搭建本地知识库
目录
搭建知识库需要安装嵌入模型,将文件交给嵌入模型处理完后,会将结果存入向量数据库,向量数据库由软件提供,不需要安装,然后由对话大模型调用向量数据库里面的处理结果。
- 嵌入模型:搭建知识库时,通常需要使用嵌入模型。它的作用是将文本数据(从文件解析提取出来的内容等)转化为向量表示,这些向量能够捕捉文本的语义信息,便于后续在向量空间中进行相似度计算等操作 。不过,并非所有嵌入模型都需要安装,有些模型可以通过API调用,比如OpenAI的Embedding API。
- 文件解析:在将文件内容交给嵌入模型处理之前,一般需要先进行文件解析,将不同格式(如PDF、Word等)的文件转化为文本格式,以便嵌入模型处理。这一步骤和嵌入模型的应用紧密相关,但属于不同的处理环节。
- 向量数据库:向量数据库用于存储由嵌入模型生成的向量数据。有些向量数据库确实不需要安装,例如云服务形式的向量数据库,用户通过API或特定接口即可使用。但也有一些向量数据库需要本地安装部署,像Milvus等,用户可以根据自身需求、数据规模、隐私要求等因素选择合适的向量数据库。
- 对话大模型调用:通常是基于知识库(向量数据库存储的向量等数据 )进行检索和匹配,为对话大模型提供相关的上下文信息,辅助大模型生成更准确、更符合需求的回答 ,并非简单的直接调用。