在preStart中启动定时器,定期检查超超时的Worker,然后剔除 override def preStart(): Unit = { import context.dispatcher context.system.scheduler.schedule(0 millisecond, 10000 millisecond, self, CheckTimeOutWorker) } override def receive: Receive = { // Master匹配并接收Worker发送过来的注册消息 case RegisterWorker(id, memory, cores) => { //将数据封装起来,保存到内存中 val workerInfo: WorkerInfo = new WorkerInfo(id, memory, cores) id2Worker(id) = workerInfo //向Worker反馈一个注册成功的消息 sender() ! RegisteredWorker } // Master匹配并接收Worker发送过来的心跳汇报消息 case Heartbeat(workerId) => { // 根据workId去map中查找相对应的WorkerInfo if (id2Worker.contains(workerId)) { //根据ID取出WorkerInfo val workerInfo = id2Worker(workerId) //获取当前时间 val currentTime = System.currentTimeMillis() //更新最近一次心跳时间 workerInfo.lastUpdateTime = currentTime } } // 匹配定时器发送的内容,用于提出超时的worker case CheckTimeOutWorker => { val currentTime = System.currentTimeMillis() // 取出map中的值,并计算出超时的worker val values: Iterable[WorkerInfo] = id2Worker.values val deadWorkers: Iterable[WorkerInfo] = values.filter(value => currentTime - value.lastUpdateTime > 10000) // 移除所有超时的worker deadWorkers.foreach(dw => id2Worker -= dw.id) println("current alive worker is : " + id2Worker.size) } } } object Master { val MASTER_ACTOR_SYSTEM = "MASTER_ACTOR_SYSTEM" val MASTER_ACTOR = "MASTER_ACTOR" def main(args: Array[String]): Unit = { val host = args(0) val port = args(1).toInt val configStr = s""" |akka.actor.provider = "akka.remote.RemoteActorRefProvider" // 负责通信的核心类,有必要可以自己定义 |akka.remote.netty.tcp.hostname = "$host" |akka.remote.netty.tcp.port = "$port" """.stripMargin // 此方法负责切割 val conf = ConfigFactory.parseString(configStr) val actorSystem = ActorSystem.apply(MASTER_ACTOR_SYSTEM, conf) // 通过ActorSystem对象创建Actor(通过反射指定特定类型的Actor实例) val masterActor: ActorRef = actorSystem.actorOf(Props[Master], name = MASTER_ACTOR) } }
