使用simhash以及海明距离判断内容相似程度
算法简介
SimHash也即相似hash,是一类特殊的信息指纹,常用来比较文章的相似度,与传统hash相比,传统hash只负责将原始内容尽量随机的映射为一个特征值,并保证相同的内容一定具有相同的特征值。而且如果两个hash值是相等的,则说明原始数据在一定概率下也是相等的。但通过传统hash来判断文章的内容是否相似是非常困难的,原因在于传统hash只唯一标明了其特殊性,并不能作为相似度比较的依据。
SimHash最初是由Google使用,其值不但提供了原始值是否相等这一信息,还能通过该值计算出内容的差异程度。
算法原理
simhash是由 Charikar 在2002年提出来的,参考 《Similarity estimation techniques from rounding algorithms》 。 介绍下这个算法主要原理,为了便于理解尽量不使用数学公式,分为这几步:
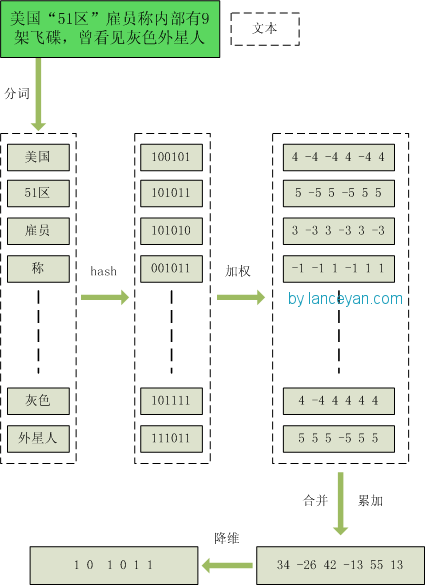
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
原理图:
我们可以来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过比较差异的位数就可以得到两串文本的差异,差异的位数,称之为“海明距离”,通常认为海明距离<3的是高度相似的文本。
算法实现
这里的代码引用自博客:http://my.oschina.net/leejun2005/blog/150086 ,这里表示感谢。
代码实现中使用Hanlp代替了原有的分词器。
package com.emcc.changedig.extractengine.util; /** * Function: simHash 判断文本相似度,该示例程支持中文<br/> * date: 2013-8-6 上午1:11:48 <br/> * @author june * @version 0.1 */ import java.io.IOException; import java.math.BigInteger; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import com.hankcs.hanlp.seg.common.Term; public class SimHash { private String tokens; private BigInteger intSimHash; private String strSimHash; private int hashbits = 64; public SimHash(String tokens) throws IOException { this.tokens = tokens; this.intSimHash = this.simHash(); } public SimHash(String tokens, int hashbits) throws IOException { this.tokens = tokens; this.hashbits = hashbits; this.intSimHash = this.simHash(); } HashMap<String, Integer> wordMap = new HashMap<String, Integer>(); public BigInteger simHash() throws IOException { // 定义特征向量/数组 int[] v = new int[this.hashbits]; String word = null; List<Term> terms = SegmentationUtil.ppl(this.tokens); for (Term term : terms) { word = term.word; // 将每一个分词hash为一组固定长度的数列.比如 64bit 的一个整数. BigInteger t = this.hash(word); for (int i = 0; i < this.hashbits; i++) { BigInteger bitmask = new BigInteger("1").shiftLeft(i); // 建立一个长度为64的整数数组(假设要生成64位的数字指纹,也可以是其它数字), // 对每一个分词hash后的数列进行判断,如果是1000...1,那么数组的第一位和末尾一位加1, // 中间的62位减一,也就是说,逢1加1,逢0减1.一直到把所有的分词hash数列全部判断完毕. if (t.and(bitmask).signum() != 0) { // 这里是计算整个文档的所有特征的向量和 // 这里实际使用中需要 +- 权重,比如词频,而不是简单的 +1/-1, v[i] += 1; } else { v[i] -= 1; } } } BigInteger fingerprint = new BigInteger("0"); StringBuffer simHashBuffer = new StringBuffer(); for (int i = 0; i < this.hashbits; i++) { // 4、最后对数组进行判断,大于0的记为1,小于等于0的记为0,得到一个 64bit 的数字指纹/签名. if (v[i] >= 0) { fingerprint = fingerprint.add(new BigInteger("1").shiftLeft(i)); simHashBuffer.append("1"); } else { simHashBuffer.append("0"); } } this.strSimHash = simHashBuffer.toString(); return fingerprint; } private BigInteger hash(String source) { if (source == null || source.length() == 0) { return new BigInteger("0"); } else { char[] sourceArray = source.toCharArray(); BigInteger x = BigInteger.valueOf(((long) sourceArray[0]) << 7); BigInteger m = new BigInteger("1000003"); BigInteger mask = new BigInteger("2").pow(this.hashbits).subtract( new BigInteger("1")); for (char item : sourceArray) { BigInteger