大数据学习day7------hadoop04----1 流量案例 2 电影案例(统计每部电影的均分,统计每个人的均分,统计电影的评论次数,***统计每部电影评分最高的N条记录(Integer.max),统计评论次数最多的n部电影(全局排序)) 3 line线段重叠次数案例 4.索引案例
1. 案例一: 流量案例
字段一:手机号
字段二:url
字段三:上行流量
字段四:下行流量

1.1 统计每个人的访问量的总流量
思路:以电话这个字段聚合,即以key聚合
map阶段代码如下


public class ViewsMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ Text k = new Text(); LongWritable v = new LongWritable(); long sumFlow = 0L; @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { String line = value.toString(); String[] split = line.split("\\s+"); sumFlow = Long.parseLong(split[2]) + Long.parseLong(split[3]); k.set(split[0]); v.set(sumFlow); context.write(k, v); } }
reduce阶段代码
public class ViewsReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ LongWritable v = new LongWritable(); @Override protected void reduce(Text key, Iterable<LongWritable> iters, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long sum = 0L; for (LongWritable longWritable : iters) { sum += longWritable.get(); } v.set(sum); context.write(key, v); } }
JobDriver类
public class JobDriver { public static void main(String[] args) throws Exception { // 获取MR程序运行时的初始化配置 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置map和reduce类,调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(ViewsMapper.class); job.setReducerClass(ViewsReducer.class); // 设置map端输出key-value的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 设置reduce端输出key-value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("E:/wc/flow.txt")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("E:/wc/flow/")); // 提交任务,参数 等待执行 job.waitForCompletion(true); } }
此处要注意的是:设置的key-value的类型要与map和reduce阶段的一致
1.2 统计每个url的总流量
思路同上,只是以url聚合,代码类似
2. 电影案例
movie:电影id
rate:用户评分
timeStamp:评分时间
uid:用户id
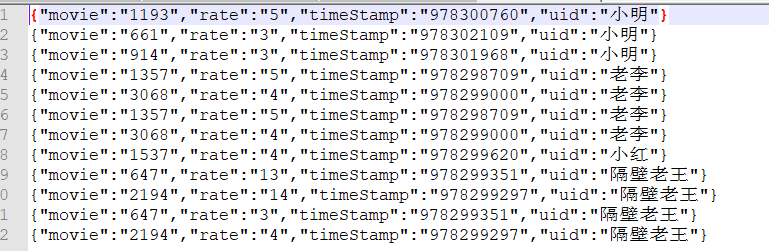
此数据是json数据,处理数据的时候尽量转换成java对象,便于操作
2.1 统计每部电影的均分
此处map和reduce部分的代码可以合并到一块去,如下
public class MovieAvgRate { static Text k = new Text(); static DoubleWritable v = new DoubleWritable(); // mapper部分 static class MovieMapper extends Mapper<LongWritable, Text, Text, DoubleWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context) throws IOException, InterruptedException { String line = value.toString(); MovieBean m = JSON.parseObject(line, MovieBean.class); String movie = m.getMovie(); double rate = m.getRate(); k.set(movie); v.set(rate); context.write(k, v); } } // Reducer部分 static class MovieReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable>{ @Override protected void reduce(Text key, Iterable<DoubleWritable> iters, Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context) throws IOException, InterruptedException { double sumRate = 0; int count = 0; for (DoubleWritable doubleWritable : iters) { double rate = doubleWritable.get(); sumRate += rate; count++; } double avg = sumRate/count; v.set(avg); context.write(key, v); } } // JOB驱动 public static void main(String[] args) throws Exception { // 获取MR程序运行时的初始化配置 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置map和reduce类,调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(MovieMapper.class); job.setReducerClass(MovieReducer.class); // 设置map端输出key-value的类型,当map和reduce的输出值类型一致时,可以省略map处值类型的设置 // job.setMapOutputKeyClass(Text.class); // job.setMapOutputValueClass(LongWritable.class); // 设置reduce端输出key-value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(DoubleWritable.class); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("E:/javafile/movie.txt")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("E:/wc/movie/res2")); // 提交任务,参数 等待执行 job.waitForCompletion(true); } }