Worker
package com._51doit.akka.rpc import java.util.UUID import akka.actor.{Actor, ActorRef, ActorSelection, ActorSystem, Props} import com.typesafe.config.ConfigFactory import scala.concurrent.duration._ /** * Worker Actor最好在构造方法执行之后,receive方法之前,向Master建立连接 */ class Worker(val masterHost: String, val masterPort: Int, val memory: Int, val cores: Int) extends Actor { var masterRef: ActorSelection = _ val WORKER_ID: String = UUID.randomUUID().toString val HEARTBEAT_INTERVAL: Int = 5000 // 生命周期方法(一定并且按一定顺序执行的方法) // 在构造方法之后,receive方法之前,执行一次preStart override def preStart(): Unit = { // Worker向Master建立网络连接,得到一个master代理对象 masterRef = context.actorSelection(s"akka.tcp://${Master.MASTER_ACTOR_SYSTEM}@$masterHost:$masterPort/user/${Master.MASTER_ACTOR}") println(s"akka.tcp://${Master.MASTER_ACTOR_SYSTEM}@masterHost:masterPort/user/${Master.MASTER_ACTOR}") // //Worker向Master发送注册的信息 masterRef ! RegisterWorker(WORKER_ID, memory, cores) } // 重写用于接收消息的方法 override def receive: Receive = { //Master反馈给Worker的消息 case RegisteredWorker => { //导入隐式转换 import context.dispatcher //启动一个定时器,定期向Master发送心跳,使用Akka框架封装的定时器 //定期给自己发送消息,然后再给Master发送心跳 //参数依次为第一次的延迟时间,多少时间执行一次,消息发送给谁(此处找不到master,发送给masterRef代理对象也不行,),发送的消息 context.system.scheduler.schedule(0 millisecond, HEARTBEAT_INTERVAL millisecond, self, SendHeartbeat) } //自己给自己发送的消息 case SendHeartbeat => { //可以进行一些逻辑判断 //向Master发送心跳消息 masterRef ! Heartbeat(WORKER_ID) } } } object Worker{ val WORKER_ACTOR_SYSTEM = "WORKER_ACTOR_SYSTEM" val WORKER_ACTOR = "WORKER_ACTOR" def main(args: Array[String]): Unit = { val masterHost = args(0) val masterPort = args(1).toInt val workerHost = args(2) val workerPort = args(3).toInt val memory = args(4).toInt val cores = args(5).toInt val configStr = s""" |akka.actor.provider = "akka.remote.RemoteActorRefProvider" // 负责通信的核心类,有必要可以自己定义 |akka.remote.netty.tcp.hostname = "$workerHost" |akka.remote.netty.tcp.port = "$workerPort" """.stripMargin // 此方法负责切割 val conf = ConfigFactory.parseString(configStr) val workerActorSystem = ActorSystem(WORKER_ACTOR_SYSTEM, conf) val workerActor: ActorRef = workerActorSystem.actorOf(Props(new Worker(masterHost,masterPort,memory,cores)), name = WORKER_ACTOR) } }
此处自己犯的错误:创建与master的连接时忘了加符号(s $), 以下是自己写的
"akka.tcp://${Master.MASTER_ACTOR_SYSTEM}@masterHost:masterPort/user/${Master.MASTER_ACTOR}"
正确的
masterRef = context.actorSelection(s"akka.tcp://${Master.MASTER_ACTOR_SYSTEM}@$masterHost:$masterPort/user/${Master.MASTER_ACTOR}")
1.2 将上述代码部署到多台机器上
1.2.1 打包
(1)第一种方法:指定main方法的形式
在pom.xml文件中指定,如下
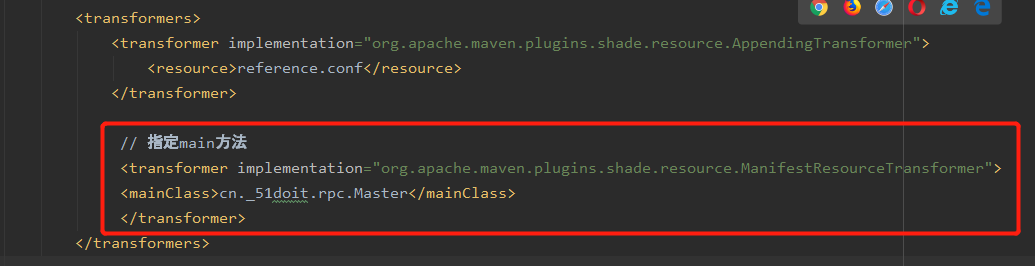
打包步骤:直接双击如下图中的package即可
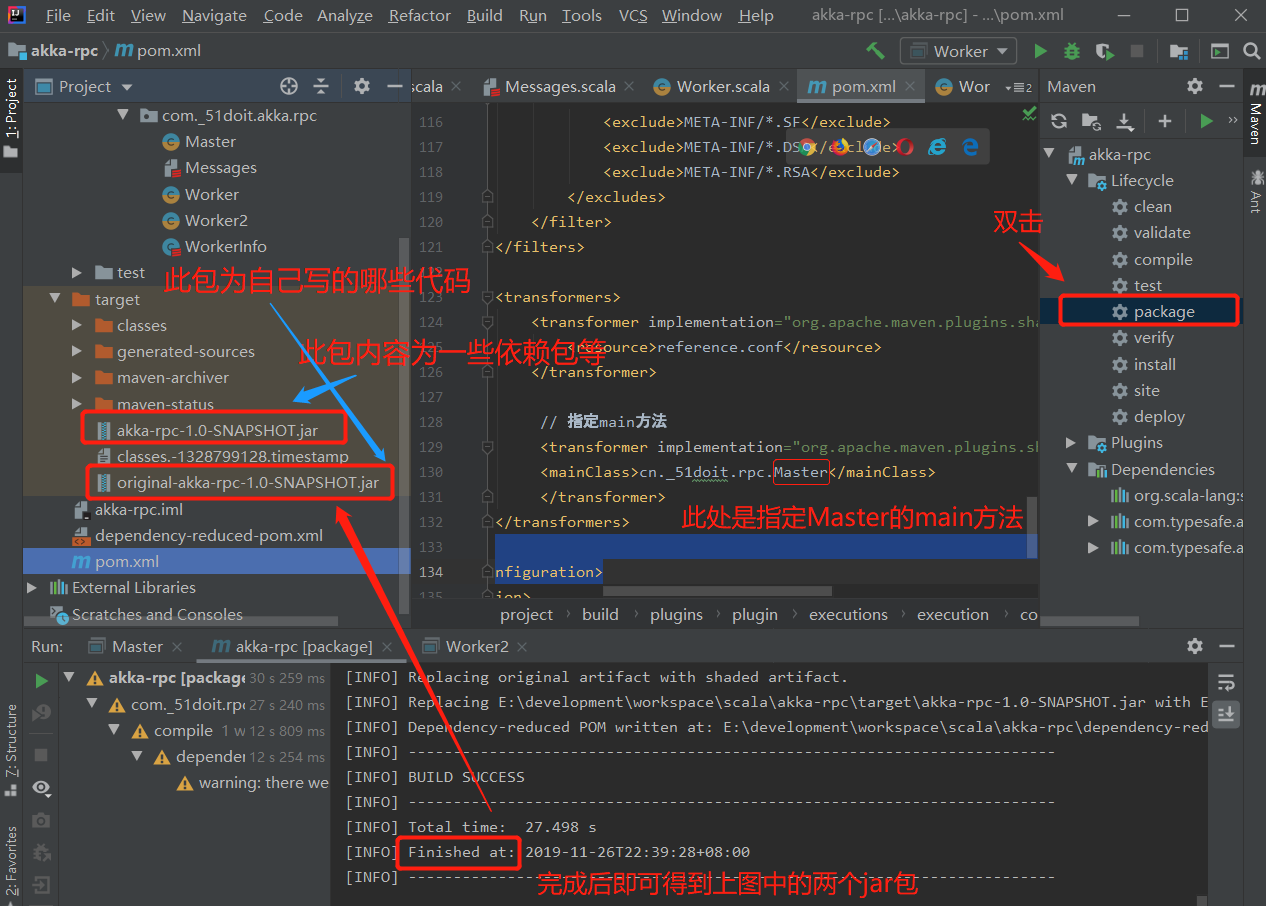
akka-rpc-1.0-SNAPSHOT.jar中是既包括了自己写的代码,也包括了需要的一些依赖包(正是我们需要的jar包),而另一个jar包只包括自己写的代码
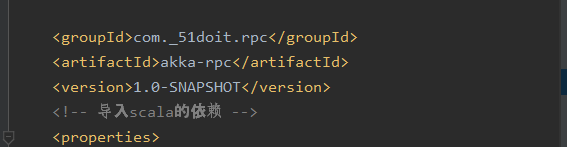
打包的包名如上表所示是pom.xml中定义了(如下图),默认是打的包为jar
由于一个面方法只能运行一次,但worker和master都要运行,所以需要将pom.xml文件中的main方法分别改为worker和master进行打包,这正是这种方法的缺点,麻烦
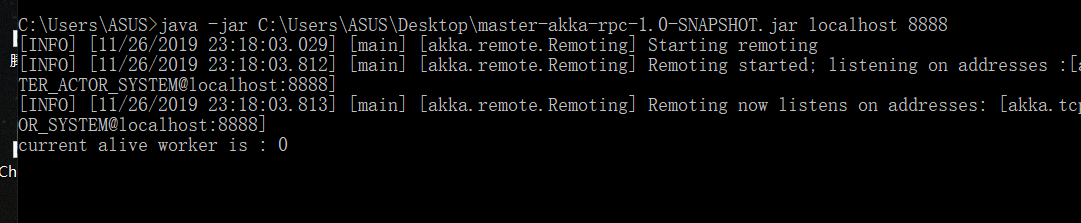
分别将jar包拖至桌面,运行命令以及结果如下
(2)第二种方法:不指定main方法的形式(pom文件中不指定main方法)
打包形式一样,只是运行的命令变了,运行命令和运行结果如下:

这样便能部署到多台机器上去(此处自己没有用多台机器,但只要ip改变下就行,)
2. 柯里化方法
定义一个方法,可以有多个括号传递参数,这样的方法叫做柯里化方法。单存的使用柯里化方法没什么意义,其是为了结合隐式转换使用的
object KeLiDemo extends App { // 正常定义方法 def m(x: Int, y: Int) = { x + y } println(m(1,2)) //柯里化方法 def kl(x: Int)(y: Int): Int ={ x + y } println(kl(1)(3)) val f = kl(8) _ // f = (y: Int) => 8+y println(f) // function1,若柯里化方法第二课括号是2个参数,则此处就为function2 }