temp = BigInteger.valueOf((long) item); x = x.multiply(m).xor(temp).and(mask); } x = x.xor(new BigInteger(String.valueOf(source.length()))); if (x.equals(new BigInteger("-1"))) { x = new BigInteger("-2"); } return x; } } /** * 计算海明距离 * * @param other * 被比较值 * @return 海明距离 */ public int hammingDistance(SimHash other) { BigInteger x = this.intSimHash.xor(other.intSimHash); int tot = 0; while (x.signum() != 0) { tot += 1; x = x.and(x.subtract(new BigInteger("1"))); } return tot; } public int getDistance(String str1, String str2) { int distance; if (str1.length() != str2.length()) { distance = -1; } else { distance = 0; for (int i = 0; i < str1.length(); i++) { if (str1.charAt(i) != str2.charAt(i)) { distance++; } } } return distance; } public List<BigInteger> subByDistance(SimHash simHash, int distance) { // 分成几组来检查 int numEach = this.hashbits / (distance + 1); List<BigInteger> characters = new ArrayList<BigInteger>(); StringBuffer buffer = new StringBuffer(); for (int i = 0; i < this.intSimHash.bitLength(); i++) { // 当且仅当设置了指定的位时,返回 true boolean sr = simHash.intSimHash.testBit(i); if (sr) { buffer.append("1"); } else { buffer.append("0"); } if ((i + 1) % numEach == 0) { // 将二进制转为BigInteger BigInteger eachValue = new BigInteger(buffer.toString(), 2); buffer.delete(0, buffer.length()); characters.add(eachValue); } } return characters; } public static void main(String[] args) throws IOException { String s = "传统的 hash 算法只负责将原始内容尽量均匀随机地映射为一个签名值," + "原理上相当于伪随机数产生算法。产生的两个签名,如果相等,说明原始内容在一定概 率 下是相等的;" + "如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节," + "所产生的签名也很可能差别极大。从这个意义 上来 说,要设计一个 hash 算法," + "对相似的内容产生的签名也相近,是更为艰难的任务,因为它的签名值除了提供原始内容是否相等的信息外," + "还能额外提供不相等的 原始内容的差异程度的信息。"; SimHash hash1 = new SimHash(s, 64); // 删除首句话,并加入两个干扰串 s = "原理上相当于伪随机数产生算法。产生的两个签名,如果相等,说明原始内容在一定概 率 下是相等的;" + "如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节," + "所产生的签名也很可能差别极大。从这个意义 上来 说,要设计一个 hash 算法," + "对相似的内容产生的签名也相近,是更为艰难的任务,因为它的签名值除了提供原始内容是否相等的信息外," + "干扰1还能额外提供不相等的 原始内容的差异程度的信息。"; SimHash hash2 = new SimHash(s, 64); // 首句前添加一句话,并加入四个干扰串 s = "imhash算法的输入是一个向量,输出是一个 f 位的签名值。为了陈述方便," + "假设输入的是一个文档的特征集合,每个特征有一定的权重。" + "传统干扰4的 hash 算法只负责将原始内容尽量均匀随机地映射为一个签名值," + "原理上这次差异有多大呢3相当于伪随机数产生算法。产生的两个签名,如果相等," + "说明原始内容在一定概 率 下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息," + "因为即使原始内容只相差一个字节,所产生的签名也很可能差别极大。从这个意义 上来 说," + "要设计一个 hash 算法,对相似的内容产生的签名也相近,是更为艰难的任务,因为它的签名值除了提供原始" + "内容是否相等的信息外,干扰1还能额外提供不相等的 原始再来干扰2内容的差异程度的信息。"; SimHash hash3 = new SimHash(s, 64); int dis12 = hash1.getDistance(hash1.strSimHash, hash2.strSimHash); System.out.println(hash1.strSimHash); System.out.println(hash2.strSimHash); System.out.println(dis12); System.out.println("============================================"); int dis13 = hash1.getDistance(hash1.strSimHash, hash3.strSimHash); System.out.println(hash1.strSimHash); System.out.println(hash3.strSimHash); System.out.println(dis13); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号