注意:

2.2 统计每个人的均分
代码和上面每部电影均分相似,只是以uid为key进行聚合
2.3 统计电影的评论次数
以movie为key进行聚合,评论的次数直接用1来代替
代码如下
public class MovieCommentCount { static Text k = new Text(); static IntWritable v = new IntWritable(); static class ComentMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { String line = value.toString(); MovieBean mb = JSON.parseObject(line, MovieBean.class); String movie = mb.getMovie(); k.set(movie); v.set(1); context.write(k, v); } } static class ComentReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> iters, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable intWritable : iters) { int i = intWritable.get(); count += i; } k.set(key); v.set(count); context.write(k, v); } } public static void main(String[] args) throws Exception, IOException { // 获取MR程序运行时的初始化配置 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置map和reduce类,调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(ComentMapper.class); job.setReducerClass(ComentReducer.class); // 设置map端输出key-value的类型,当map和reduce的输出值类型一致时,可以省略map处值类型的设置 // job.setMapOutputKeyClass(Text.class); // job.setMapOutputValueClass(LongWritable.class); // 设置reduce端输出key-value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("E:/javafile/movie.txt")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("E:/wc/movie/res3")); // 提交任务,参数 等待执行 job.waitForCompletion(true); } }
2.4 统计每部电影评分最高的n条记录
以movie为key进行聚合,最后在reducer部分输出key为MovieBean 值为NullWritable
代码
(1)MovieBean
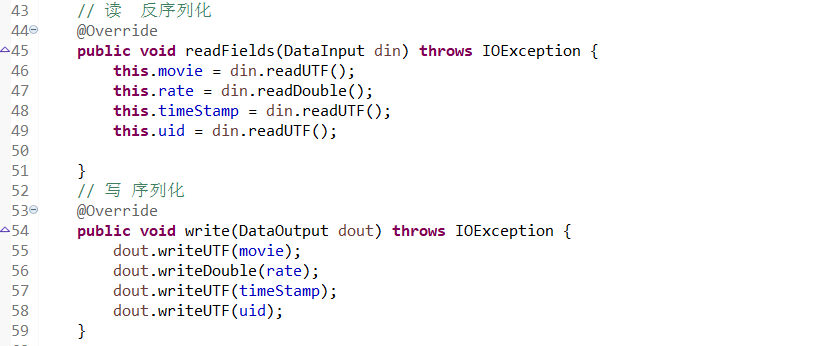
public class MovieBean implements Writable{ private String movie; private double rate; private String timeStamp; private String uid; public String getMovie() { return movie; } public void setMovie(String movie) { this.movie = movie; } public double getRate() { return rate; } public void setRate(double rate) { this.rate = rate; } public String getTimeStamp() { return timeStamp; } public void setTimeStamp(String timeStamp) { this.timeStamp = timeStamp; } public String getUid() { return uid; } public void setUid(String uid) { this.uid = uid; } @Override public String toString() { return "MovieBean [movie=" + movie + ", rate=" + rate + ", timeStamp=" + timeStamp + ", uid=" + uid + "]"; } // 读 反序列化 @Override public void readFields(DataInput din) throws IOException { this.movie = din.readUTF(); this.rate = din.readDouble(); this.timeStamp = din.readUTF(); this.uid = din.readUTF(); } // 写 序列化 @Override public void write(DataOutput dout) throws IOException { dout.writeUTF(movie); dout.writeDouble(rate); dout.writeUTF(timeStamp); dout.writeUTF(uid); }
此处的注意点:当使用自定义的类作为mapper或者reducer的key或者value时,需要对其实现hdp内部的序列化,否则汇报如下的错误