在实际应用中,会有一个检索和融合的过程,比如根据用户问题生成向量,在向量数据库中检索相似向量对应的文本,再将这些文本作为补充信息与问题一起输入给大模型。
使用CherryStudio搭建本地知识库
CherryStudio 不支持设置向量数据库,使用的是软件自带的向量数据库。所以这种方式搭建的知识库只能个人使用。
新建知识库
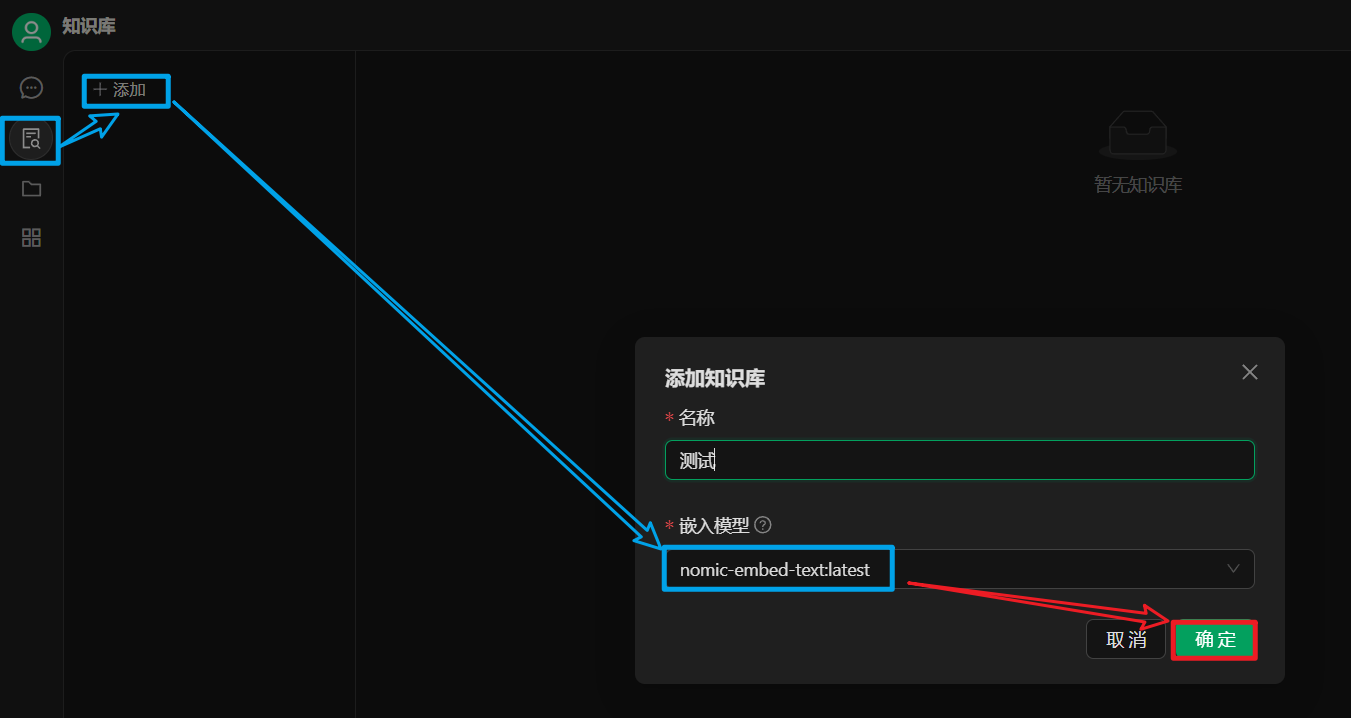
