Kafka技术内幕 读书笔记之(四) 新消费者——新消费者客户端(一)
新版本的消费者采用Java重新实现。 但不管采用什么版本实现,消费者消费消息的主要工作没有太大变化 , 比如为消费者分配分区、拉取线程拉取消息、
客户端消费消息、更新拉取状态、提交偏移量 。
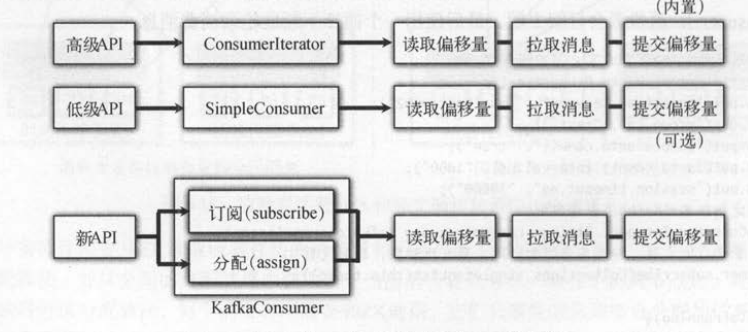
1. 消费者的高级API和新API
客户端使用新API ,主要调用了 KafkaConsumer类提供的两个方法 : 订阅和轮询 。
- subscribe(Topic )。该方法使用消费组的管理功能,再平衡时“动态分配”分区给消费者方法会 “静态分配”指定分区给消费者,还有一个assign(Partition )方法会 “静态分配”
没有消费组的自动负载均衡和再平衡操作(类似于低级API) 。
- poll (),该方法轮询返回消息集,由于调用一次轮询只得到一批消息,因此需要使用外部的死循环来不断读取消息。
(类似于高级API消息流对应的迭代器,但没有外部的死循环)
下表 比较了高级API和新API在客户端使用方式上的几个不同点 。 比如分配分区时,高级API通过ZK监听器触发,新API会发送请求给协调者去处理。
提交偏移量时,高级API可以写到ZK或者协调者,新API会写到协调者。 消费消息时,高级API通过迭代器进行,新API会循环轮询方法返回的记录集 。 
如下图所示,高级API的消费者连接器会使用一个后台线程,定时地提交偏移盘到ZK或者协调者节点上 。 新API提交偏移量除了有一个自动提交偏移量的后台任务,
还提供了同步和异步两种模式的偏移量提交方法。 新API不仅在偏移量上保持了统一,订阅消息的方式也定义了 subscribe ()和 assign()两个方法,分别对应高级
API使用消费者连接器订阅主题和低级API使用 SimpleConsumer手动指定分区 。消费者客户端不需要使用不同的对象,使用起来更简单。
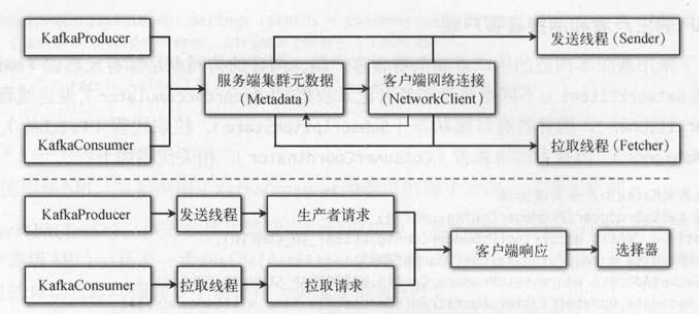
2. 新API 的生产者和消费者客户端
对比一下采用新版本构造的生产者和消费者客户端,两者的共同点是都有元数据( Metadata )和网络客户端( NetworkClient )。
不同点是生产者有记录收集器( RecordAccufllulator)、发送线程( Sender )、分区器( Partitioner ),
消费者有订阅状态( SubscriptionState )、拉取钱程( Fetcher)、分区分配( PartitionAssignor) 、 消费者的协调者( ConsumerCoordinator )。
如下图所示,生产者和消费者对于服务端而言都属于客户端,使用Java开发的新版本客户端把网络层抽象了出来,