2019-11-08 10:42:50,720 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1285)) - session.id is deprecated. Instead, use dfs.metrics.session-id 2019-11-08 10:42:50,724 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(79)) - Initializing JVM Metrics with processName=JobTracker, sessionId= 2019-11-08 10:42:52,101 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(64)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2019-11-08 10:42:52,136 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(171)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String). 2019-11-08 10:42:52,146 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(289)) - Total input files to process : 1 2019-11-08 10:42:52,176 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(200)) - number of splits:1 2019-11-08 10:42:52,271 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(289)) - Submitting tokens for job: job_local933787924_0001 2019-11-08 10:42:52,483 INFO [main] mapreduce.Job (Job.java:submit(1345)) - The url to track the job: http://localhost:8080/ 2019-11-08 10:42:52,484 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1390)) - Running job: job_local933787924_0001 2019-11-08 10:42:52,489 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(498)) - OutputCommitter set in config null 2019-11-08 10:42:52,497 INFO [Thread-3] output.FileOutputCommitter (FileOutputCommitter.java:<init>(123)) - File Output Committer Algorithm version is 1 2019-11-08 10:42:52,498 INFO [Thread-3] output.FileOutputCommitter (FileOutputCommitter.java:<init>(138)) - FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 2019-11-08 10:42:52,498 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(516)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 2019-11-08 10:42:52,554 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(475)) - Waiting for map tasks 2019-11-08 10:42:52,555 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(251)) - Starting task: attempt_local933787924_0001_m_000000_0 2019-11-08 10:42:52,588 INFO [LocalJobRunner Map Task Executor #0] output.FileOutputCommitter (FileOutputCommitter.java:<init>(123)) - File Output Committer Algorithm version is 1 2019-11-08 10:42:52,588 INFO [LocalJobRunner Map Task Executor #0] output.FileOutputCommitter (FileOutputCommitter.java:<init>(138)) - FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 2019-11-08 10:42:52,600 INFO [LocalJobRunner Map Task Executor #0] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(168)) - ProcfsBasedProcessTree currently is supported only on Linux. 2019-11-08 10:42:52,663 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:initialize(619)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@88da7d9 2019-11-08 10:42:52,668 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:runNewMapper(756)) - Processing split: file:/E:/javafile/movie.txt:0+1019 2019-11-08 10:42:52,721 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:setEquator(1205)) - (EQUATOR) 0 kvi 26214396(104857584) 2019-11-08 10:42:52,721 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(998)) - mapreduce.task.io.sort.mb: 100 2019-11-08 10:42:52,721 