Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据
1.豆瓣地址:https://movie.douban.com/top250?start=25&filter=
2.主要流程是抓取该网址下的Top250的数据,存入本地的txt文件中,并将数据持久化写入数据库中
环境准备:
1.本地安装mysql数据库,具体下载以及安装参照:https://blog.csdn.net/chic_data/article/details/72286329
2.安装好数据后创建database和table,并创建字段
如:我安装的版本是mysqlV8.0
CREATE TABLE doubanTop250( ID int PRIMARY KEY AUTO_INCREMENT, rankey int, name varchar(50), alias varchar(100), director varchar(50), showYear varchar(50), makeCountry varchar(50), movieType varchar(50), movieScore float, scoreNum int, shortFilm varchar(255) )ENGINE=InnoDB DEFAULT CHARSET=utf8;
最后我们直接来看代码:
1 from urllib import request 2 import re 3 import pymysql 4 class MovieTop(object): 5 def __init__(self): 6 self.start = 0 7 self.param = '&filter' 8 self.headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) " 9 "AppleWebKit/537.36 (KHTML, like Gecko) " 10 "Chrome/65.0.3325.146 Safari/537.36"} 11 self.movieList = [] 12 self.filePath = './DoubanTop250.txt' 13 14 def get_page(self): 15 try: 16 url = 'https://movie.douban.com/top250?start=' + str(self.start) + '&filter=' 17 myRequest = request.Request(url, headers=self.headers) 18 response = request.urlopen(myRequest) 19 page = response.read().decode('utf-8') 20 print('正在获取第' + str((self.start+25)//25) + '页数据...') 21 self.start += 25 22 return page 23 except request.URLError as e: 24 if hasattr(e, 'reason'): 25 print('获取失败,失败原因:', e.reason) 26 27 def get_page_info(self): 28 patern = re.compile(u'<div.*?class="item">.*?' 29 + u'<div.*?class="pic">.*?' 30 + u'<em.*?class="">(.*?)</em>.*?' 31 + u'<div.*?class="info">.*?' 32 + u'<span.*?class="title">(.*?)</span>.*?' 33 + u'<span.*?class="other">(.*?)</span>.*?' 34 + u'<div.*?class="bd">.*?' 35 + u'<p.*?class="">.*?' 36 + u'导演:\s(.*?)\s.*?<br>' 37 + u'(.*?) / ' 38 + u'(.*?) / (.*?)</p>.*?' 39 + u'<div.*?class="star">.*?' 40 + u'<span.*?class="rating_num".*?property="v:average">' 41 + u'(.*?)</span>.*?' 42 + u'<span>(.*?)人评价</span>.*?' 43 + u'<span.*?class="inq">(.*?)</span>' 44 , re.S) 45 46 while self.start <= 225: 47 page = self.get_page() 48 movies = re.findall(patern, page) 49 for movie in movies: 50 self.movieList.append([movie[0], 51 movie[1], 52 movie[2].lstrip(' / '), 53 movie[3], 54 movie[4].lstrip(), 55 movie[5], 56 movie[6].rstrip(), 57 movie[7], 58 movie[8], 59 movie[9]]) 60 61 def write_page(self): 62 print('开始写入文件...') 63 file = open(self.filePath, 'w', encoding='utf-8') 64 try: 65 for movie in self.movieList: 66 file.write('电影排名:' + movie[0] + '\n') 67 file.write('电影名称:' + movie[1] + '\n') 68 file.write('电影别名:' + movie[2] + '\n') 69 file.write('导演:' + movie[3] + '\n') 70 file.write('上映年份:' + movie[4] + '\n') 71 file.write('制作国家/地区:' + movie[5] + '\n') 72 file.write('电影类别:' + movie[6] + '\n') 73 file.write('评分:' + movie[7] + '\n') 74 file.write('参评人数:' + movie[8] + '\n') 75 file.write('简短影评:' + movie[9] + '\n') 76 file.write('\n') 77 print('成功写入文件...') 78 except Exception as e: 79 print(e) 80 finally: 81 file.close() 82 83 def upload(self): 84 db = pymysql.connect("localhost", "root", "root", "PythonTest", charset='utf8') 85 cursor = db.cursor() 86 87 insertStr = "INSERT INTO doubanTop250(rankey, name, alias, director," \ 88 "showYear, makeCountry, movieType, movieScore, scoreNum, shortFilm)" \ 89 "VALUES (%d, '%s', '%s', '%s', '%s', '%s', '%s', %f, %d, '%s')" 90 91 try: 92 for movie in self.movieList: 93 insertSQL = insertStr % (int(movie[0]), str(movie[1]), str(movie[2]), str(movie[3]), 94 str(movie[4]), str(movie[5]), str(movie[6]), float(movie[7]), 95 int(movie[8]), str(movie[9])) 96 cursor.execute(insertSQL) 97 db.commit() 98 print('成功上传至数据库...') 99 except Exception as e: 100 print(e) 101 db.rollback() 102 finally: 103 db.close() 104 105 if __name__ == '__main__': 106 mt = MovieTop() 107 mt.get_page_info() 108 mt.write_page() 109 mt.upload()
执行结果: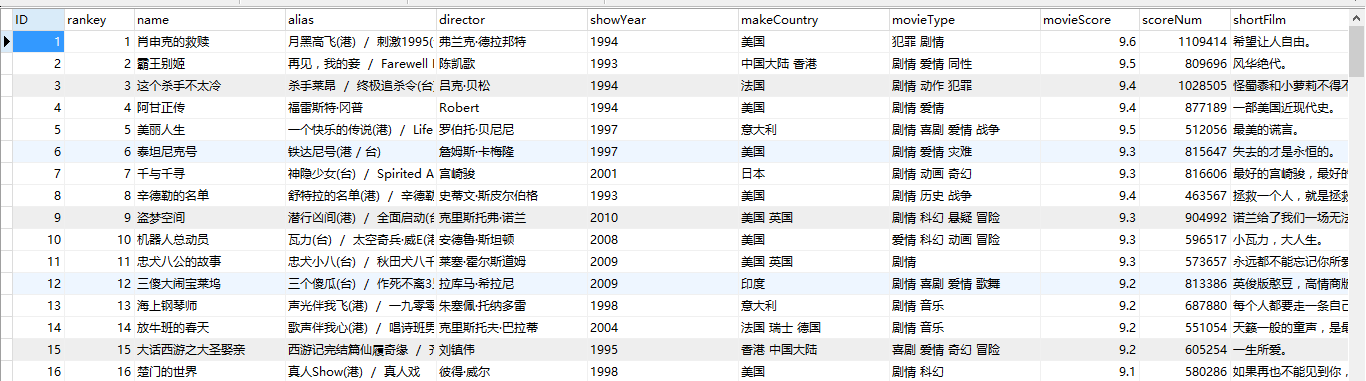
参照原文地址:https://www.cnblogs.com/AlvinZH/p/8576841.html#_label0
