机器学习的分类
一、监督学习,非监督学习,半监督学习和增强学习
监督学习
给机器的训练数据有“标记”或者“答案”
如MNIST数据集中指明每个数字图案代表的数字

常用的监督学习算法如下:
- k近邻
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
非监督学习
给机器的训练数据没有任何“标记”或者“答案”
非监督学习的意义:对没有“标记”的数据进行分类——聚类分析
非监督学习常用领域:
- 对数据进行降维处理
- 特征提取:移除非必要、无关的特征
- 特征压缩:多多个特征进行整合
- 降维的意义:方便可视化(高维转为低维)
- 异常检测
- 异常检测的目的:排除数据集中的与其他大多数据相背离的数据(如某个值过高或过低)
半监督学习
一部分数据有“标记”或者“答案”,另一部分则没有
通常都先使用无监督学习对数据进行处理,之后使用监督学习做模型的训练和预测
增强学习
根据周围环境的情况,采取行动,根据采取行动后的结果,再学习行动方式(如AlphaGo,自动驾驶)
二、在线学习和批量学习(离线学习)
批量学习
在进行学习并生成模型后不再对模型进行更新
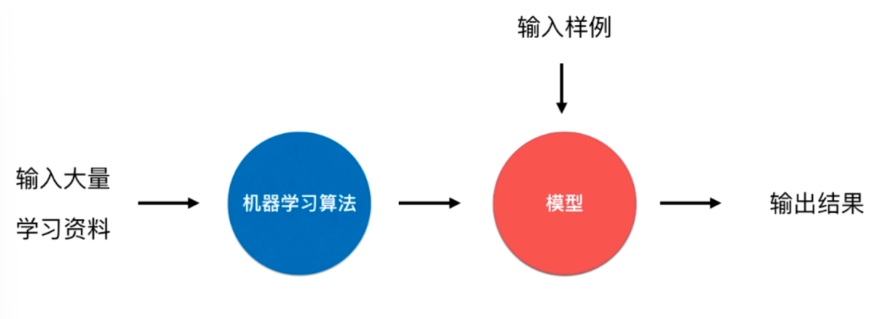
优点:简单
问题:如何适应环境变化
解决方案:定时重新批量学习
缺点:每次重新批量学习运算量巨大,在某些变化快的环境不允许
在线学习
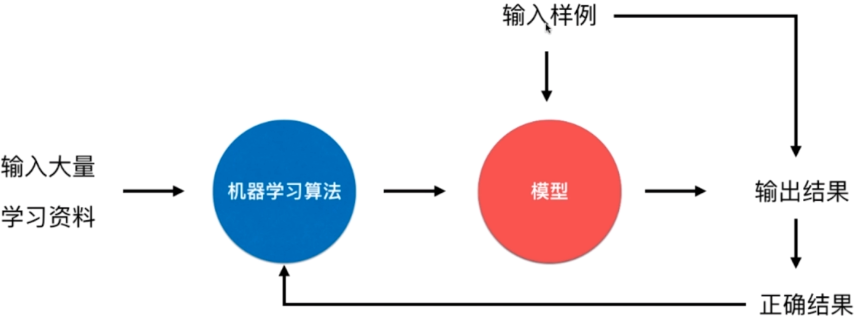
优点:及时反映新的环境变化
问题:新的数据带来的不好的变化(如生产环境异常导致的错误数据)
解决方案:需要加强对数据的监控
其他:也适用于数据量巨大,完全无法批量学习的环境
三、参数学习和非参数学习
参数学习
根据数据集为数据预测模型,如函数f(x)=a*x+b,一旦学习到了参数a和b,就不再需要原有的数据集
非参数学习
不对数据的模型进行过多的假设,非参数学习并不等于没有参数
把圈子变小,把语言变干净,把成绩往上提,把故事往心里收,现在想要的以后你都会有。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异