
大数据学习day10-----zookeeper--------1.小文件合并,2 输入和输出 3 多路径输出 4.zookeeper(选举机制,安装,zk的shell客户端、java客户端)
1. 小文件合并
HDFS中不适合存储大量的小文件,原因如下;
- 无论文件大小,namenode记录的元数据大小几乎是一致的(1KB的文件与120M的文件在namenode中的元数据都是一样的)
- namenode的内存有限,记录的元数据条数有限,集群的存储容量受限,所以HDFS不能无限添加datanode扩容
- 增加namenode管理元数据的压力
- MR程序默认的是使用TextInputFormat类,计算任务的时候是以文件数量为基准的,大量的小文件会启动大量的maptask,而maptask内部处理数据是比较复杂的,这会降低处理数据的效率
所以
尽量别在hdfs上存储小文件,如果有大量的小文件产生,最好将小文件合并以后再上传
假如小文件真存储在了HDFS中,这是需要避免处理数据时大量maptask的产生
案例:
将E:\wc\filemerge\input中的所有文件中的内容读取到一个文件中,文件中内容的格式为文件名:内容
A. 默认设置(产生多个map任务(文件的个数)处理的情况),代码如下:


public class Merge1 { static class MergeMapper extends Mapper<LongWritable, Text, Text,Text >{ // 获取文件名 String fileName = null; @Override protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { FileSplit fs = (FileSplit)context.getInputSplit(); fileName = fs.getPath().getName(); } // 处理每行数据 StringBuilder sb = new StringBuilder(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { String line = value.toString(); sb.append(line+" "); } // 将数据以filename为key,文件内容为value写出 @Override protected void cleanup(Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { context.write(new Text(fileName), new Text(sb.toString().trim())); } } static class MergeReducer extends Reducer<Text, Text, Text, NullWritable>{ @Override protected void reduce(Text key, Iterable<Text> iters, Reducer<Text, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { String fileName = key.toString(); Text next = iters.iterator().next(); // 迭代器中只有一条数据 String content = next.toString(); context.write(new