在 CherryStudio 左侧工具栏,点击知识库图标,点击添加,填写知识库名称,并选择下载好的嵌入模型,点击确定。
向知识库添加文件
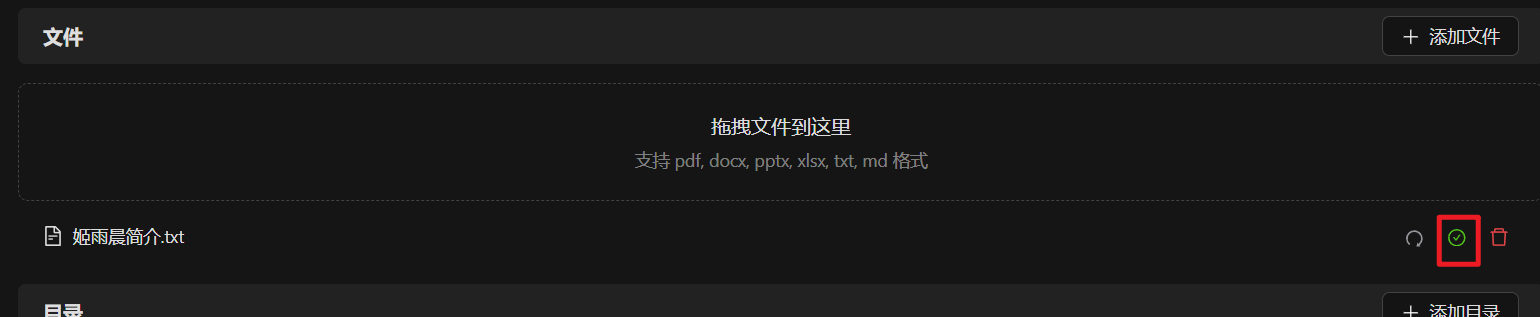
向知识库添加文件,并等待文件向量化完成
在对话中开启知识库支持
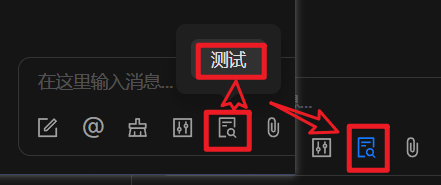
新建一个对话,然后启用知识库,选择刚才新建的知识库。
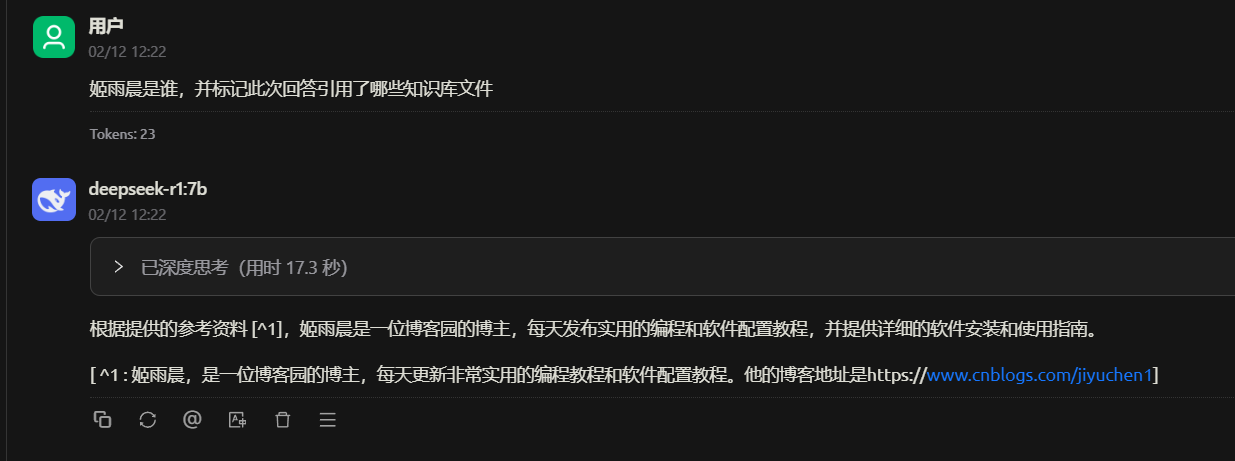
验证效果

使用AnythingLLM搭建本地知识库
安装AnythingLLM
