实验五
Part 1:二分查找
设N个整数有序(由小到大)存放在一维数组中。编写函数binarySearch(),实现使用二分查找算法在一维数组中 查找特定整数item。如果找到,返回item在数组元素中的下标;如
果item不在数组中,则返回-1。
实现方式1:形参是数组,实参是数组名,使用数组元素直接访问方式实现
源代码:
#include <stdio.h> const int N=5; int binarySearch(int x[], int n, int item); int main() { int a[N]={1,3,9,16,21}; int i,index, key; printf("数组a中的数据:\n"); for(i=0;i<N;i++) printf("%d ",a[i]); printf("\n"); printf("输入待查找的数据项: "); scanf("%d", &key); index=binarySearch(a,N,key); if(index>=0) printf("%d在数组中,下标为%d\n", key, index); else printf("%d不在数组中\n", key); return 0; } int binarySearch(int x[], int n, int item) { int low, high, mid; low = 0; high = n-1; while(low <= high) { mid = (low+high)/2; if (item == x[mid]) return mid; else if(item < x[mid]) high = mid - 1; else low = mid + 1; } return -1; }
运行结果:
实现方式2:形参是指针变量,实参是数组名,使用指针变量间接访问方式实现
源代码:
#include <stdio.h> const int N=5; int binarySearch(int *x, int n, int item); int main() { int a[N]={1,3,9,16,21}; int i,index, key; printf("数组a中的数据:\n"); for(i=0;i<N;i++) printf("%d ",a[i]); printf("\n"); printf("输入待查找的数据项: "); scanf("%d", &key); index=binarySearch(a,N,key); if(index>=0) printf("%d在数组中,下标为%d\n", key, index); else printf("%d不在数组中\n", key); return 0; } int binarySearch(int *x, int n, int item) { int low, high, mid; low = 0; high = n-1; while(low <= high) { mid = (low+high)/2; if (item == *(x+mid)) return mid; else if(item<*(x+mid)) high = mid - 1; else low = mid + 1; } return -1; }
运行结果:
比较以上两种实现方式,可以发现:
实现方法1使用数组元素直接访问,直接改变了原数组的顺序。这样使用虽然直观、程序简洁,但无法保留原数组顺序,且运行占用内存较大,耗时长;
而实现方法2使用指针进行间接访问,并没有直接改变原数组的顺序,且运行占用内存小,时间短。
Part 2:选择法排序
- 选择法排序的算法思想:
选出n个数中最小的字符串与第1个数交换;
选出次小的字符串与第2个交换;
以此类推,...;
选出次大的字符串与第n-1个字符串交换
这是仿照老师提供的数字排序方法写的源代码:
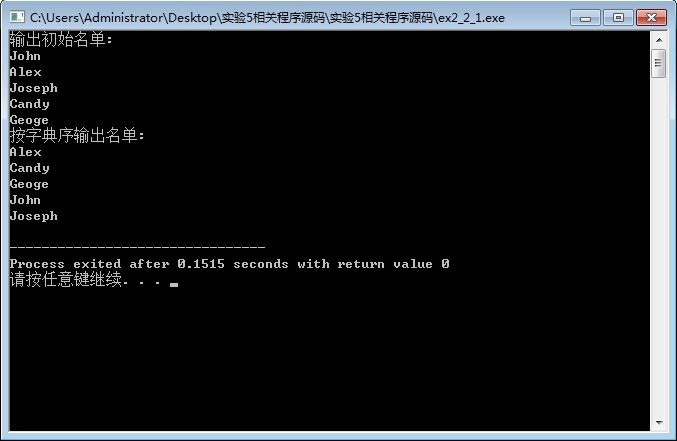