3 隐式转换
3.1 铺垫
(1)柯里化方法使用参数的默认值的时候,这个参数一定要被implicit修饰,普通方法则不需要
object ImplicitValueDemo extends App { //定义普通的方法,传递普通的参数,可以使用,不用定义成implicit的参数 def m1(x: Int = 8): Int = { // 传递一个默认值,若没有传入参数,则方法使用默认值 x * x } //普通方法可以使用implicit修饰的默认值,但不能使用执行环境中的implicit的值(见(2)) def m2(implicit x: Int = 8): Int = { x * x } // 柯里化方法,后面的括号参数有默认值(普通默认值),不能使用 def kl(x: Int)(y: Int=8): Int ={ x + y } // 柯里化结合隐式值(被implicit修饰的参数) def kl2(x: Int)(implicit y: Int=8): Int ={ x + y } println(m1(2)) // 4 println(m2()) // 64 // 这样会报错,柯里化方法中普通的默认值不能使用 // println(kl(2)) // 报缺少参数的错 println(kl2(2)) //10 }
(2)柯里化结合隐式参数传参
scala的柯里化结合隐式参数,程序中有用implicit修饰的参数,程序执行时,会到程序的执行环境(context)中找用implicit修饰的且参数类型一致的参数,有就传递过来使用,不需要变量名一致 。如果传递参数,优先使用传递的参数,如果有implicit修饰的类型一致的参数,用该隐式值,如果还没有,用默认值
在程序中,有多个用implicit修饰的类型一致的隐式值,会出错
此例其他部分同(1)
implicit val abc: Int = 666 println(m2()) //64,说明定义的参数传不进去 println(kl2(2)) // 668,abc值被传进来了
(3)从object和class中导入隐式值
- 从object中,直接导入这个object中的属性即可
创建一个MyContext类
object MyContext { implicit val ab = 88 }
下面其他代码同(1)
import MyContext._ println(kl2(2)) // 90
- 从类中,先要new一个实例,然后再导入隐式值
MyClass
class MyClass { implicit val aa = 100 }
下面其他代码同(1)
//如果是类,先要new实例,然后在导入隐式值 val mc = new MyClass import mc.aa println(kl2(2)) //102
3.2 简介
当在scala中使用1 to 3 时,相当于1.to(3),但是Int中没有to方法,但为什么能使用呢?答案是使用了隐式转换(其可以理解为更加高级的装饰),RichInt这个类中有to方法,相当于将Int装饰成了RichInt
//int 转成了 RichInt //隐式转换,扩展了功能,功能更多,调用更方便 1 to 10 //没有使用隐式转换,使用隐式转换更加方便 new RichInt(1).to(10)
隐式转换的本质就是对类、方法的增强和扩展,其就是装饰模式的特殊表现形式。隐式转换就是在编译时,去上下文中查找相关方法或参数【类型是否一致、转换成另外的类型就有其他的方法了】
案例:给File类添加read方法
我们都知道,File类中没有读取某个文档所有内容的方法,但我们如何它添加这个方法呢?
