数据结构(二):排序算法
一、 排序算法概述
日常的程序设计中,排序是很常见的需求,把数据元素按照一定的规则进行排序,比如淘宝上的货品按照上架日期排序,百度的搜索按照最新的内容排序。
二、 冒泡排序
2.1排序原理
- 比较相邻的元素,如果前一个元素比后一个元素大,就交换两个元素的位置
- 第一次冒泡,最大的元素会被交换到最后的位置,第二次冒泡,第二大的元素会被交换到倒数第二的位置,以此类推,每次冒泡后参与冒泡的数量都会减少一个,直到最后参与冒泡的个数为1,则此时排序完成
2.2排序演示图

2.3代码实现
|
import java.util.Arrays;
public class Bubble {
public static void main(String[] args) { Integer[] list = new Integer[] {5,1,3,2,4}; Bubble.sort(list); System.out.println(Arrays.toString(list)); }
/** * 冒泡核心排序算法 * @param col */ private static void sort(Comparable[] col) { for(int i=col.length-1;i>0;i--) {//每次冒泡完都会减少一个数参与下一轮冒泡,直到剩最后一个数为止 for(int j=0;j<i;j++) {//前后元素的比较,由于每次冒泡完减少一个数参与比较,故j跟着i的数量走 if(bigger(col[j], col[j+1])) { switchPos(col,j,j+1); } } } }
/** * 前后元素的比较 * @param a * @param b * @return */ private static boolean bigger(Comparable a,Comparable b) { return a.compareTo(b)>0; }
/** * 元素位置的交换 * @param col * @param i * @param j */ private static void switchPos(Comparable[] col,int a,int b) { Comparable t = col[a]; col[a] = col[b]; col[b] = t; } } |
2.4时间复杂度分析
冒泡排序中,元素交换的执行次数为
(n-1)+(n-2)+…+2+1 = n^2/2-n/2
元素参与比较的执行次数为
(n-1)+(n-2)+…+2+1 = n^2/2-n/2
故冒泡的算法时间复杂度相加为n^2-n,根据大O计数法为O(n^2)
三、 选择排序
3.1排序原理
- 对于需要排序的数据对象中,假设第一个索引处的值为最小值,遍历过程中,当前索引处的值大于其他索引处的值时,认为其他索引处的值为最小值,并互相交换位置,直到遍历至数据对象的导数第二个数为止
3.2排序演示图
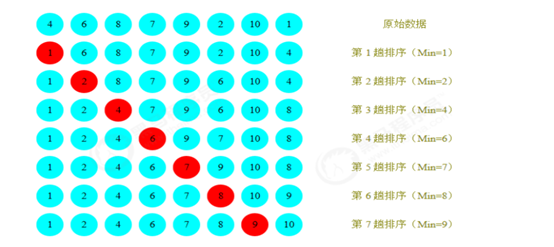
3.3代码实现
|
import java.util.Arrays;
public class Select {
public static void main(String[] args) { Integer[] list = new Integer[] {5,1,3,2,4}; Select.sort(list); System.out.println(Arrays.toString(list)); }
/** * 选择核心排序算法 * @param col */ private static void sort(Comparable[] col) { for(int i=0;i<col.length-1;i++) { int minIndex = i; for(int j=i+1;j<col.length;j++) { if(bigger(col[minIndex],col[j])) { minIndex = j; } } switchPos(col, i, minIndex); } }
/** * 前后元素的比较 * @param a * @param b * @return */ private static boolean bigger(Comparable a,Comparable b) { return a.compareTo(b)>0; }
/** * 元素位置的交换 * @param col * @param i * @param j */ private static void switchPos(Comparable[] col,int a,int b) { Comparable temp = col[a]; col[a] = col[b]; col[b] = temp; } } |
3.4时间复杂度分析
选择排序使用双层for循环,外层是数据交换,里层是数据比较
数据比较的次数是:(n-1)+(n-2)+…+2+1 = n^2/2-n/2
数据交换的次数是:n-1
故冒泡的算法时间复杂度相加为n^2/2+n/2-1,根据大O计数法为O(n^2)
四、 插入排序
4.1排序原理
- 把待排序的数据元素分成已排序和待排序的两组
- 找到未排序的第一个元素,向已排序的数据元素中插入
- 倒叙遍历已经排序的元素,直到找到比待插入元素小的元素,将待插入元素放在此位置,其余元素向后移动一位
4.2排序演示图