Text(fileName+":"+content), NullWritable.get()); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setMapperClass(MergeMapper.class); job.setReducerClass(MergeReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 输出好输入的数据路径 FileInputFormat.setInputPaths(job, new Path("E:/wc/filemerge/input/")); FileOutputFormat.setOutputPath(job, new Path("E:/wc/filemerge/output1/")); // true 执行成功 boolean b = job.waitForCompletion(true); // 退出程序的状态码 404 200 500 System.exit(b ? 0 : -1); } }
此处的代码需要注意的点:
(1)StringBuilder的使用(节省资源,若直接使用String会在常量池创建多个空间)

(2)迭代器中只有一个值时,直接获取值,不需要遍历
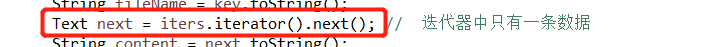
运行部分结果如下:
B. 比较少mapTask个数的情况(此种情况不能得到文件名)
代码如下
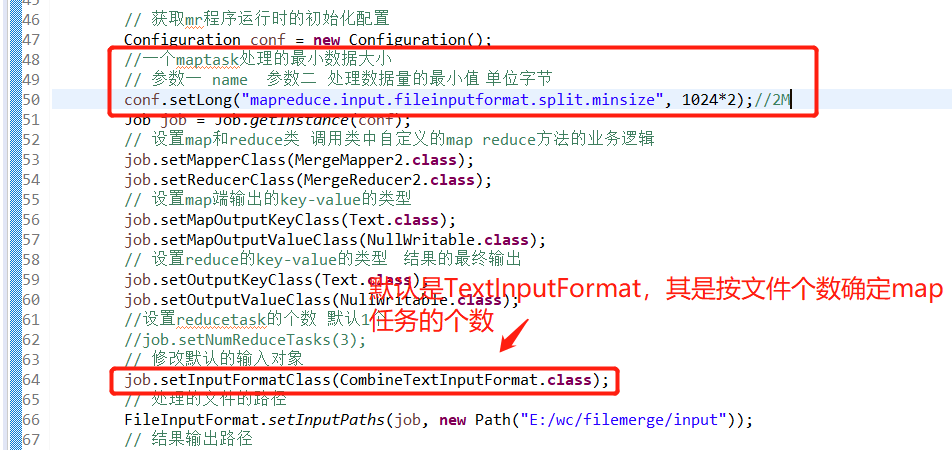
public class Merge2 { static class MergeMapper2 extends Mapper<LongWritable, Text, Text, NullWritable>{ StringBuilder sb = new StringBuilder(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { try { String line = value.toString(); sb.append(line+" "); } catch (Exception e) { e.printStackTrace(); } } @Override protected void cleanup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { context.write(new Text(sb.toString().trim()), NullWritable.get()); } } // 可以不需要reduce static class MergeReducer2 extends Reducer<Text, NullWritable, Text, NullWritable>{ @Override protected void reduce(Text key, Iterable<NullWritable> iters, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } } public static void main(String[] args) throws Exception { // 获取mr程序运行时的初始化配置 Configuration conf = new Configuration(); //一个maptask处理的最小数据大小 // 参数一 name 参数二 处理数据量的最小值 单位字节 