

(1)ElasticSearch简介
1 ElasticSearch简介
1.1 是什么
ES是一个基于Lucene构建的开源、分布式、RESTFUL接口全文搜索引擎。还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,能够扩展至数以百计的服务器存储以及处理PB级别的数据。
1.2 作用
- 分布式搜索引擎和数据分析引擎
- 全文检索、结构化搜索以及聚合
- 海量数据近实时处理
1.3 使用场景
- 百度、维基百科、新闻、电商、Stack Overflow等
- 各大网站的用户行为日志(比如你搜个商品、你点击某个连接等)
- BI(Business Intelligence:商业智能),数据分析、挖掘
- Github
- ELK
2 逻辑设计
2.1 文档、类型、索引
- 索引(index):映射类型的容器,一个ES索引非常像关系型数据库,是独立的大量文档的集合。索引存储了所有映射类型的字段,还有一些其他设置。
- 文档类型(Type):文档的逻辑容器,类似于表格是行的容器。
- 文档(Document):ES是面向文档的,索引和搜索数据的最小单位是文档。ES的文档是由一个或者多个字段组成,类型于关系型数据库中的一行记录,但ES的文档是以JSON进行序列化保存的,每个JSON对象由多个字段组成,字段类型可以是布尔、数值、字符串、二进制、日期等数据格式。
2.1.1 Elastic7为什么取消type
Elasticsearch 官网提出的近期版本对 type 概念的演变情况如下:
在 5.X 版本中,一个 index 下可以创建多个 type;
在 6.X 版本中,一个 index 下只能存在一个 type;
在 7.X 版本中,直接去除了 type 的概念,就是说 index 不再会有 type。
因为 Elasticsearch 设计初期,是直接查考了关系型数据库的设计模式,存在了 type(数据表)的概念。
但是,其搜索引擎是基于 Lucene 的,这种 “基因”决定了 type 是多余的。 Lucene 的全文检索功能之所以快,是因为 倒序索引 的存在。
而这种 倒序索引 的生成是基于 index 的,而并非 type。多个type 反而会减慢搜索的速度。
为了保持 Elasticsearch “一切为了搜索” 的宗旨,适当的做些改变(去除 type)也是无可厚非的,也是值得的。
2.2 集群、节点和分片
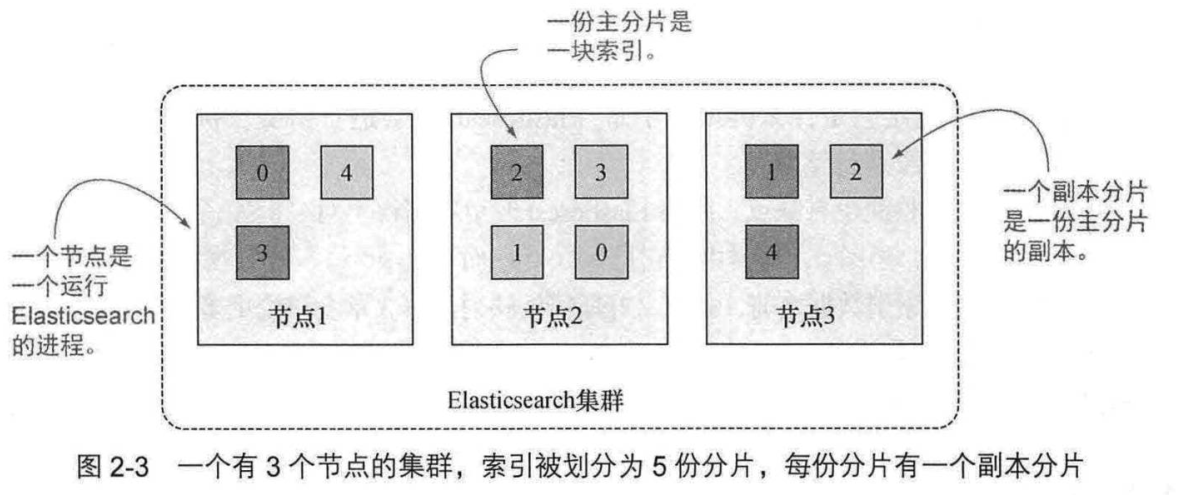
-
集群:多个节点集合,为了保证高可用,当部分节点失效时,ES依旧可用。
-
节点:一个ElasticSearch实例,
-
分片:分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿.
- 主分片:用来解决数据水平扩展的问题
- 点上可以有主分片,也可以没有主分片
- 主分片在索引创建的时候确定,后续不允许修改。除非 Reindex 操作进行修改
- 副分片:用来备份数据,提高数据的高可用性。副本分片是主分片的拷贝
- 副本分片数,可以动态调整
- 增加副本数,可以一定程度上提高服务读取的吞吐和可用性
实战建议:对生产环境中,分片设置很重要,需要最好容量评估与规划
- 根据数据容量评估分配数,设置过小,后续无法水平扩展;单分片数据量太大,也容易导致数据分片耗时严重
- 分片数设置如果太大,会导致资源浪费,性能降低;同时也会影响搜索结果打分和搜索准确性
索引评估,每个索引下面的单分片数不用太大。如何评估呢?比如这个索引 100 G 数据量,那设置 10 个分片,平均每个分片数据量就是 10G 。每个分片 10 G 数据量这么大,耗时肯定严重。所以根据评估的数据量合理安排分片数即可。如果需要调整主分片数,那么需要进行 reindex 等迁索引操作。
对大数据集, 我们非常鼓励你为索引多分配些分片--当然也要在合理范围内. 上面讲到的每个分片 最好不超过30GB的原则依然使用. 不过, 你最好还是能描述出每个节点上只放一个索引分片的必要性. 在开始阶段, 一个好的方案是 根据你的节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数 最多不超过9(3x3)个. - 主分片:用来解决数据水平扩展的问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报