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(999)) - soft limit at 83886080 2019-11-08 10:42:52,721 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(1000)) - bufstart = 0; bufvoid = 104857600 2019-11-08 10:42:52,721 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(1001)) - kvstart = 26214396; length = 6553600 2019-11-08 10:42:52,745 WARN [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:createSortingCollector(411)) - Unable to initialize MapOutputCollector org.apache.hadoop.mapred.MapTask$MapOutputBuffer java.lang.NullPointerException at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1011) at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:402) at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81) at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:698) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:770) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:270) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 2019-11-08 10:42:52,753 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(483)) - map task executor complete. 2019-11-08 10:42:52,755 WARN [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:run(587)) - job_local933787924_0001 java.lang.Exception: java.io.IOException: Initialization of all the collectors failed. Error in last collector was :null at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:489) at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:549) Caused by: java.io.IOException: Initialization of all the collectors failed. Error in last collector was :null at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:414) at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81) at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:698) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:770) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:270) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.NullPointerException at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1011) at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:402) ... 10 more 2019-11-08 10:42:53,488 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1411)) - Job job_local933787924_0001 running in uber mode : false 2019-11-08 10:42:53,490 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1418)) - map 0% reduce 0% 2019-11-08 10:42:53,491 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1431)) - Job job_local933787924_0001 failed with state FAILED due to: NA 2019-11-08 10:42:53,497 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1436)) - Counters: 0
序列化代码如下:

(2)业务代码(MovieRateTopN)
public class MovieRateTopN { static Text k = new Text(); static class RateTopNMapper extends Mapper<LongWritable, Text, Text, MovieBean>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, MovieBean>.Context context) throws IOException, InterruptedException { try { String line = value.toString(); MovieBean mb = JSON.parseObject(line, MovieBean.class); String movie = mb.getMovie(); k.set(movie); context.write(k, mb); } catch (Exception e) { e.printStackTrace(); } } } static class RateTopNReducer extends