conf.setLong("mapreduce.input.fileinputformat.split.minsize", 1024*2);//2M Job job = Job.getInstance(conf); // 设置map和reduce类 调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(MergeMapper2.class); job.setReducerClass(MergeReducer2.class); // 设置map端输出的key-value的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); // 设置reduce的key-value的类型 结果的最终输出 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); //设置reducetask的个数 默认1个 //job.setNumReduceTasks(3); // 修改默认的输入对象 job.setInputFormatClass(CombineTextInputFormat.class); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("E:/wc/filemerge/input")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("E:/wc/filemerge/output3/")); // 提交任务 参数等待执行 job.waitForCompletion(true) ; } }
知识点
2. 输入和输出
day07索引案例中利用MR程序进行了两次的计算,第二次的计算是以第一次的计算结果为输入文件的(由于默认是TextInputFormat,第一次MR计算结果输出是文本文件),此处可以将MR第一次计算得到的文本文件改为sequence文件(kvkvkvkv形式,比如MR程序中map阶段处理完交给reduce阶段的数据就是sequence)
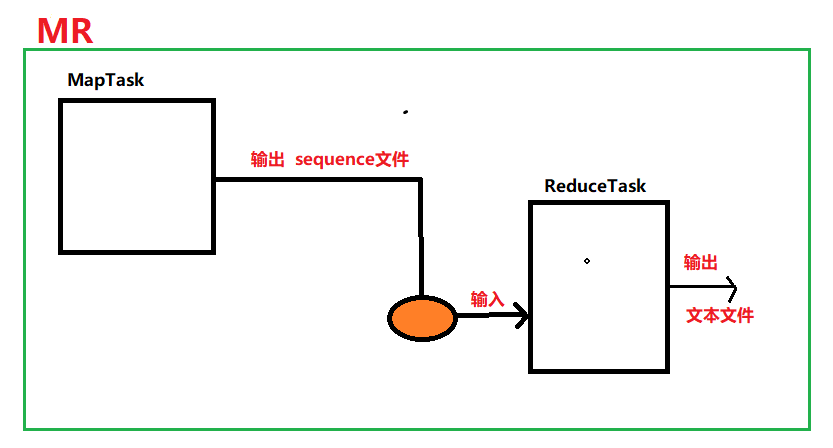
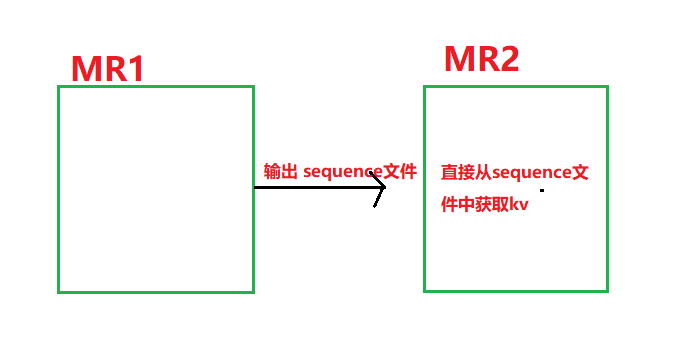
若让A输出文件类型变为sequence,这样当写第二个MR程序对第一次结果作为输入文件进行计算时,map阶段就不需要进行文件的处理了(如得到offset,line等,直接就能获取到kv值,效率比较高)
代码如下
Index1:在原先的代码中改数据输出类型为:SequenceFileOutputFormat,如下图
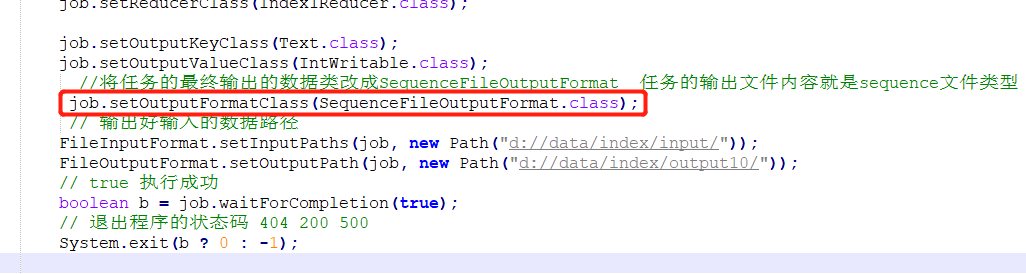
Index2:改变处
- 声明以SequenceFile文件的格式输入数据处理,如下图
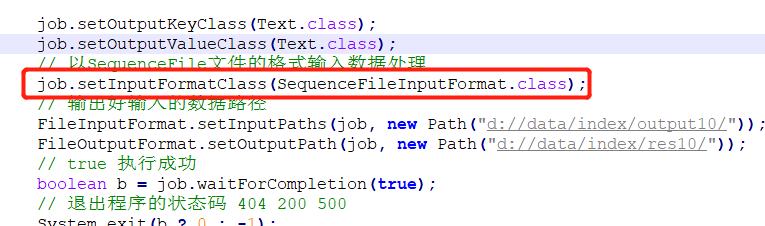
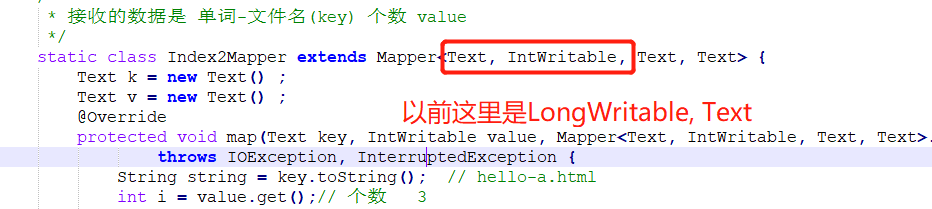
- 接收的数据是kv的形式,不需要再像以前那样写成LongWritable,Text
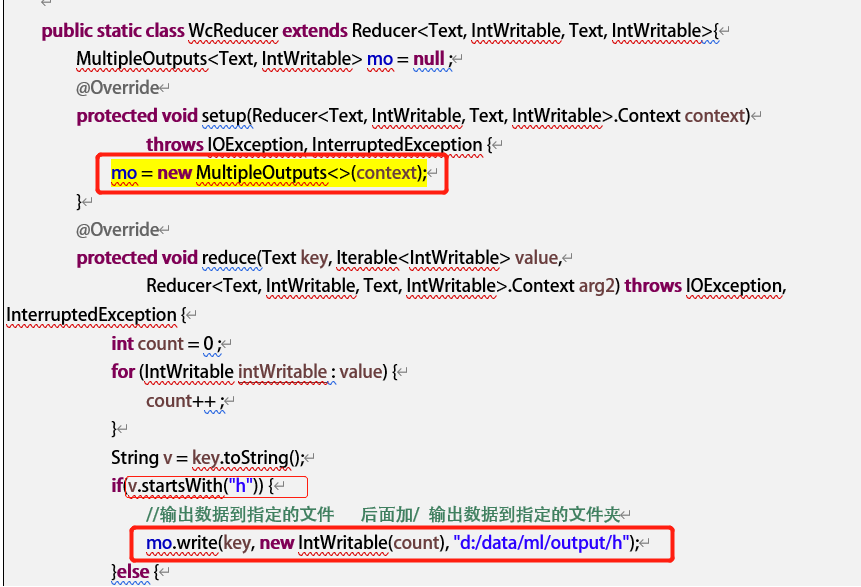
3. 多路径输出
可以将计算结果输出到不同的目录中(具体可见教案5.1.2.2)
4. zookeeper
4.1 简介:
- 是什么
是一个分布式协调工具,一个集群(不会存在单点故障:多台zk,并且记录相同的数据)
- 用处是什么
(1)记录数据(重要状态数据,大小不要超过64k)
(2)为客户提供读取数据的功能
