Flink1.15.0 ON YARN集群安装
安装准备:
hadoop3.2.2, flink1.15.0
在成功安装hadoop3.2.2的基础上,采用YARN模式安装Flink1.15。
1.在/etc/profile文件中追加配置:
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
2.修改hadoop相关配置:
在conf文件夹中hadoop-env.sh文件中,添加配置:
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
在yarn-site.xml文件中添加不检查节点内存配置(flink用内存超过一定量时会被hadoop结束线程)。
<property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
在flink的flink-conf.xml文件中,添加UI的端口配置(不配置flink会使用随机端口):
rest.port: 8081
配置完成后,启动flink:
bin/flink-session
报错:
java.io.IOException: Got error, status=ERROR, status message , ack with firstBadLink as ********.122:9866 at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:134) ~[flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar:3.1.1.7.2.9.0-173-9.0] at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:110) ~[flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar:3.1.1.7.2.9.0-173-9.0] at org.apache.hadoop.hdfs.DataStreamer.createBlockOutputStream(DataStreamer.java:1778) [flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar:3.1.1.7.2.9.0-173-9.0] at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1679) [flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar:3.1.1.7.2.9.0-173-9.0] at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:716) [flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar:3.1.1.7.2.9.0-173-9.0] 2022-05-23 15:54:34,591 WARN org.apache.hadoop.hdfs.DataStreamer [] - Abandoning BP-663602447-10.171.55.121-1653037076867:blk_1073741905_1081 2022-05-23 15:54:34,591 WARN org.apache.hadoop.hdfs.DataStreamer [] - Excluding datanode DatanodeInfoWithStorage[10.171.55.122:9866,DS-4457a3e2-ab0b-49c9-b144-f508123c2fa7,DISK] ^C2022-05-23 15:54:37,603 INFO org.apache.hadoop.hdfs.DataStreamer [] - Exception in createBlockOutputStream blk_1073741906_1082
org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session cluster at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:428) at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:606) at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$4(FlinkYarnSessionCli.java:860) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1898) at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:860)
解决办法为:
1.打开datanode节点的9866端口。
2.在flink的lib文件夹添加如下jar:
commons-cli-1.5.0.jar(apache-commons-cli) flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar hadoop-yarn-api-3.2.2.jar(从hadoop/share/yarn/文件夹拷贝过来)
以上2个jar,从以下仓库下载:
https://mvnrepository.com/
其中commons-cli,选择:apache-common-cli(我选择1.5.0版本)
然后重新运行,出现以下画面,说明ok:

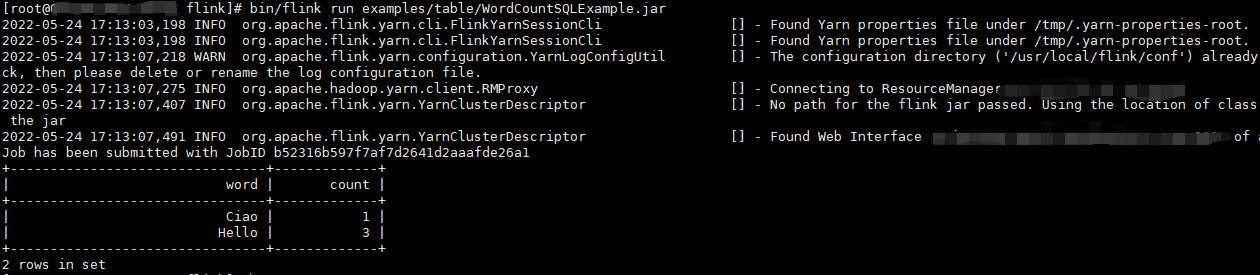
运行官方示例:
在flink目录下运行:
bin/flink run examples/table/WordCountSQLExample.jar