


Java内存分配及垃圾回收
一:Java虚拟机数据区组成
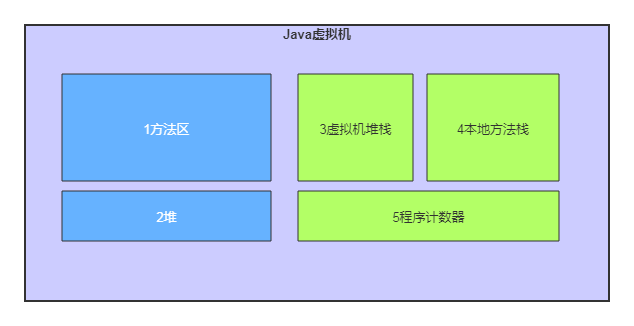
Java虚拟机数据区有五大部分组成,分别是:方法区、堆区、虚拟机堆栈区、本地方法区、程序计数器区,这五个部分分成两组,分别是:
(A)线程共享部分:
1.方法区:这个区域被各个线程共享使用,用来存储被虚拟机加载的类、常量、静态变量、即时编译后代码等信息,这个区域相对于【堆区】而言稳定很多,但仍然存在内存溢出的概率,本区会涉及到内存回收。
2.堆区:堆区是虚拟机中内存中占用最大的一部分,用来存储由各个线程运行时创建的各种非瞬时性的对象副本,因为涉及到多线程的同时使用(读取和写入),因此,这个区域是垃圾回收机制发挥主要作用的地方,也是最容易发生内存泄漏的地方,这个区域是内存管理的核心区域,内存管理的大部分功能都是围绕着这个区域的健康运行而设计的。
(B)线程独占部分:
3.虚拟机堆栈:这个区域其实就是单个线程的操作区,相当于线程这个工人的私人操作台。
4.本地方法栈:和虚拟机栈类似,只是Java虚拟机使用到的本地(非本虚拟机产生或者由其它语言产生的方法)方法提供服务的场所,类似于向其它厂商提供零件、接收其它厂商零件等等与配套厂商协作的场所。
5.程序计数器:这个区域用来记录单个线程在运行过程行号、跳转控制等等。
二、对象内存分配:
当虚拟机遇到new指令时,虚拟机会在方法区的常量池中去寻找这个类的引用标记,如果找到则进行分配内存,初始化变量等;如果没有找到,则会对这个类进行检查、把class文件编译后产生的有关类初始化的各种符号、标记存储于常量池中,然后进行类初始化工作。
判断对象是否存在方法:
1.引用计数器:
引用计数器方法原理为:将对象自身添加一个引用计数器,每当有一个地方引用它时,计数器+1,当引用失效时,计数器-1,任何时刻,计数器为0的对象说明不再被使用,进入被回收流程。这个方法的特点为算法简单,效率很高,但有一个致命的缺点:无法解决对象间相互引用的问题。
2.可达性分析:
这个算法的基本思路是,通过一系列的称之为“GC Roots”的对象作为起点,向下搜索对象,将可达到的对象称之为存活对象,将不可达对象视之为可回收对象。可回收对象进入回收流程。可视为“GC Roots”对象有:
(1)方法区中的静态变量、常量
(2)本地方法栈中引用对象
(3)虚拟机栈中引用的对象

对象之间的引用按强弱关系,分成四类:
1,强应用,类似这种:Object A = new Object();这种引用对象不会被回收,除非通过可达性分析认为对象已经不可达。
2,软引用,软引用对象在内存不够时才会被虚拟机回收。
3,弱引用,弱引用对象的生存概率更低,在虚拟机系统进行下一次垃圾回收时被回收。
4,虚引用,顾名思义很缥缈,虚幻,一般在虚拟机为了实现特定功能而使用,与日常开发关系不大。
内存对象存活与否需要经过两个阶段。第一阶段为经过可达性分析判断此对象已经不可达,此时对象处于被判缓刑阶段,仅仅进行了第一次标记,还不能进行垃圾回收。然后JVM进行判断,判断的依据是:对象是否覆盖了finalize()方法或者是否被执行过一次finalize()方法,倘若需要被认为执行finalize()方法,则虚拟机会在内部建立一个队列,在这个队列中要么被再次标记,并被销毁,要么会被重新引用,逃离死亡命运,重新返回存活状态。
三、垃圾回收算法分类:
1.标记清除算法。本算法分标记、清除两个阶段。首先标记出需要回收的对象,在标记完成后统一回收所有被标记的对象。算法主要存在两个缺陷,一是两个过程的效率不高,因为涉及到堆的扫描,这个过程很漫长。另一个是标记清除后,会产生大量的不连续碎片,导致后续需要分配大容量对象时,无法找到足够的连续内存而被迫进行另一次垃圾回收。这种算法是后续算法的基础,后续算法基本上都是围绕着改进本算法的不足而设计推出的。
2.复制算法。为了解决标记清除算法的碎片问题而推出的复制算法,可以说简单、粗暴、有效(跟西哲一脉相承)。该算法将可用内存等分成两部分,每次只使用其中一部分,当进行垃圾回收时,虚拟机将这部分中还存活的对象复制到另一区域中,将本区域清空待分配。这个算法特点是垃圾回收处理有些粗糙,不够细腻,每次回收都涉及到不等的内存复制动作。本算法应用在新生代垃圾回收。
3.标记-整理算法。标记整理算法和标记清理算法类似,不同之处在于在清理阶段,清理完垃圾后,按照开销估算小的原则,将剩余的存活对象向一端移动,整理出大片连续的空闲内存,供以后内存分配使用。
4.分代收集算法。这个算法没有什么新的思想,可以说是一个综合性的算法。该算法将内存分成新生代&老年代。在新生代区域,每次垃圾回收时,若剩余少量的存活对象,则使用标记-复制算法。若存活对象较多则进行标记清除处理或者标记整理处理。在老年代区域,则由于存活对象一般较多,则采用标记-整理算法进行回收。
jvm回收采用分带收集算法。
四、HotSpot算法实现
1.什么是安全点?