(1)装饰者模式
正常想到的就是装饰模式和继承,但继承的话相对来讲笨重一点,并且继承一个类后就不能继承别的类了,以下是使用装饰模式
class RichFile(val file: File) { // 一次读取某个文档的所有内容 def read() : String = { Source.fromFile(file).mkString } } object RichFile { def main(args: Array[String]): Unit = { // 读取文件中的所有内容,返回一个字符串 val file = new File("E:/javafile/words.txt") val richFile = new RichFile(file) val content = richFile.read() println(content) } }
执行后能读出文档中的所有内容。但是这种包装形式用起来太麻烦,此时可以使用隐式转换
(2)隐式转换
创建一个MyContext类,并在类中创建一个将file转换成RichFile的方法
object MyContext { // 定义一个方法,将file转成RichFile // 就是事先将File包装成RichFile implicit def file2RichFile(file:File):RichFile = { new RichFile(file) } }
class RichFile(val file: File) { // 一次读取某个文档的所有内容 def read() : String = { Source.fromFile(file).mkString } } object RichFile { def main(args: Array[String]): Unit = { // 读取文件中的所有内容,返回一个字符串 val file = new File("E:/javafile/words.txt") import MyContext._ val content: String = file.read() println(content) } }
说明:程序在编译时,发现调用了file的read方法,但是file上没有read方法,scala会在程序的上下文进行查找,看有没有一个方法或者函数,可以将自身转换成另外一种类型,这个另外的类型定义了read方法(参数的个数和返回值一致)
注意:隐式转换优先使用返回相同类型的函数
object MyContext { //定义一个方法,将file转成RichFile //就是事先将Flie包装成RichFile implicit def file2RichFile(file: File): RichFile = { println("Method Invoke") new RichFile(file) } //优先使用隐式转换函数,没有找到对应的函数,在找方法 implicit val fileToRichFIle = (file: File) => { println("Function Invoke") new RichFile(file) } }
运行后会发现打印出Function Invoke
4. Scala的泛型
4.1 简介:
scala的泛型用[]表示,其分为逆变和协变
逆变: -A 方法的输入参数类型
协变: +R 方法返回值的类型
注意:scala的泛型和java的不同处在于,scala的泛型是指明了输入和输出的,java则没有
4.2 泛型的上下文界定
(1)[T <: Comparable[T]] 上界 upper bound <T extends Comparable>,相当于T实现了Comparable接口 (2)[T >: Comparable[T]] 下界 lower bound <T super Comparable> 相当于T是Comparable的父类 (3)[T <% Comparable] 视图界定 view bound 可以实现隐式转换 (4)[T : Comparable] 上下文界定 context bound
(1)[T <: Comparable[T]] 上界
class Pair[T <: Comparable[T]]{ def bigger(first: T, second: T) = { if(first.compareTo(second) > 0) first else second } } object Pair { def main(args: Array[String]): Unit = { //装的是Scala的Int val pair = new Pair[Integer] val r = pair.bigger(5, 10) print(r) } }
此处new Paire[Integer]中的Integer若改为Int则会报错,显示Int没有实现Comparable的接口,但是为什么后面调用bigger方法传的却能是Int类型的数值?====> 内部会实现Int到Integer的转换(隐式转换)
但如果要在new Paire[Integer]中写Int类型该怎么改呢?====>如下
(3)[T <% Comparable] 视图界定
视图界定就是为了实现隐式转换的,视图界定需要传入一个隐式转换方法或函数(MyPredef中),优先使用函数
此处将Int===>Intger, 因为scala默认导入Predef对象,而在这个object中有将Int转换为Integer的方法
class Pair[T <% Comparable[T]]{ def bigger(first: T, second: T): T = { if(first.compareTo(second) > 0) first else second } } object Pair { def main(args: Array[String]): Unit = { //装的是Scala的Int val pair = new Pair[Int] val r = pair.bigger(5, 10) print(r) } }
Ordered和Ordering
