机器学习中的数据及任务
什么是机器学习?
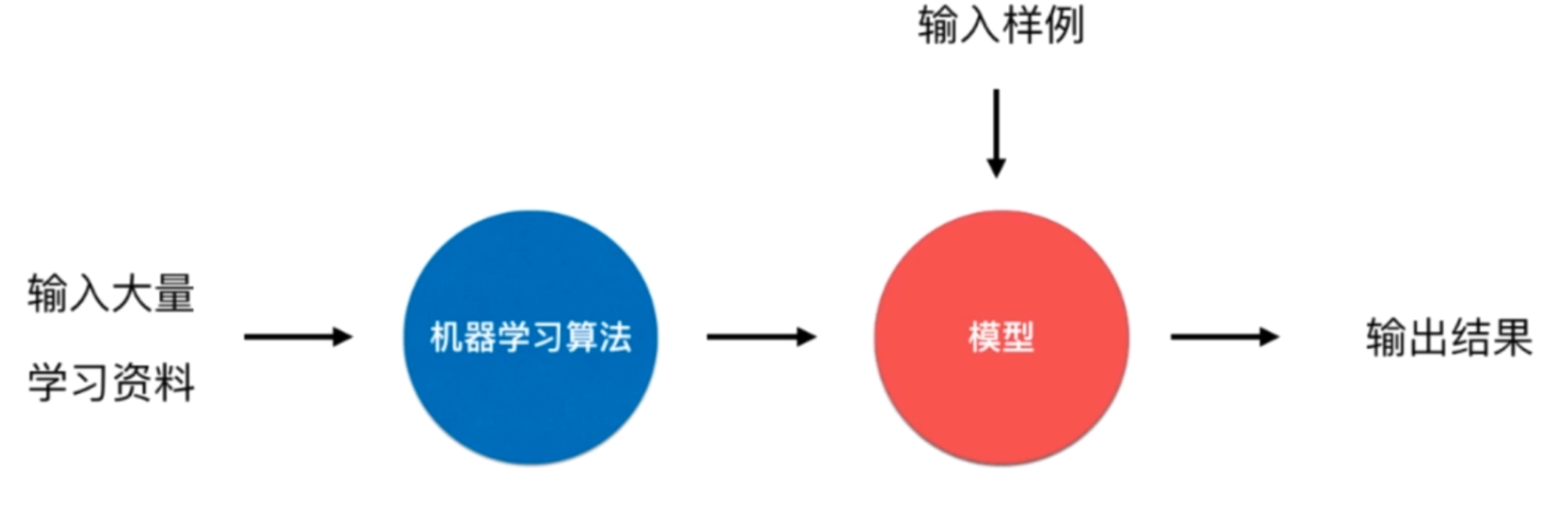
什么是数据?
以鸢尾花数据为例:

其中包含四个主要的信息(萼片(sepal)的长宽、花瓣(petal)的长宽)

根据以上数据大致可以分为三个种类,Iris-Setosa、Iris-Versicolour、Iris-Virginica
其数据的结构大致如下:

现有以下数据为例:
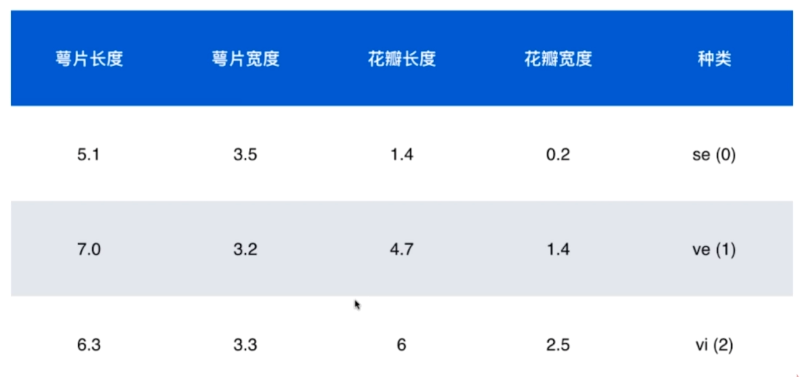
此处使用数字0,1,2在机器学习中分别简化表示三种类型。
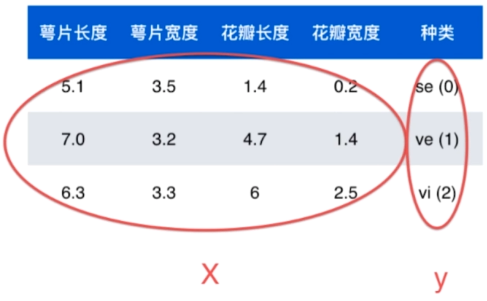
上面示例的数据整体叫数据集(data set),
其中每一行数据都被称为一个样本(sample),
除最后一列,每列表达样本的一个特征(feature)(例子中有4个特征),
最后一列,称为标记(label)
现将所有的特征表示为矩阵X,将所有标记表示为向量y
那么第i个样本行写作X ⁽ ⁱ ⁾(称作特征向量,一般为列向量),

现将所有特征向量转置即可得到整个数据集
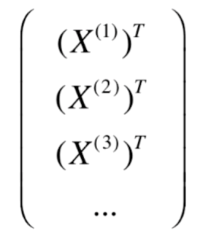
第i个样本的第j个特征值写作X ⁽ ⁱ ⁾ⱼ(i为上标,j为下标),
第i个样本的标记写作y⁽ ⁱ ⁾。
样本数据的本质就是在所有特征所组成的一个空间中的点,这个空间称为特征空间(feature space)。
分类任务的本质就是在特征空间中的切分,下图为两维的示例,在高维空间同理。
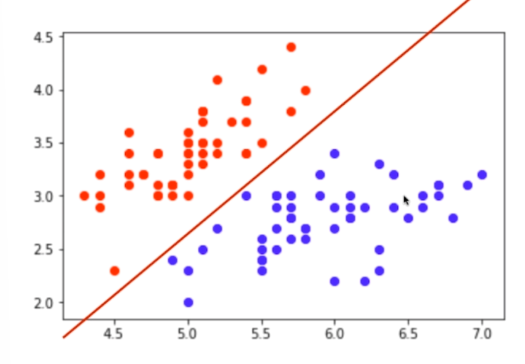
此外,特征也可以是抽象的,比如MNIST数据集中的手写数字,其中每个数字图像中的每一个像素点都是特征。
任务是什么?
其中监督学习的任务如下:
- 分类任务
- 二分类(判断是否为垃圾邮件)
- 多分类(数字识别,图像识别)
- 多标签分类(识别图片中的多类元素)
- 回归任务
- 结果为一个连续数字的值,而不是某个类别,如判断房屋价格(xx万)
- 一些情况下,回归任务可以简化为分类任务
把圈子变小,把语言变干净,把成绩往上提,把故事往心里收,现在想要的以后你都会有。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步