安装spark
3. Spark 读取文件系统的数据
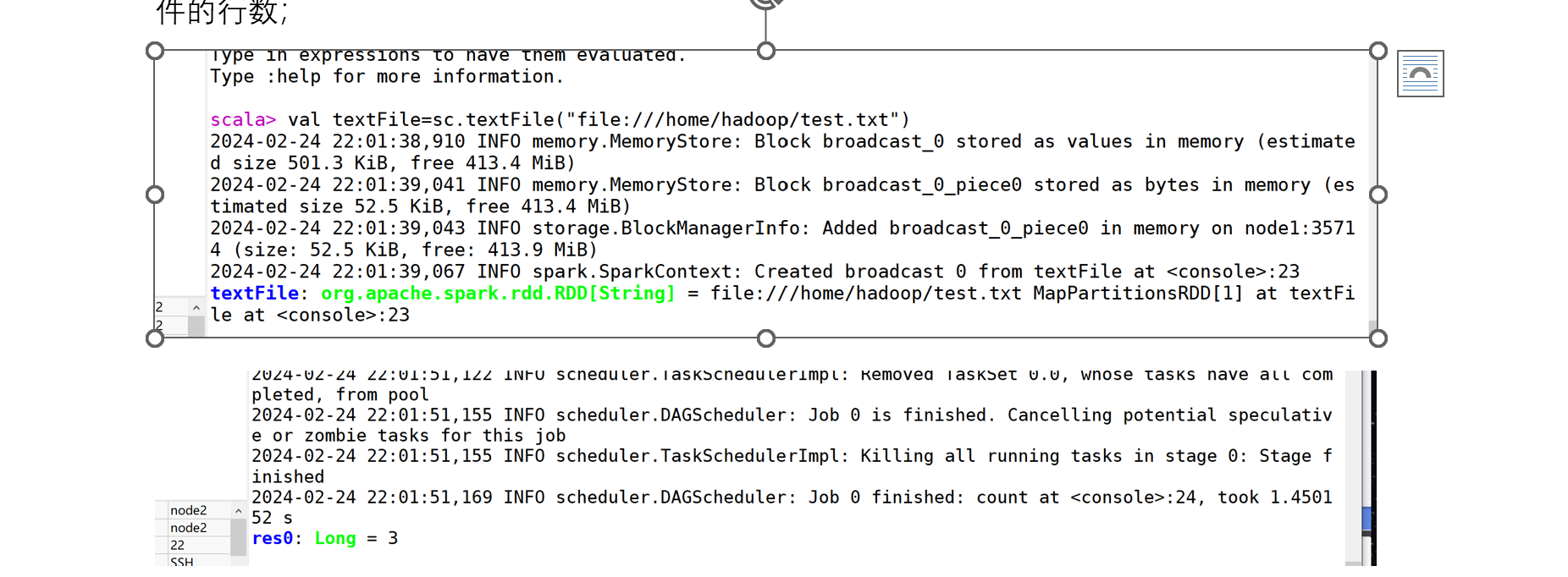
(1)在spark-shell 中读取Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文
件的行数;
(2)在 spark-shell 中读取HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;