在scala中有两个特质Ordered、Ordering,这两个特质是专门用来作比较的。Ordered实现了Comparable接口,Ordered并且对Comparable接口进行了扩展;Ordering 实现了 Comparator接口, Ordering 对Comparator接口进行了扩展。定义这两个特质的目的就是为了进行比较时更加方便
class Pair2[T <% Ordered[T]] { def bigger(first: T, second: T): T = { if(first >= second) first else second } } object Pair2{ def main(args: Array[String]): Unit = { val p = new Pair2[Int] val r = p.bigger(5, 8) println(r) } }
此处Int先转换成了Ordering[Int](在Ordering特质中) ,Ordered中有一个隐式转方法,可以将Ordering[T] 转成 Ordered[T] ,这块源码还不怎么看的懂,以后来看
现在要比较自己定义的类,类如下
//将比较规则和类耦合在一起了,所以不用继承的方式 //class Boy(val name: String, var fv: Double) extends Comparable[Boy]{
ovverride def compareTo(o:Boy):Int={
(this.fv - o.fv).toInt
}
} class Boy(val name: String, var fv: Double){ override def toString = s"Boy($name, $fv)" }
MyPredef
object MyPredef { implicit val boy2OrderedBoy: Boy => Ordered[Boy] = (boy:Boy) => new Ordered[Boy]{ override def compare(that: Boy): Int = { (boy.fv - that.fv).toInt } } }
业务代码
class Pair2[T <% Ordered[T]] { def bigger(first: T, second: T): T = { if(first >= second) first else second } } object Pair2 { def main(args: Array[String]): Unit = { // val p = new Pair2[Int] // val r = p.bigger(5, 8) // println(r) import MyPredef.boy2OrderedBoy val p: Pair2[Boy] = new Pair2[Boy] val res: Boy = p.bigger(new Boy("老王", 99.9), new Boy("老李", 88.9)) print(res) } }
(4)[T : Comparable] 上下文界定
上下文界定,也是为了实现Scala的隐式转换的,上下文界定,需要传入一个隐式的object(MyPredef中的object)
MyProdef
object MyPredef { implicit object OrderingMan extends Ordering[Man] { override def compare(x: Man, y: Man): Int = { x.age - y.age } } }
业务代码
class Pair3[T : Ordering] { def bigger(first: T, second: T): T = { //implicitly将Ordering跟T关联在一起 val ord = implicitly[Ordering[T]] if(ord.gt(first, second)) first else second } } object Pair3 { def main(args: Array[String]): Unit = { import MyPredef.OrderingMan val p = new Pair3[Man] val r = p.bigger(new Man("laozhao", 18), new Man("laoduan", 33)) println(r) } }
4.3 使用柯里化结合隐式参数,实现隐式转化(不需要上下文界点也不需要视图界点)
写前面的代码时,其出现如下提示,这正是提示使用此方法

案例
/** * 使用柯里化结合隐式参数,实现隐式转换 */ import MyPredef._ class Pair4[T] { /** * 柯里化结合隐式参数,实现隐式转换,传入一个隐式转换函数 * 这种方式和视图界定的效果是一样的 */ def choose(first: T, second: T)(implicit ord: T => Ordered[T]): T = { if(first >= second) first else second } /** * 使用柯里化结合隐式参数,需要传入一个隐式的object * 这种方式可以实现类似上下文界定 */ def select(first: T, second: T)(implicit ord: Ordering[T]): T = { if(ord.gteq(first, second)) first else second } } object Pair4 { def main(args: Array[String]): Unit = { // val p = new Pair4[Boy] // // val r = p.choose(new Boy("laozhao", 9999.99), new Boy("laoduan", 999.99)) // // println(r) val p = new Pair4[Man] val r = p.select(new Man("laozhao", 18), new Man("laodaun", 33)) println(r) } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号