#include<stdio.h> #include<string.h> void selectSort(char str[][20], int n); int main(){ char name[][20] = {"John", "Alex", "Candy", "Geoge"}; int i; printf("输出初始名单:\n"); for(i=0;i<5;i++) printf("%s\n", name[i]); selectSort(name, 5); printf("按字典序输出名单:\n"); for(i=0;i<5;i++) printf("%s\n", name[i]); return 0; } void selectSort(char str[][20], int n){ int i, j, k; char temp[20]; for(i=0;i<n-1;i++){ k = i; for(j=i+1;j<n;j++){ if(strcmp(str[j], str[k] )< 0) k = j; } if(k != i){ strcpy(temp, str[i]); strcpy(str[i], str[k]); strcpy(str[k], temp); } } }
运行结果:
p.s.这种算法的主要思想是先记录下需要调换字符串的位置再将其调换。我换了一种写法,不记录调换字符串的位置,当发现字符串符合调换条件时,直接进行调换。
具体程序源代码如下:
#include <stdio.h> #include <string.h> void selectSort(char str[][20], int n ); int main() { char name[][20] = {"John", "Alex", "Joseph", "Candy", "Geoge"}; int i; printf("输出初始名单:\n"); for(i=0; i<5; i++) printf("%s\n", name[i]); selectSort(name, 5); printf("按字典序输出名单:\n"); for(i=0; i<5; i++) printf("%s\n", name[i]); return 0; } void selectSort(char str[][20], int n) { int i, k,j,m; char temp; for(k=0;k<n;k++){ for(i=k;i<n;i++){ for(m=0;m<20;m++){ if(str[i][m]<str[k][m]){ for(j=0;j<20;j++){ temp=str[k][j]; str[k][j]=str[i][j]; str[i][j]=temp; }break; } else if(str[i][m]>str[k][m]) break; } } } }
运行结果:
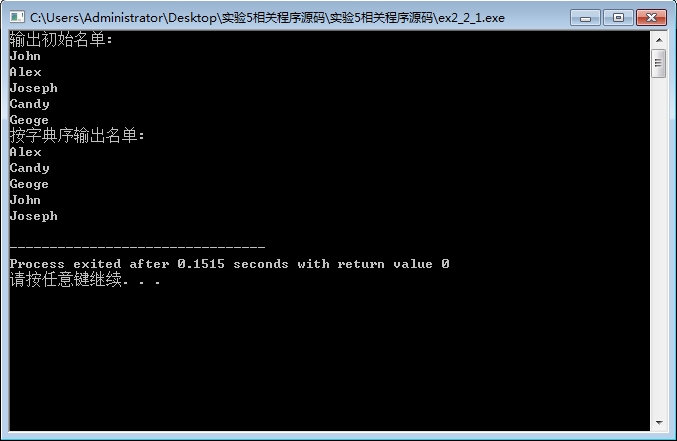
值得注意的是,用黄色标记的部分非常重要,但在编程时也很容易被忽略。
先让我们看看如果没有这条语句,程序的循环过程及运行结果:
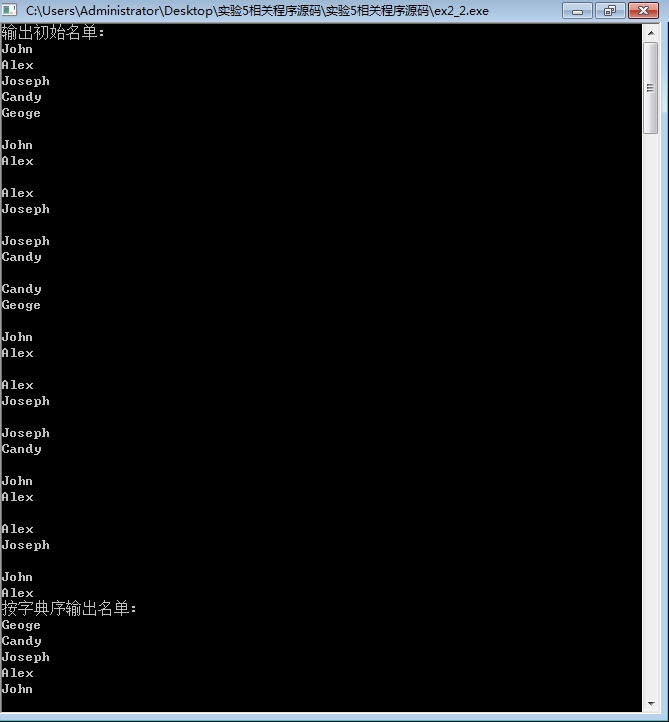
可以发现,每运行到一行,后面的字符串都被交换了一次。
究其原因,删去这条语句后,排序函数无法在需要结束循环时停止。比较两个字符串中元素的大小时,当出现本行字符串元素比被比较行元素小时,本次比较就应当结束了。然而缺少该语句时,相当于在两字符串中寻找是否存在相同位置上,被比较字符串的元素小于原字符串相应位置元素的情况,这显然是本末倒置的。
Part 3:用指针处理字符串
练习1:假定输入的字符串中只包含字母和*,例如字符串****A*BC*DEF*G*******。编写子函数
delPrefixStar(),删除字符串中所有前导*删除,中间的和后面的*不删除。即删除后,字符串的内容应当是
A*BC*DEF*G*******