4.3代码实现
|
import java.util.Arrays;
public class Insert {
public static void main(String[] args) { Integer[] list = new Integer[] {5,1,3,2,4}; Insert.sort(list); System.out.println(Arrays.toString(list)); }
/** * 插入核心排序算法 * @param col */ private static void sort(Comparable[] col) { //外层为未排序对象 for(int i=1;i<col.length;i++) { //里层为已排序对象的倒序 for(int j=i;j>0;j--) { if(bigger(col[j-1], col[j])) { switchPos(col, j-1, j); }else { break; } } } }
/** * 前后元素的比较 * @param a * @param b * @return */ private static boolean bigger(Comparable a,Comparable b) { return a.compareTo(b)>0; }
/** * 元素位置的交换 * @param col * @param i * @param j */ private static void switchPos(Comparable[] col,int a,int b) { Comparable temp = col[a]; col[a] = col[b]; col[b] = temp; } } |
4.4时间复杂度分析
插入排序使用双层for循环,外层是未排序数据元素,里层是已排序数据元素
数据比较的次数是:(n-1)+(n-2)+…+2+1 = n^2/2-n/2
数据交换的次数是:(n-1)+(n-2)+…+2+1 = n^2/2-n/2
故冒泡的算法时间复杂度相加为n^2-n,根据大O计数法为O(n^2)
五、 希尔排序
5.1排序原理
- 选定一个增长量h,对数据对象按h的间隔进行分组,并对分组后的数据进行插入排序
- 减小增长量h直到剩下1,即排序成功
- 增长量h的选定无固定规则,经过科学论证h的规则存在多种可行的可能,没有绝对最优的规则,一般选择数组的长度n/2作为初始值,随后也是按n=n/2做递减
- 假设在插入排序中,有序的数组为2,3,5,6,无序数组为1,8,那么1和8的插入每次都得遍历2,3,5,6后才能做插入,而设定了增长量后,可以有效的减少遍历的次数,故希尔排序是插入排序的优化
5.2排序演示图

5.3代码实现
|
import java.util.Arrays;
public class Hill {
public static void main(String[] args) { Integer[] list = new Integer[] {5,1,3,2,4}; Hill.sort(list); System.out.println(Arrays.toString(list)); }
/** * 希尔核心排序算法 * @param col */ private static void sort(Comparable[] col) { int n = col.length; int h = 1; //初始增量 while(h<n/2) { h = h*2+1; }
while(h>=1) { //外层先找到待插入的元素,待插入的元素以h为起始索引 for(int i=h;i<n;i++) { //里层对待插入的元素,往前按h间隔找到待插入排序的数进行插入排序 for(int j=i;j>=h;j=j-h) { if(bigger(col[j-h],col[j])) { switchPos(col, j-h, j); } } h = h/2; } } }
/** * 前后元素的比较 * @param a * @param b * @return */ private static boolean bigger(Comparable a,Comparable b) { return a.compareTo(b)>0; }
/** * 元素位置的交换 * @param col * @param i * @param j */ private static void switchPos(Comparable[] col,int a,int b) { Comparable temp = col[a]; col[a] = col[b]; col[b] = temp; } } |
5.4时间复杂度分析
希尔排序的时间复杂度无法做清晰的计算,有人根据大量数据得出平均时间复杂度为O(n^1.3),我们可以做个实验如下,对于10w的大数据量情况下的排序,是不是希尔排序要优于插入排序


通过实际的测验证明,希尔排序的性能确实是优于插入排序的
六、 归并排序
6.1排序原理

如图,归并算法采用分治的思想,主要通过如下三步实现数据有序
- 将数据元素进行对半拆分,直到拆成只有1个数据元素的n组数据
- 对相邻的两组数进行排序,使之有序并合并
- 不断重复上一步,直到合成了一组有序的数据
- 归并排序是一种空间换时间的算法
6.2排序演示图

