寒假学习 11 编程实现将 RDD 转换为 DataFrame
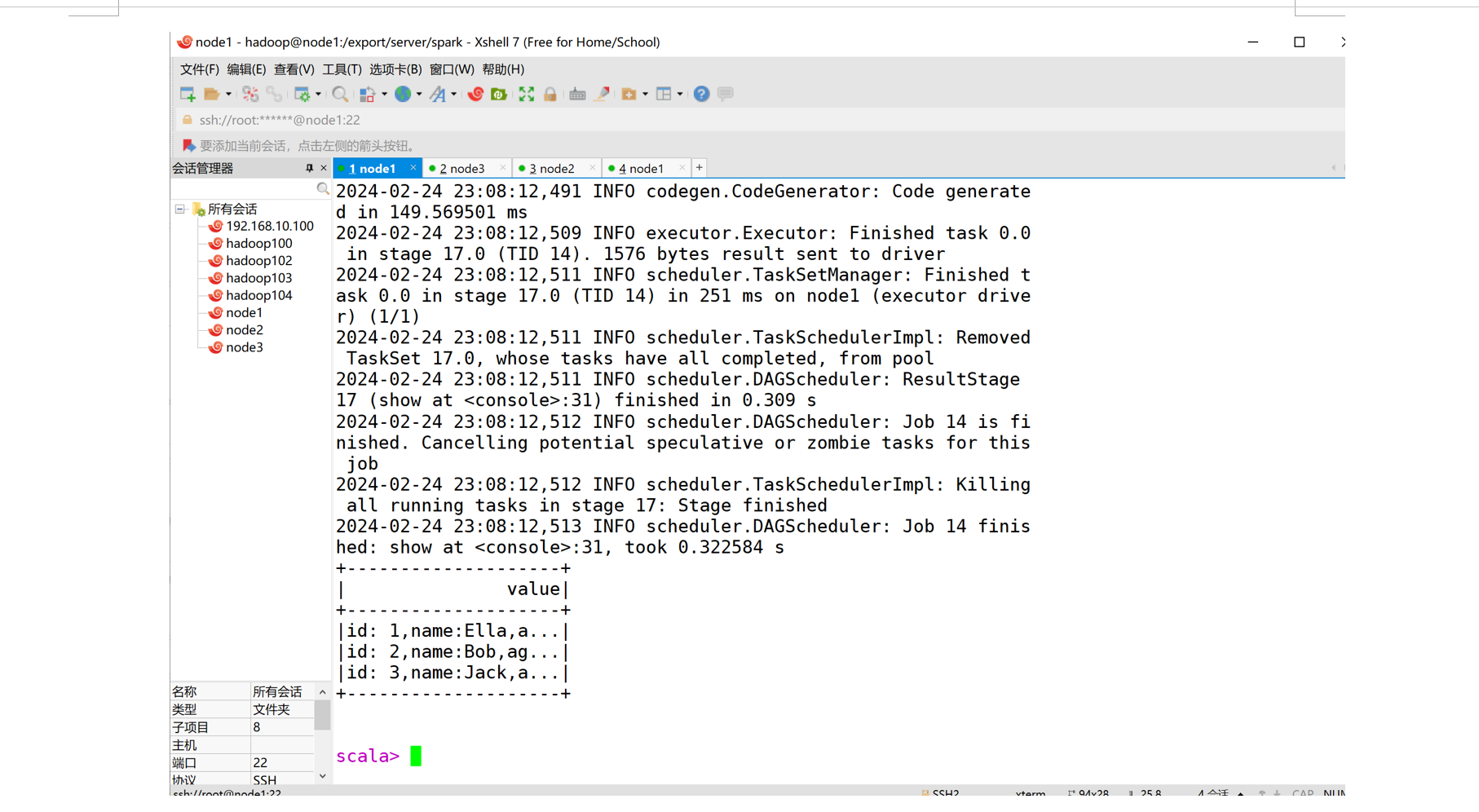
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> val peopleRDD = spark.sparkContext.textFile("file:///home/hadoop/桌面/employee.txt")
peopleRDD: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/桌面/employee.txt MapPartitionsRDD[55] at textFile at <console>:32
scala> val schemaString = "id name age"
schemaString: String = id name age
scala> val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))
fields: Array[org.apache.spark.sql.types.StructField] = Array(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true))
scala> val schema = StructType(fields)
schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true))
scala> val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim, attributes(2).trim))
rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[57] at map at <console>:34
scala> val peopleDF = spark.createDataFrame(rowRDD, schema)
peopleDF: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field]
scala> peopleDF.createOrReplaceTempView("people")
scala> val results = spark.sql("SELECT id,name,age FROM people")
results: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field]
scala> results.map(attributes => "id: " + attributes(0)+","+"name:"+attributes(1)+","+"age:"+attributes(2)).show()