// 函数定义 // 函数功能描述 // 删除字符数组s中前导* void delPrefixStar(char s[]) { char *target, *source; // 从字符串开始找到不是*的位置 source = s; while(*source == '*') source++; // 从这个位置开始将余下的字符前移 target = s; while( *target++ = *source++); }
练习2:假定输入的字符串中只包含字母和*,例如字符串****A*BC*DEF*G*******
编写子函数 delStarButPrefix(),除了前导*之外,删除其它*
即删除后,字符串的内容应当是****ABCDEFG
// 函数定义 // 函数功能描述 // 删除字符数组s中除了前导*以外的所有*(即删除字符串中间和末尾出现的*) void delStarButPrefix(char s[]) { int i=0; // i用于记录字符在字符数组s中的下标 char *p = s; // 跳过前导*,i记录字符在字符数组s中的下标,p记录首个非*字符的位置 while(*p && *p == '*') { p++; i++; } // 从p指向的字符开始,把遇到的*删除 while(*p) { if(*p != '*') { s[i] = *p; i++; } p++; } s[i] = '\0'; // 思考:这一步这样写的原因 }
其实该函数就是一个逐个判断的过程:先判断前面有多少个“*”(假设有n个),从第n+1项开始判断是否为“*”。
当全部判断结束时,由于不是逐个字符定义,所以需要在末尾加上结束符。
练习3:假定输入的字符串中只包含字母和*,例如字符串****A*BC*DEF*G*******
编写子函数 delMiddleStar(),除了前导*和尾部*之外,删除中间出现的所有*
即删除后,字符串内容应当是 ****ABCDEFG*******
// 函数定义 // 函数功能描述 // 对字符数组s中存放的字符串,删除中间出现的* void delMiddleStar(char s[]) { int i=0; char *tail, *head, *p; // 找到末尾第一个非*字符的位置 tail = s; while(*tail) tail++; tail--; while(*tail == '*') tail--; // 找到开头第一个非*字符的位置 head = s; while(*head == '*') head++; // 把中间出现的*去掉 p = s; while(p<=head) { // 思考这里条件表达式为什么这样写,这个循环的功能? s[i] = *p; p++; i++; } while(p<tail) { if(*p != '*') { s[i] = *p; i++; } p++; } while(*p) { s[i] = *p; i++; p++; } s[i] = '\0'; // 思考这里为什么要这样做 }
其实该函数是两个分步的过程:分别找到尾部第一个非*字符,和首部第一个非*字符的位置。然后分三段处理。中间的一段,删除*。
第一个循环:先把头部所有的“*”都输入;
第二个循环:输入字符;
第三个循环:输入尾部的“*”。
最后一步的作用同练习2。
- p.s.其实整个字符串s[]相当于被拆开重写了一遍,故结尾处应加上结束符号。
实验总结与体会
总得来说,数组和指针确实是c语言中比较复杂的部分。知识点、注意点繁多复杂,每个题目看似方法多多、条条大路通罗马,实则陷阱多多,一不小心就疏忽犯错。
正因为如此,我们更应该多加练习,多犯错才能多积累、多进步。
评论地址:
https://www.cnblogs.com/xinzhi999/p/10919021.html
https://www.cnblogs.com/mgl1999/p/10933803.html
https://www.cnblogs.com/jiuyuan/p/10928227.html