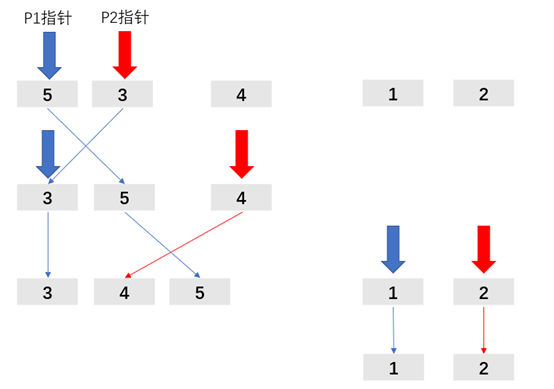


6.3代码实现
|
import java.util.Arrays;
public class Merge {
//辅助数组声明 private static Comparable[] assist;
public static void main(String[] args) { Integer[] list = new Integer[] {5,1,3,2,4}; Merge.sort(list); System.out.println(Arrays.toString(list)); }
/** * 归并核心排序算法 * @param col */ public static void sort(Comparable[] col) { int low = 0; int high = col.length-1; assist = new Comparable[col.length]; sort(col,low,high); }
private static void sort(Comparable[] col,int low,int high) { if(high<=low) { return; }
int mid = low + (high-low)/2;
//对左子组进行递归排序 sort(col,low,mid);
//对右子组进行递归排序 sort(col,mid+1,high);
//归并排序 merge(col,low,mid,high); }
/** * 对已排序的几组数据进行归并排序 * @param col * @param low * @param mid * @param high */ private static void merge(Comparable[] col, int low, int mid, int high) { int index = low; int p1 = low; //左右子组比对的左指针 int p2 = mid+1; //左右子组比对的右指针
//左右指针分别走,对比两个指针下的数据,小的往辅助数组里放 while(p1<=mid && p2<=high) { int leftNum = (int) col[p1]; int rightNum = (int) col[p2]; System.out.println("左数:"+leftNum+" 右数:"+rightNum); if(bigger(leftNum, rightNum)) { assist[index++] = col[p2++]; }else { assist[index++] = col[p1++]; } }
//右指针的数据比较完了,把左指针剩余的数填充到辅助数组中 while(p1<=mid) { assist[index++] = col[p1++]; }
//左指针的数据比较完了,把右指针剩余的数填充到辅助数组中 while(p2<=high) { assist[index++] = col[p2++]; }
for(int i=low;i<=high;i++) { col[i]=assist[i]; } }
/** * 前后元素的比较 * @param a * @param b * @return */ private static boolean bigger(Comparable a,Comparable b) { return a.compareTo(b)>0; }
/** * 元素位置的交换 * @param col * @param i * @param j */ private static void switchPos(Comparable[] col,int a,int b) { Comparable temp = col[a]; col[a] = col[b]; col[b] = temp; } } |
6.4时间复杂度分析
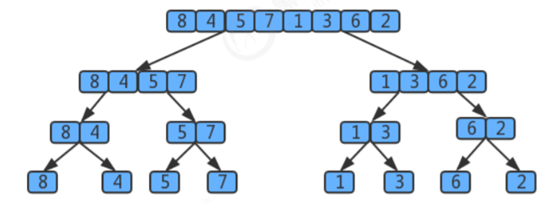
假设数据元素的个数为N,那么拆分有logN层,每层的最坏情况都是比较N次,所以算法复杂度为logN*N+logN,根据大O计数法为O(N*logN)
七、 快速排序
7.1排序原理

- 从数据元素中取一个值作为分界值,选取小于该分界值的元素作为左子组,选取大于该分解值的元素作为右子组
- 左右子组一直重复上述操作,直到子组的个数为1
7.2排序演示图