访问AnythingLLM 官网,下载并安装
- AnythingLLM 官网:https://anythingllm.com/desktop
设置AnythingLLM
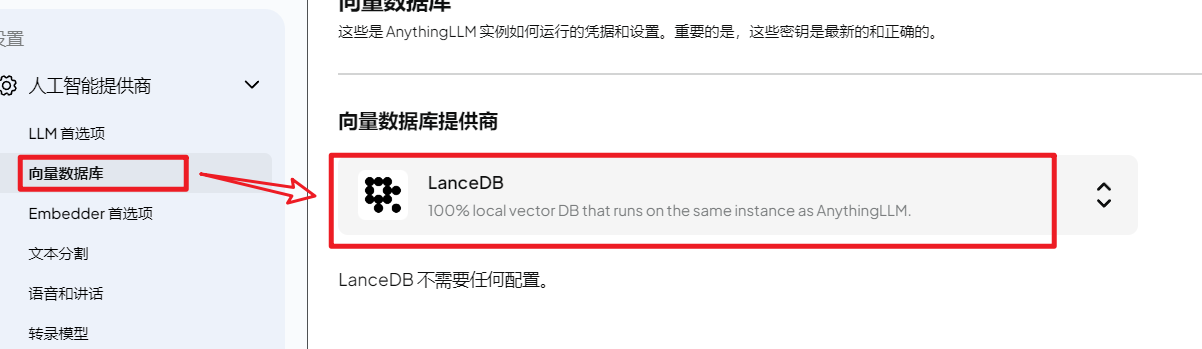
进入全局设置,设置 对话模型、向量数据库、和嵌入模型。
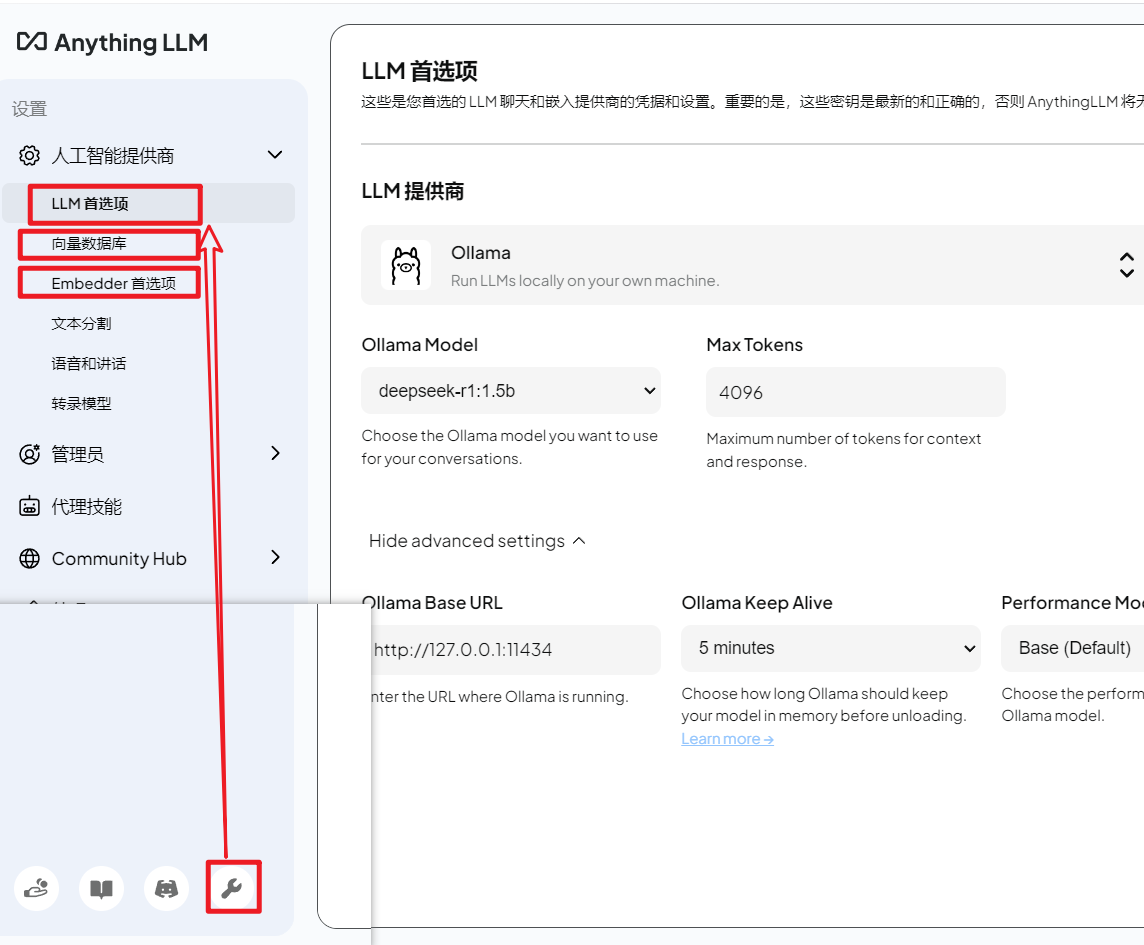
配置对话模型:这里选择前面使用ollama下载并部署的deepseek1.5B模型,如果有其他云端大模型api-key可以直接配置云端大模型。