Reducer<Text, MovieBean, MovieBean, NullWritable>{ @Override protected void reduce(Text key, Iterable<MovieBean> iters, Reducer<Text, MovieBean, MovieBean, NullWritable>.Context context) throws IOException, InterruptedException { try { List<MovieBean> list = new ArrayList<>(); for (MovieBean movieBean : iters) { MovieBean mb = new MovieBean(); // 将迭代器中得到的MovieBean中的属性复制到新创建的对象中去 BeanUtils.copyProperties(mb,movieBean); list.add(mb); } // 对list中的数据按rate降序排列 Collections.sort(list, new Comparator<MovieBean>() { @Override public int compare(MovieBean o1, MovieBean o2) { return Double.compare(o2.getRate(), o1.getRate()); } }); // 输出前3个数据 for(int i = 0 ; i < Integer.min(3, list.size()) ; i++) { context.write(list.get(i), NullWritable.get()); } } catch (Exception e) { e.printStackTrace(); } } } public static void main(String[] args) throws Exception, IOException { // 获取MR程序运行时的初始化配置 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置map和reduce类,调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(RateTopNMapper.class); job.setReducerClass(RateTopNReducer.class); // 设置map端输出key-value的类型,当map和reduce的输出值类型一致时,可以省略map处值类型的设置 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(MovieBean.class); // 设置reduce端输出key-value的类型 job.setOutputKeyClass(MovieBean.class); job.setOutputValueClass(NullWritable.class); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("E:/javafile/movie.txt")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("E:/wc/movie/res15")); // 提交任务,参数 等待执行 job.waitForCompletion(true); } }
需要注意的部分1:
第一处
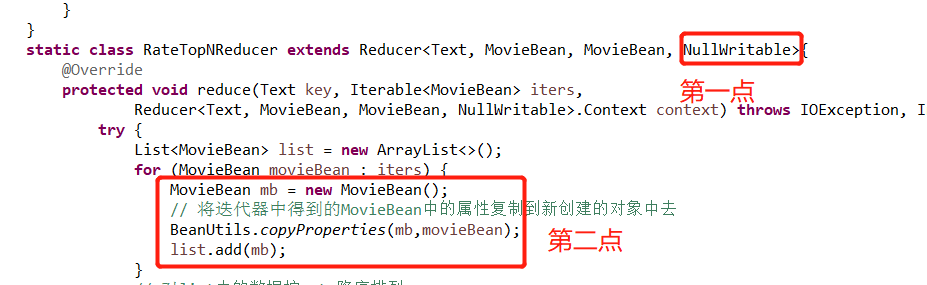
第一点:reducer部分的输出value的类型可以为NullWritable
第二点:迭代器返回的的对象是同一个对象(内存空间的地址是一样的),所以需要创建一个对象来获取从迭代器中获得的对象的属性,若是第二点处直接使用如下代码
list.add(movieBean);
这样列表中存放的为同一个对象(属性值刚好为从迭代器最后出来的一个movieBean的属性)
第二处
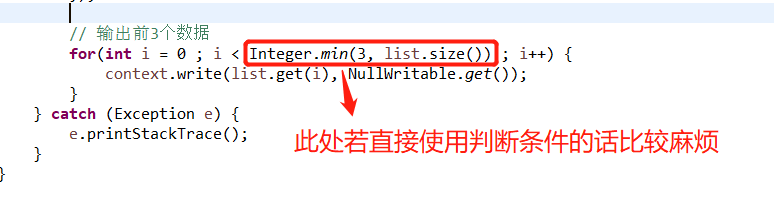
知识点:Integer.max(2, 3) ------>得到的结果为3
Integer.min(2, 3) ------>得到的结果为2
需要注意的部分2
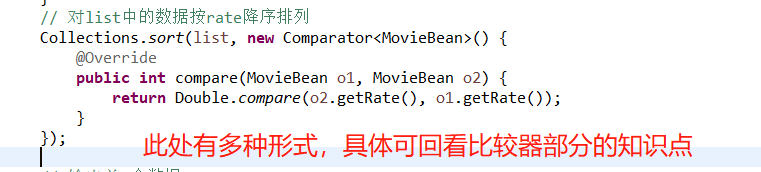
排序形式:
- (1.2-3.3)>0?-1:1
- 包装类型直接调用conparaTo方法
- Double.compare(2.3 , 2,1)
需要注意的部分3
在map端和reduce端处理数据的时候一定要try catch 否则程序出现数据解析异常的时候mr程序就会失败(空指针异常)
2.5 统计评论次数最多的n部电影
思路:此题属于全局排序,首先以movie为key聚合,然后在reduce处得到movie以及对应的评论次数,这个时候再对这个数据进行全局排序,即创建一个map,以movie为key,评论的次数为value放进map中,然后将map以value降序排序(cleanup方法)
cleanup方法在reduce方法执行之后 ,最后执行一次,全局数据的操作,用于收尾工作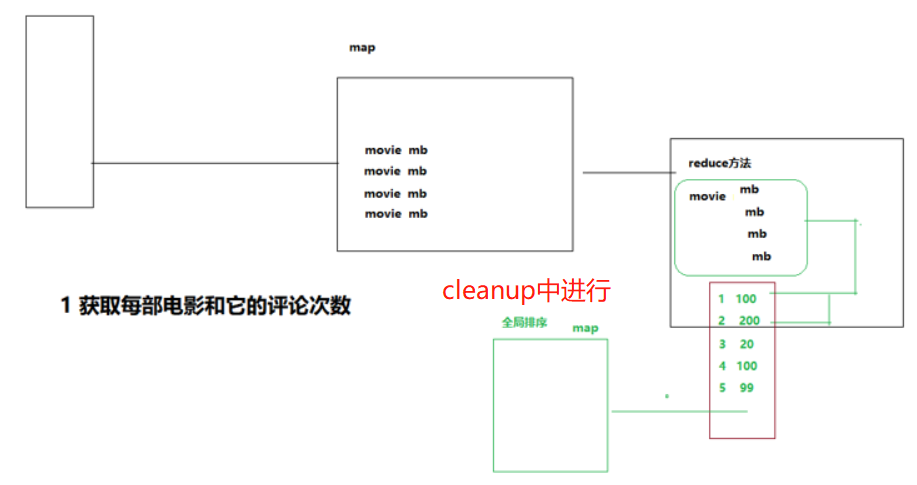
具体代码如下:
public class MovieViewsTopN { static Text k = new Text(); static IntWritable v = new IntWritable(); // map部分,以movie为key聚合 static class MovieViewsMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { try { String line = value.toString(); MovieBean mb = JSON.parseObject(line, MovieBean.class); k.set(mb.getMovie()); v.set(1); context.write(k, v); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } } // reduce部分 输出值: movie-评论次数 static class MovieViewsReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ Map<String, Integer> map = new HashMap<>(); @Override protected void reduce(Text key, Iterable<IntWritable> iters, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable intWritable : iters) { int i = intWritable.get(); count += i; } map.put(key.toString(), count); } // 