(3)当客户端读取的数据发生变化时,zk会以时间的形式告知客户端(事件监听)
- 运用场景

4.2 选举机制
4.2.1 知识补充
leader 领导(只有一个)
flower 小弟(有多个)
Zookeeper会在集群中安装多个,在每个zk中都有一个唯一的不重复的ID,数据在存储的时候有一个数据VERSION,版本越新就越大
常见的几个端口
2181:leader和flower接收客户端请求的端口
2888:leader和flower内部通信的端口
3888:选举的端口
4.2.2 选举过程
(1)初次启动(3台机器为例)【3-5台,一般为奇数台】
- id为1的服务器启动,它向局域网发送广播寻找leader(端口2888)。发现没有leader,这台服务器就进入选举状态(3888端口),并向局域网广播投票(投自己);
-
id=2的服务器启动,它向局域网寻找leader,发现没有,进入投票状态(3888端口),收到服务器1所投的票;然后发现1<自己2,向局域网广播投票(投2);此时,服务1也会收到2的投票,发现2>自己,重新投(投2);此时,服务器2会收到两票;然后通过配置文件获知集群总共有3台机器,从而知道自己已经得多数票(当选);服务器2就切换到leader状态(2888);
-
id=3的服务器启动了,它向局域网寻找leader,发现服务器2是leader,自己主动进入follower状态
(2)leader宕机后
leader宕机以后集群中所有的节点进入投票状态 , (先按照数据的version 版本最新的节点当选leader , 如果多个节点的数据版本一致再按照id比较选举)
4.3 数据结构和类型
4.3.1 前言:
zookeeper将数据存储于内存中,具体而言,Znode是存储数据的最小单元,而Znode被以层次化的结构进行组织,形容成一棵树。其对外提供的视图类似于Unix文件系统。树的根Znode节点相当于Unix文件系统根路径。正如Unix中目录下可以有子目录一样,Znode节点下也可以挂载子节点,最终形成如下所示结构:
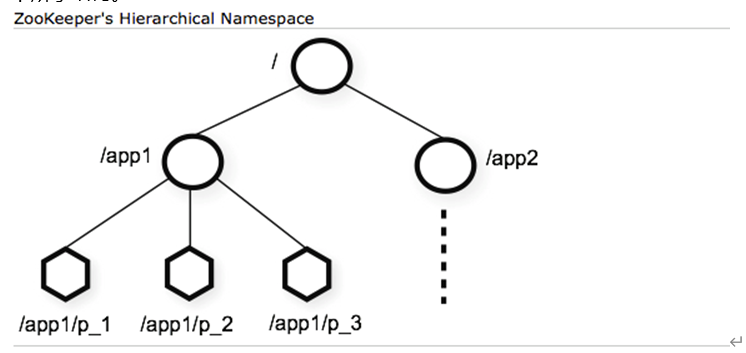
以文件系统进行类比的话,Znode天然具有目录和文件两重属性:即Znode既可以当做文件往里面写东西,又可以当做目录在下面挂载其他Znode。当然,由于Znode具有不同的类型,后半部分并不完全准确。
ZK可以记录用户的一些状态信息(数据) ,不易过大,要求在64k以内,它是以一种特殊的key/value的形式存储数据的 , key类似于文件系统中的路径 ,目的是为了维护key的层级关系

4.3.2 ZK的数据节点类型
- 临时节点:
临时结点的生命周期和客户端会话保持一致。客户端段会话存在的话临时结点也存在,客户端会话断开则临时结点会自动被服务端删除。临时节点下不能创建子节点。
- 临时有序节点:在具有临时节点的基本特性的基础上,会通过在结点路径后缀一串序号来区分多个子结点创建的先后顺序。这工作由Zookeeper服务端自动给我们做,只要在创建Znode时指定结点类型为该类型。
- 持久节点:最常见的Znode类型,一旦创建将已知存在于服务端,除非客户端通过删除操作进行删除,持久节点下可以创建子节点
- 持久顺序节点
4.4 安装
(1)上传------->rz
(2)解压配置
- tar -xzvf zookeeper-3.4.6.tar.gz -C /usr/apps/
- 进入conf文件,将zoo_sample.cfg 文件名改为zoo.cfg
- 在 zookeeper-3.4.6文件中创建一个用于存放数据的文件夹,此处自己为zk_data