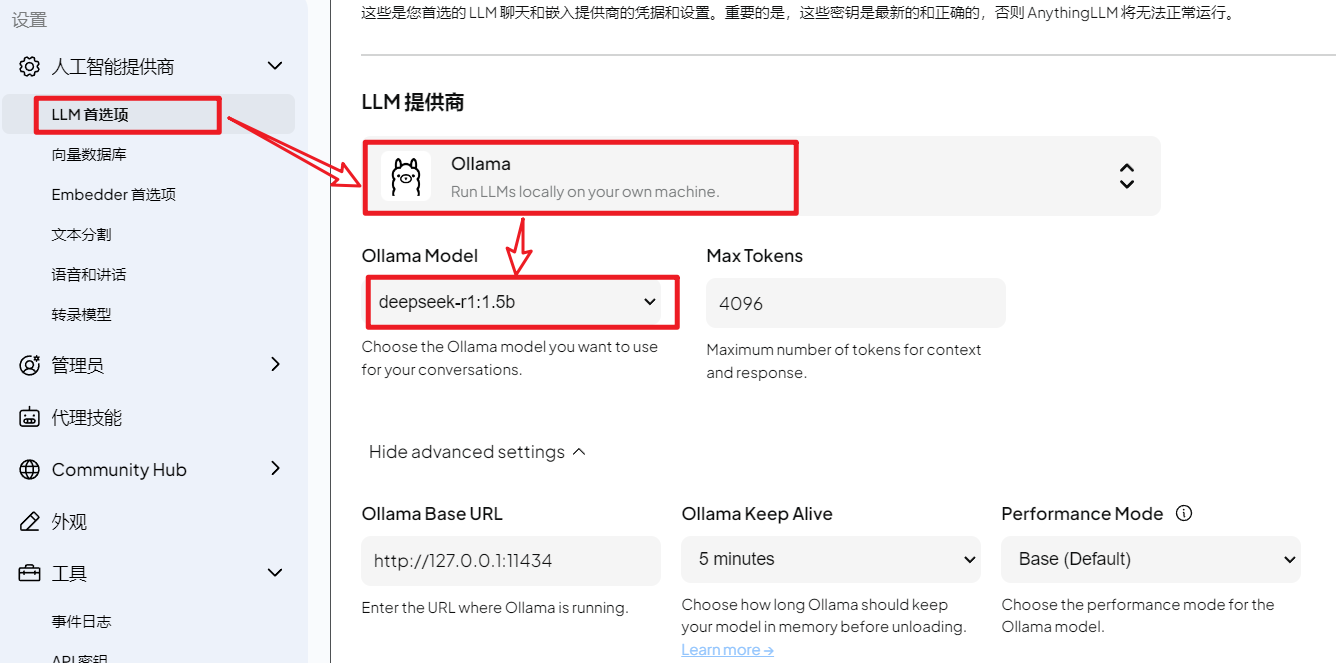
向量数据库:这里选择AnythingLLM自带的本地数据库LanceDB,当然有云端或者其他局域网部署的向量数据库也可以配置。
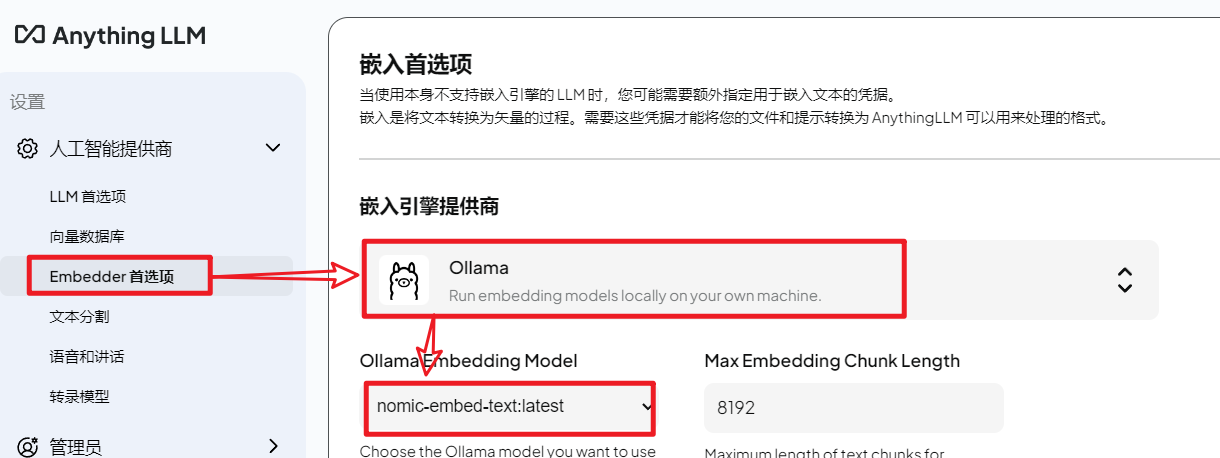
嵌入模型:这里选择使用ollama下载并部署的嵌入模型,如果有其他云端大模型api-key可以直接配置云端大模型。
这里先使用ollama安装一个嵌入模型:nomic-embed-text 安装命令ollama pull nomic-embed-text