首先,目前的主流Java虚拟机基本上都是准确式GC,虚拟机通过OopMap这种数据结构来得知内存中,哪些地方存放着对象引用,在类加载完成后,Hotspot就能很精确地知道内存的什么位置存放着什么类型,多大内存占用的对象。这样一来,在GC回收时就可以直接判定哪些对象需要回收与否,而不需要再进行扫描,提高了GC效率。实际上,HotSpot也不会为每一条运行指令都生成OopMap,以加快程序的运行,而只是想程序运行到特定的位置来记录、生成OopMap信息,这些位置点即是安全点。简言之,安全点就是程序中由HotSpot指定的某些特定的位置,在这些位置,HotSpot生成OopMap数据结构,同时进行GC操作,在这些点,Java线程是短暂停止运行的。
2.什么是安全区?
安全区是在一段代码中,各种引用关系不发生变化的代码区域。在这个区域,各种引用关系保持稳定,不再发生变化,这样,当线程运行到安全区时首先会通过标识,向虚拟机声明自己已经进入安全区,这时,即使线程已经被挂起或者其他状态,那么虚拟机扔可以进行GC操作,而不必让线程继续运行到安全点再执行。安全区是安全点的扩展,相当于战争中的停火区间。而安全点相当于战争中的每一个休息时间点,虽然战事在进行,然而在这些安全点,大家都忙着吃饭、休息、打扫卫生,没人会继续。
几种垃圾收集器
Serial收集器。这是一种历史悠久的单线程收集器,主要负责新生代的垃圾收集,特点是简单、高效,如果虚拟机运行在Client模式下,用Serial收集器是个不错的选择。
ParNew收集器。这个收集器相当于是Serial收集器的多线程版本,也是用在新生代垃圾收集。
Parallel Scavenge收集器,这个收集器是新生代的另一种收集器,特点是可以可以达到一个可控制的吞吐量。吞吐量=运行客户代码时间 / (运行客户代码时间 + 垃圾收集时间)。
CMS收集器。CMS收集器是一种获取最短回收时间的垃圾收集器。由于目标明确,适用面广,因此很大一部分被用在Web服务器上。CMS收集器采用标记-清除算法实现,收集过程流程复杂。
G1收集器。最新的垃圾回收研究成果。用在新生代和老年代垃圾收集,是目前比较新的收集器。
五、内存分配和回收策略
1.新生代一般分两种区域结构。其一是Eden,new Object的内存分配一般会被对应在此,另一种是Servivor区域,此区域用来存储经过垃圾回收而幸存下来的对象。具体而言,新生代有三个区域划分,即:一个Eden区、两个Servivor区。在复制算法下,三个区域的大小分配一般为:8:1:1.当回收发生时,虚拟机将Eden和Servivor区域中还存活的对象一次性复制到另外一块Servivor区域内,最后清理掉Eden和和刚刚用过的Servivor区域。
2.一般不大的对象,直接分配在新生代的Eden区域上,如果区域空间不够,也会有少量对象分配在老年代区域中。这个区域内的对象寿命都很短,一般被采用标记-清除算法回收。
备注:由于各种资料缺少,此处描述模糊。自己推测为:一般对象会被分配到Eden区域,而其中一个Servivor用来存储上次幸存的对象,而另一个Servivor区域为空,等待下次垃圾收集时,存储更幸运的对象,而当内存分配时,如果Eden区域容量不够,根据内存担保原则,将对象分配在老年代(对象还属于新生代,只是借用老年代空间)。
3.大的对象直接分配在老年代。这个区域内对象相对于新生代而言,较稳定,寿命更长。这个区域一般采用标记-整理算法实现垃圾收集。
4.新生代对象和老年代对象关系。一般对象会分配在新生代,新生代进行垃圾收集时,如果对象未被收集,并且能被Servivor容纳,那么此对象会被转移到Servivor区域,自身的年龄设置为1,以此来推,每当对象熬过一次垃圾收集,自身对象就增加1,当对象增加到一定岁数(默认为15岁),对象就会被转移到老年代中。除此之外,还有一种情况,当Servivor区域中相同年龄的所有对象的大小总和 > Sevivor空间一半时,年龄>=此年龄的所有对象就可以直接进入老年代,而无需等到设置的岁数再被转移。
参考资料:深入理解Java虚拟机(第二版)