- 修改zoo.cfg中的内容 ,如下
dataDir=/usr/apps/zookeeper-3.4.6/zk_data
在末尾
server.1=feng01:2888:3888 server.2=feng02:2888:3888 server.3=feng03:2888:3888
(3)分发
scp zookeeper-3.4.6 feng02:$PWD,同理第三台机器(此处的pwd表示的是命令行当前的路径)
(4)分发完成后分别在各台机器中的/usr/apps/zookeeper-3.4.6/zk_data 目录中执行------->echo 1/2/3 > myid
(5)环境变量的配置如下图(vi /etc/profile)

(6)启动
- 启动ZK服务:zkServer.sh start
- 查看节点的状态:zkServer.sh status
- 进入shell客户端:zkCli.sh
4.5 zk客户端
4.5.1 shell
进入shell客户端:zkCli.sh
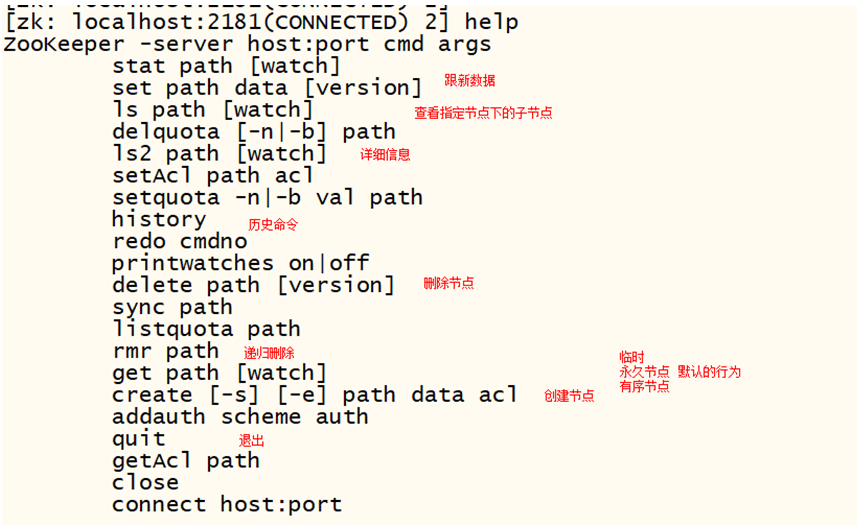
ls / 查看根目录下所有的节点 create /user lisi 在根目录下创建节点 key(/user) value(lisi) get /user 获取节点的数据值 set /user 新值 更新节点的值
4.5.1.1 创建节点(一定要有值)
create /节点名 值 默认创建永久节点 create -e /节点名 值 创建临时节点 断开以后数据删除 create -s /BIGDATA hbase 永久的有序节点 create -e -s /BIGDATA hive 临时有序节点 -e 临时节点 EPHEMERAL ephemeral -s 有序节点 sort
4.5.1.2 查看节点
ls ls2(相比ls,其会输出二外的信息,如下图)
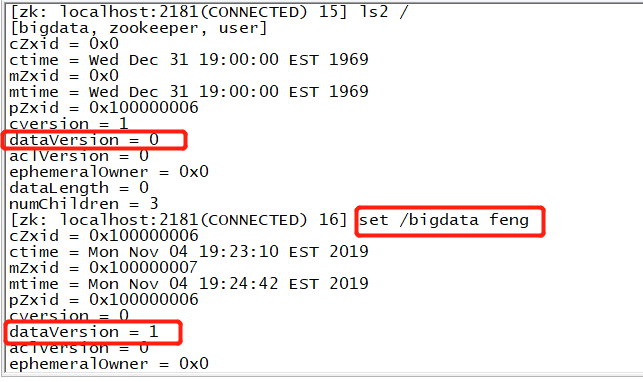
4.5.1.3 修改节点数据
修改以后数据的版本号会递增
4.5.1.4 删除节点

4.5.1.5 时间监听演示
- 数据的变化
- 子节点个数的变化

(1)数据变化:
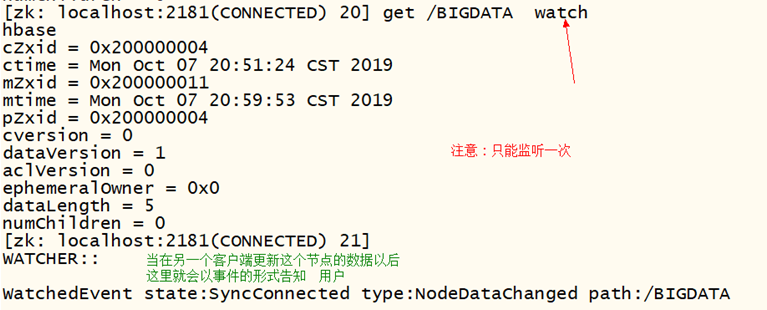
(2)子节点变化(删除子节点,添加子节点)

4.5.1 java客户端
(1)java客户端连接zk以及获取zk的java客户端对象
public class ConnectionDemo { public static void main(String[] args) throws Exception { // 连接zk的地址 2181 2888 3888 // zk所有节点的机器的位置 String connectString = "feng01:2181,feng02:2181,feng03:2181"; //超时时间 int sessionTimeout = 2000; // 获取zk的客户端对象 ZooKeeper zk = new ZooKeeper(connectString, sessionTimeout, null) ; // 操作zk节点 获取/路径下所有的子节点 ls / List<String> nodes = zk.getChildren("/", null); for (String node : nodes) { //[zookeeper, user0000000007, user, BIGDATA] System.out.println(node); } // 释放客户端对象 zk.close(); } }