然后再AnythingLM中选择刚才安装的嵌入模型。
然后新建一个工作区,并上传知识库文件
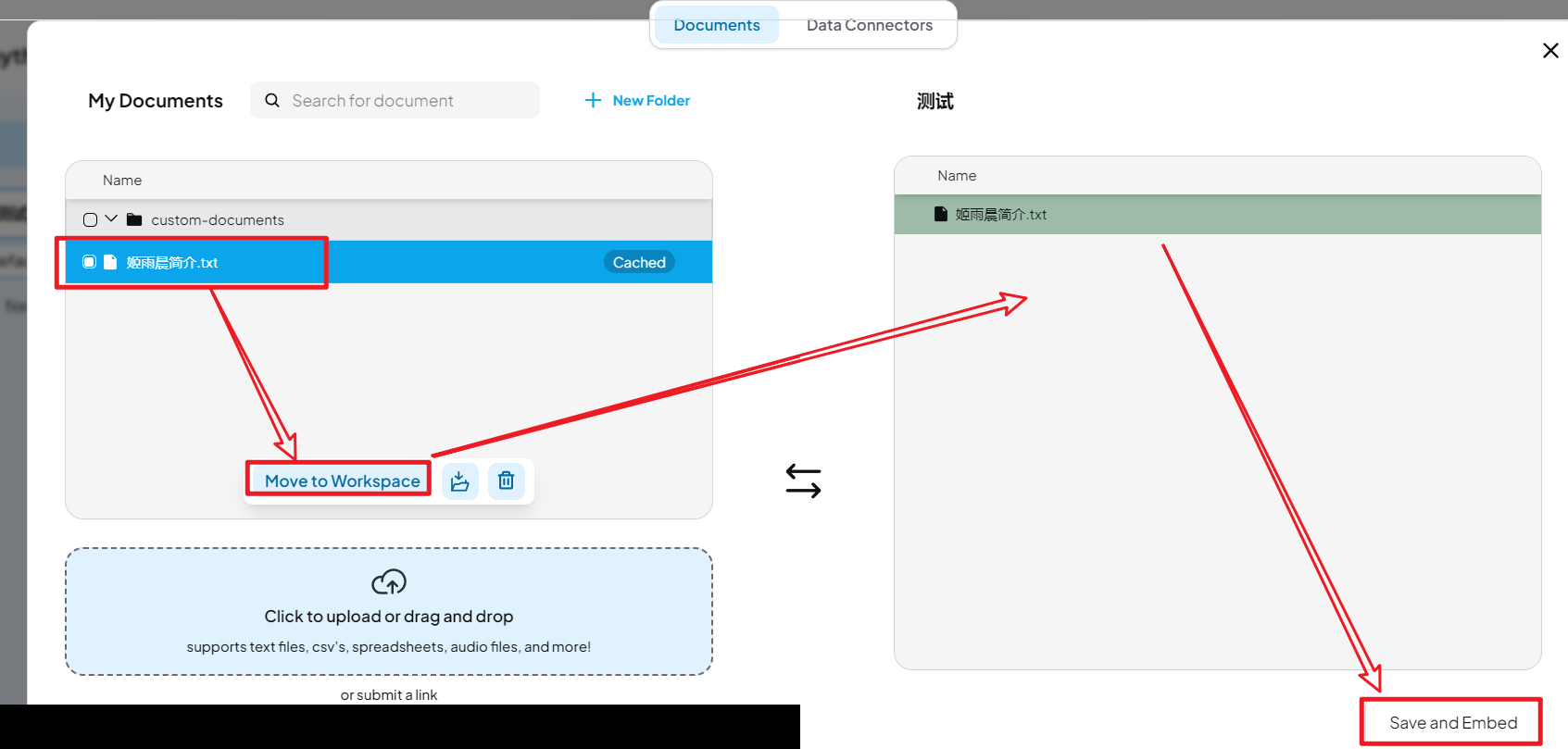
点击上传按钮后上传文件,然后选中上传了的文件,点击 “Move to Workspace”,将文件添加到知识库中,并点击保存。
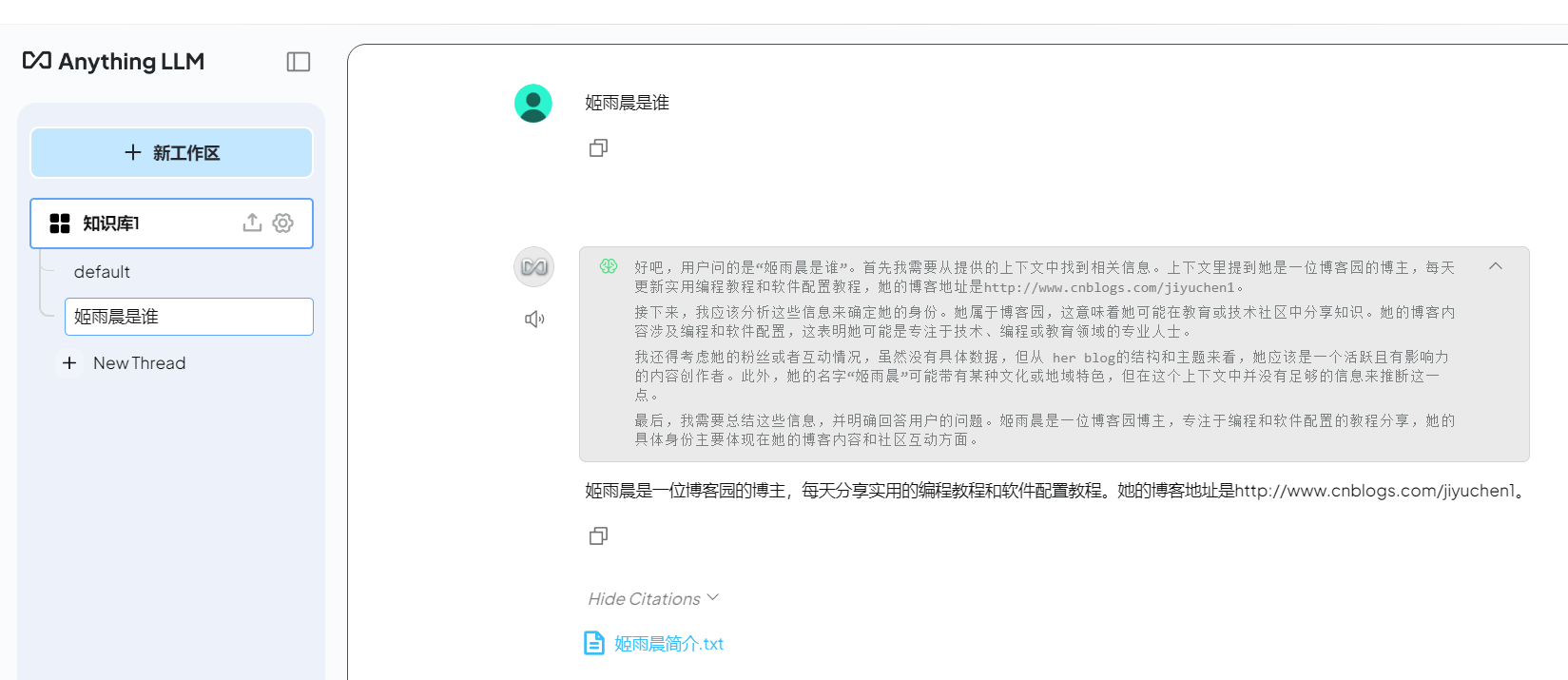
新建一个线程,验证效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号