进行全局排序 @Override protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { Set<Entry<String,Integer>> set = map.entrySet(); ArrayList<Entry<String,Integer>> list = new ArrayList<>(set); Collections.sort(list, new Comparator<Entry<String, Integer>>(){ @Override public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); for(int i=0;i<Integer.min(3, list.size()); i++) { k.set(list.get(i).getKey()); v.set(list.get(i).getValue()); context.write(k, v); } } } public static void main(String[] args) throws Exception { // 获取MR程序运行时的初始化配置 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置map和reduce类,调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(MovieViewsMapper.class); job.setReducerClass(MovieViewsReducer.class); // 设置reduce端输出key-value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("E:/javafile/movie.txt")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("E:/wc/movie/res20")); // 提交任务,参数 等待执行 job.waitForCompletion(true); } }
3. line线段重叠次数案例
题意:有如下文件(1,4表示1,2,3,4),记录各个数字的重叠次数(如1出现了几次,2出现了几次)

代码
public class Line { static class LineMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, IntWritable>.Context context) throws IOException, InterruptedException { String line = value.toString(); String[] split = line.split(","); // 1,4 int x1 = Integer.parseInt(split[0]);// 1 int x2 = Integer.parseInt(split[1]);// 4 // for (int i = x1; i <= x2; i++) { context.write(new IntWritable(i), new IntWritable(1));// 11 21 31 41 } } } static class LineReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> { @Override protected void reduce(IntWritable key, Iterable<IntWritable> iters, Reducer<IntWritable, IntWritable, IntWritable, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable intWritable : iters) { count++; } context.write(key, new IntWritable(count)); } } public static void main(String[] args) throws Exception { // 获取mr程序运行时的初始化配置 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置map和reduce类 调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(LineMapper.class); job.setReducerClass(LineReducer.class); // 设置map端输出的key-value的类型 /* * job.setMapOutputKeyClass(Text.class); * job.setMapOutputValueClass(IntWritable.class); */ // 设置reduce的key-value的类型 结果的最终输出 job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(IntWritable.class); // 设置reducetask的个数 默认1个 // job.setNumReduceTasks(3); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("D:\\data\\line\\input")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("D:\\data\\line\\res")); // 提交任务 参数等待执行 job.waitForCompletion(true); } }
4. 索引案例
题意:有三个文件 a.html b.html c.html 其内容如下(只列出一个文件,其它类似)
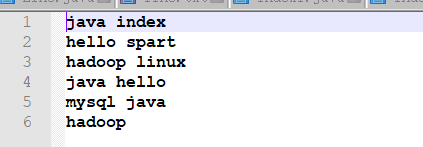
需求:单词在每个文件夹中的数量(以java为例,格式如下: java a.html-3 c.html-3 b.html-1 )
代码分两部分:
第一部分:为了得到如下形式的输出数据(还是以java单词为例):
java a.html-1 java a.html-1 java b.html-1
Index1代码