(2)在zk的java客户端创建节点
public class CreateNode { public static void main(String[] args) throws Exception{ // 获取zk String connectString = "doit01:2181,doit02:2181,doit03:2181"; //超时时间 int sessionTimeout = 2000; // 获取zk的客户端对象 ZooKeeper zk = new ZooKeeper(connectString, sessionTimeout, null) ; // 创建节点 /* * 参数一 key(路径) Path must start with / character * 参数二 值 字节 * 参数三 权限 OPEN_ACL_UNSAFE开放所有的权限 * 参数四 节点类型 * PERSISTENT 永久 * PERSISTENT_SEQUENTIAL 有序 * EPHEMERAL 临时 * EPHEMERAL_SEQUENTIAL */ String create = zk.create("/BIG2", "big".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT) ; // 1 临时节点 // 2 永久节点 // 3 有序节点 System.out.println(create); //释放zk zk.close(); } }
(3)获取节点数据
public class GetNodeData { public static void main(String[] args) throws Exception { // 获取zk String connectString = "doit01:2181,doit02:2181,doit03:2181"; // 超时时间 int sessionTimeout = 2000; // 获取zk的客户端对象 ZooKeeper zk = new ZooKeeper(connectString, sessionTimeout, null); // 获取/BIG节点的值数据 byte[] data = zk.getData("/BIG", null, null); // 打印 System.out.println(new String(data)); zk.close(); } }
(4)删除节点delete(只能删除没有子节点的节点),以下是演示代码
/** * 测试Zk的其他方法 * 创建节点 * 删除节点 * 获取节点数据 * 判断节点是否存在 * 获取所有的子节点 * 修改节点 * * @author ThinkPad * */ public class ClientTest { // zk所有节点的机器的位置 String connectString = "doit01:2181,doit02:2181,doit03:2181"; // 超时时间 int sessionTimeout = 2000; ZooKeeper zk = null; /** * 获取zk对象 * * @throws Exception */ @Before public void init() throws Exception { zk = new ZooKeeper(connectString, sessionTimeout, null); } /** * 单元测试的类中不要写main方法 所有的方法是公共 的 所有的方法不能有参数 