7.3代码实现
|
package com.data.struct.common.sort.quick;
import java.util.Arrays; import com.data.struct.common.sort.merge.Merge;
public class Quick {
public static void main(String[] args) { //Integer[] list = new Integer[] { 6,7,8,9,10,2,3,1}; Integer[] list = new Integer[] {3,1,2}; Quick.sort(list); System.out.println(Arrays.toString(list)); }
/** * 归并核心排序算法 * * @param col */ public static void sort(Comparable[] col) { int low = 0; int high = col.length - 1; sort(col, low, high); }
private static void sort(Comparable[] col, int low, int high) { if (high <= low) { return; }
System.out.println(Arrays.toString(col));
int quickIndex = quick(col, low, high);
// 对左子组进行递归排序 sort(col, low, quickIndex-1);
// 对右子组进行递归排序 sort(col, quickIndex+1, high); }
/** * 对已排序的几组数据进行归并排序 * * @param col * @param low * @param mid * @param high */ private static int quick(Comparable[] col, int low, int high) { //设定一个基准值,一般以第一个数为准 Comparable value = col[low]; //左指针起始位置 int leftPointer = low; //右指针起始位置 int rightPointer = high + 1;
while(true) { boolean flag = bigger(col[--rightPointer],value); while(flag) { //从右往左扫指针,发现比基准值小的值则停下 if(rightPointer<=low) { break; } }
while(bigger(value,col[++leftPointer])) { //从左往右扫指针,发现比基准值大的值则停下 if(leftPointer>=high) { break; } }
if(leftPointer>=rightPointer) { //左指针和右指针相遇,说明全部元素已扫描完成,跳出while循环 break; }else { switchPos(col, leftPointer, rightPointer); //左指针和右指针没相遇前,说明元素还没扫描完成,此时符合条件的元素交换位置 } }
//此时左边的元素小于基准值,右边的元素大于基准值,此时交换基准值和左右指针重叠处的值,基准值所在的索引,为新分组数据的分界线 switchPos(col, low, rightPointer); return rightPointer; }
/** * 前后元素的比较 * * @param a * @param b * @return */ private static boolean bigger(Comparable a, Comparable b) { return a.compareTo(b) > 0; }
/** * 元素位置的交换 * * @param col * @param i * @param j */ private static void switchPos(Comparable[] col, int a, int b) { Comparable temp = col[a]; col[a] = col[b]; col[b] = temp; } } |
7.4时间复杂度分析
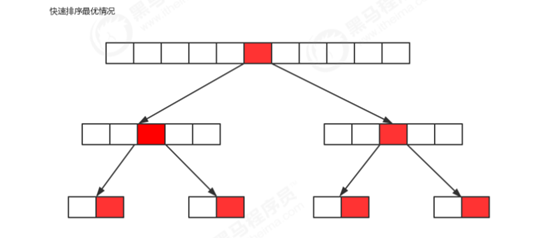
假设每次选中的基准值都是中位数,则会出现如图的情况,切分次数为logN次,每次交换元素的操作为N/2,所以最优情况下的算法复杂度为N/2*logN次,根据大O计算法推算出为O(N*logN)
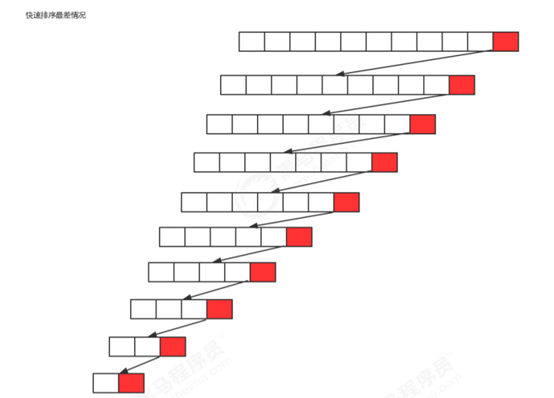
假设每次选中的基准值都是最大值或最小值,则每次左或右指针都得全量扫描,即N次,切分次数因此也需要N次,如果有数字为4,1,2,3,那么每次快排的结果如下
4123
3124
2134
1234
所以最坏情况下的快排结果为O(N^2)
7.5快速排序和归并排序的区别
- 归并排序是将若干数据元素切割成了最细粒度的左右子组,并对相邻子组进行排序,并合并。快速排序是将若干数据元素切割成了有序的左右子组,这样当所有左右子组都有序时,整个数据元素对象也就有序了。
- 在归并排序中,一个数组被等分为两半,递归调用发生在排序之前,在快速排序中,切分数组的位置取决于数组的内容,递归调用发生在排序之后
八、 排序的稳定性
在一组数据元素中,A和B相等,并且A元素排在B元素后面,经过一轮排序后,值相等的A和B的位置依然不变,此时排序是稳定的。
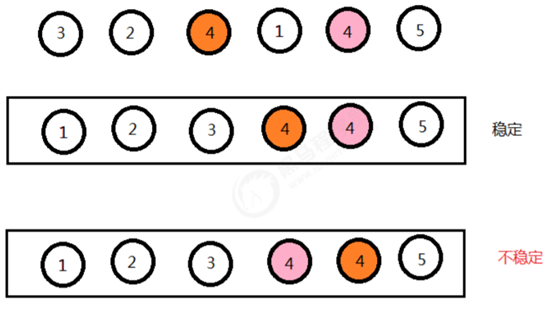
稳定性的意义:
如果一组数据元素只需要根据一种排序方式进行排序,此时排序稳定性是没有意义的,多种方式的排序,如几件商品同时进行价格,销量,库存等方式的排序,则此时排序稳定性是有意义的,如下:
按价格从高到低排序

按销量从高到低排序
排序算法的稳定性:
冒泡排序(稳定算法):冒泡排序中,通过相邻元素的大小比较,只有当前一个元素比后一个元素大时才交换位置,所以相等元素的位置保持不变,所以冒泡排序是稳定的算法
选择排序(不稳定算法):选择排序中,是假设第一个数为最小的,往后遍历发现比该数小的则交换位置,在5,6,5,2这一组数中,当第一个数遍历至元素2时,会发生元素交换,此时变成了2,6,5,5
由此判断选择排序是不稳定的
希尔排序(不稳定算法):希尔排序是按照一定增长量进行排序的算法,假设有一组数3,3,1,5,希尔的增长量为2,则在第一次插入排序后变成了1,3,3,5,由此判断希尔排序是不稳定的
归并排序(稳定算法):归并算法是虽然将数据元素拆分成n对,并且对相邻组的元素进行排序,但是只有在发生左指针扫到的元素,大于右指针扫的元素时,才将小的元素填充到辅助数组中
相等元素不会发生操作,所以归并排序是稳定的
快速排序(不稳定算法):快速排序是找一个基准值,左指针扫到比基准值小的放左边,右指针扫到比基准值大的放右边,若基准值找的数据元素中的中位数,如 4,3,2,2,1
第一轮快排后的位置是1,2,2,3,4,由此判断快速排序是不稳定的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号