public class Index1 { static Text k = new Text(); static IntWritable v = new IntWritable(); static class Index1Mapper extends Mapper<LongWritable, Text, Text, IntWritable>{ String name = null; // 获取相应的文件名 @Override protected void setup(Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { FileSplit fs = (FileSplit)context.getInputSplit(); name = fs.getPath().getName(); } @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { try { String line = value.toString(); String[] split = line.split("\\s"); for (String word : split) { // word-文件名 数量 k.set(word + "-" + name); v.set(1); context.write(k, v);// java-a.html 1 java-b.html 1 } } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } } static class Index1Reducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> iters, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable intWritable : iters) { int i = intWritable.get(); count += i; } v.set(count); context.write(key, v); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setMapperClass(Index1Mapper.class); job.setReducerClass(Index1Reducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 输出好输入的数据路径 FileInputFormat.setInputPaths(job, new Path("E:/wc/input/")); FileOutputFormat.setOutputPath(job, new Path("E:/wc/output1/")); // true 执行成功 boolean b = job.waitForCompletion(true); // 退出程序的状态码 404 200 500 System.exit(b ? 0 : -1); } }
第二部分:将第一部分得到的数据再次处理,从而得到想要的数据格式
public class Index2 { static class Index2Mapper extends Mapper<LongWritable, Text, Text, Text> { Text k = new Text(); Text v = new Text(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { // 获取第一个mapreduce任务处理的数据的每行 String line = value.toString(); // a-a.html \t 3 String[] split = line.split("\\s"); //a-a.html String wordAndFileName = split[0]; // 3 String count = split[1]; //处理 a-a.html 切割 String[] split2 = wordAndFileName.split("-"); //获取单词 a String word = split2[0]; // 获取文件名 a.html String fileName = split2[1]; // 组装文件名和单词个数 a.html-3 String valueString = fileName + "-" + count; // a.html-3 // 单词设置到key k.set(word); v.set(valueString); // java a.html-3 // 输出kv 单词 v就是 文件名-个数 context.write(k, v); } } static class Index2Reducer extends Reducer<Text, Text, Text, Text> { Text v = new Text() ; @Override protected void reduce(Text key, Iterable<Text> iters, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { /* * hello a.html-3 * hello b.html-2 * hello c.html-3 * ----> a.html-3 b.html-2 c.html-3 */ // 创建一个String对象 追加每个单词在每个文中出现的次数 StringBuilder sb = new StringBuilder(); for (Text text : iters) {//a.html-3 b.html-2 c.html-3 sb.append(text.toString()+" ") ;//a.html-3 b.html-2 c.html-3 } // 字符串 v.set(sb.toString().trim()); //输出结果 context.write(key, v); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setMapperClass(Index2Mapper.class); job.setReducerClass(Index2Reducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); // 输出好输入的数据路径 FileInputFormat.setInputPaths(job, new Path("E:/wc/output1/")); FileOutputFormat.setOutputPath(job, new Path("E:/wc/index/res1")); // true 执行成功 boolean b = job.waitForCompletion(true); // 退出程序的状态码 404 200 500 System.exit(b ? 0 : -1); } }
最终得到的结果如下图

此处遇到的问题:
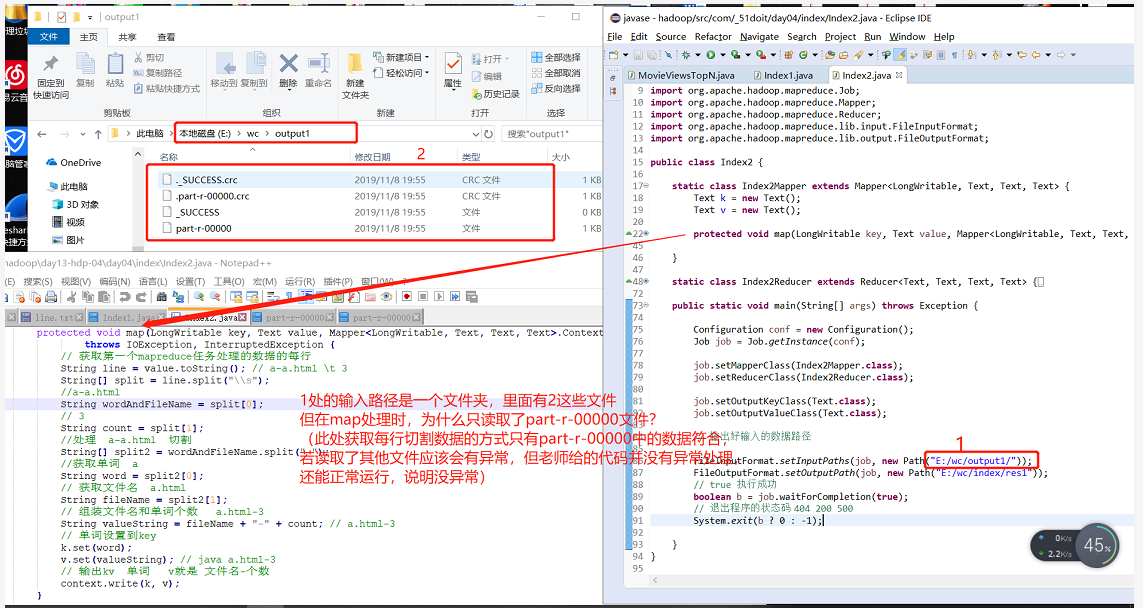
答案:
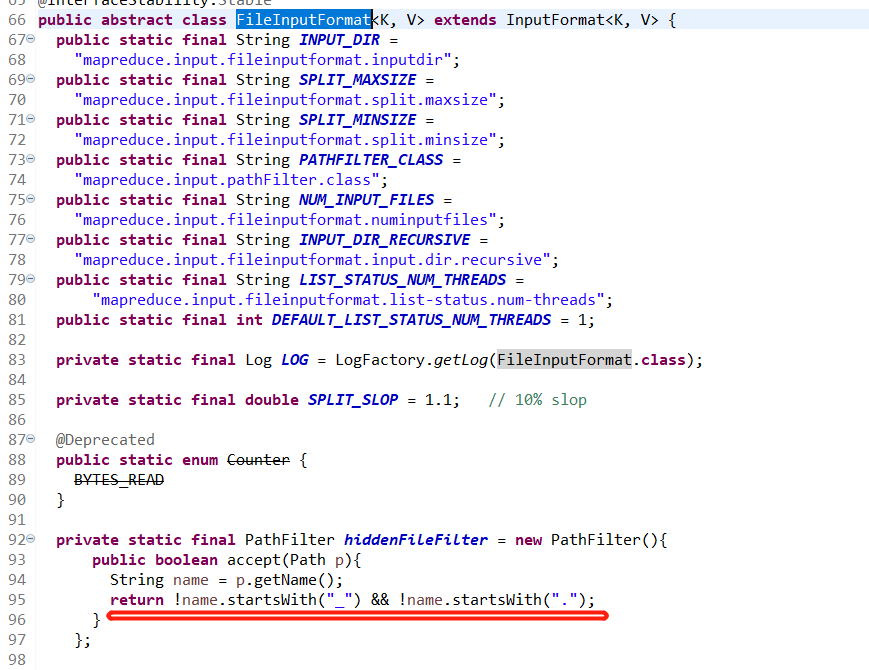
在TextInputFormat的父类(FileInputFormat)中做了一个通用的处理,即过滤掉以“_”,"." 开头的文件,所以就会只读取part-r-00000文件,这是一个通用的处理,一个job产生的结果,经常要作为下一个job的输入,如果它在读取时,不过滤掉这些“附加”文件,那就会很麻烦。具体源码如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号