不能有返回值 * * @throws InterruptedException * @throws KeeperException */ @Test public void exists() throws KeeperException, InterruptedException { Stat stat = zk.exists("/BIG22", null); System.out.println(stat != null ? "存在" : "不存在"); /* * if(stat!=null) { System.out.println("存在"); System.out.println(stat); }else { * System.out.println("不存在"); } */ } /* * 删除空节点 * 删除任意节点 /BIGDATA * 递归 遍历下面的所有的节点 依次删除 * 都有出口 */ @Test public void deleteNode() throws Exception { /* * 参数1 路径 参数2 数据版本 -1 所有的版本 */ // 判断节点是否存在 // 1 NoNode for /BIG // 2 Directory not empty for /BIGDATA // zk.delete("/BIGDATA", -1); if (zk.exists("/BIGDATA", null) != null) { // 是否没有子节点 if (zk.getChildren("/BIGDATA", null).size() == 0) { zk.delete("/BIGDATA", -1); } else { System.out.println("有子节点不能删除"); } } else { System.out.println("节点不存在"); } } @After public void closeZk() throws Exception { zk.close(); } }
(5)递归删除
public class RmrNode { static ZooKeeper zk = null; static { try { String connectString = "doit01:2181,doit02:2181,doit03:2181"; // 超时时间 int sessionTimeout = 2000; // 获取zk的客户端对象 zk = new ZooKeeper(connectString, sessionTimeout, null); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void main(String[] args) throws Exception { delete("/BIGDATA") ; } /** * 递归 函数 * * @param path * @throws Exception */ public static void delete(String path) throws Exception { // 获取路径的节点 List<String> list = zk.getChildren(path, null); if(list.size()>0) { // /user/user2/user3 for (String cnode : list) { // 调用自己 delete(path + "/" + cnode); // 递归删除子节点 } } // 删除自己 zk.delete(path, -1); } }