生产者和消费者的网络层实际上用的是同一套通信机制,即都采用了基于选择器模式的网络客户端 。网络客户端会分别用于生产者的发送线程
和消费者的拉取线程 。 生产者在创建Kafka Producer时就立即启动发送线程,而消费者创建KafkaConsumer时并不会立即启动拉取线程,因为
拉取线程需要有分区才可以正常运行。 生产者发送生产请求和消费者发送拉取请求 , 最后都会通过网络客户端的选择器轮询将客户端请求发送给服务端。
生产者和消费者客户端还都需要在本地保存服务端集群的元数据(元数据保存了集群的节点列表 、 主题和分区的关系 、 节点和分区列表等信息),
否则在需要这些信息时就只能通过向服务端发送相关的请求来完成。
3. 消费者高级API 和新API 的组件
如下图所示, 高级API和新API分别使用不同的组件拉取消息 。 粗线部分表示和客户端应用程序直接交互的对象。 两种API有一些组件类似,
比如消费者连接器类似KafkaConsumer , ZK监听器类似消费者的协调者( ConsumerCoordinator ),消费者迭代器类似消费者记录集( ConsumerRecords )。 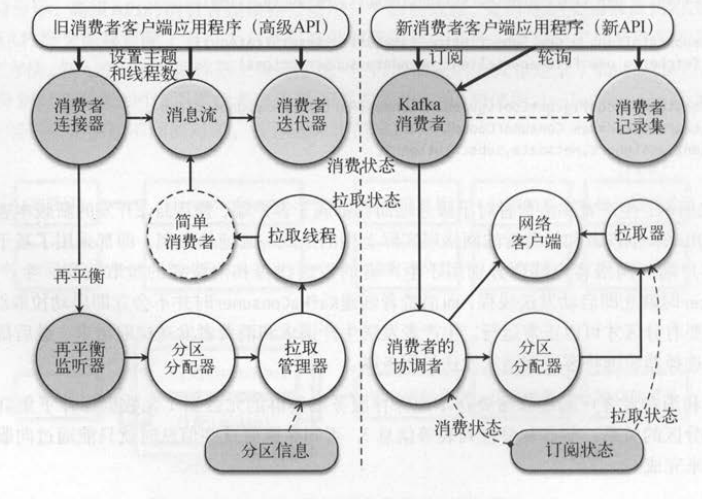
消费者更新分区的状态有两种: 拉取状态和消费状态 。 高级API使用分区信息对象( PartitionTopicinfo )记录这两种状态,由于更新拉取状
态的拉取线程和更新消费状态的消费者迭代器在不同作用域内,需要将分区信息对象相继传给消费者拉取管理器、消费者拉取线程 、 消费者迭代器。 新API
使用SubscriptionState保存订阅状态,也记录了分区的拉取状态和消费状态。 新创建的订阅状态会传给消费者的协调者对象和拉取线程。
新消费者客户端
消费者的订阅状态
新API为消费者客户端提供了两种消费方式 : 订阅 ( subscribe )和分配( assign )。
- 订阅模式。消费者会指定订阅的主题,由协调者为消费者分配动态的分区 。
- 分配模式。消费者指定消费特定的分区,这种模式失去了协调者为消费者动态分配分区的功能 。
订阅方法的参数是“主题”,分配方法的参数是“分区”,这两个方法都会更新消费者订阅状态对象( SubscriptionState )。分配结果( assignment )字典保存了
分配给消费者的分区到分区状态映射关系 。 如果是订阅方式,初始时字典为空 ,只有分配分区后调用 addAssignedPartition ()方法,才会将
分配给消费者的分区添加到订阅状态的分配结果中 。
如下图所示,分配模式一开始就确定了分区,而订阅模式需要通过消费组协调之后,才会知道向己分配到哪些分区 。消费者要拉取消息,
必须确保分配到分区 ; 有了分区后,后续的拉取消息流程都一样。 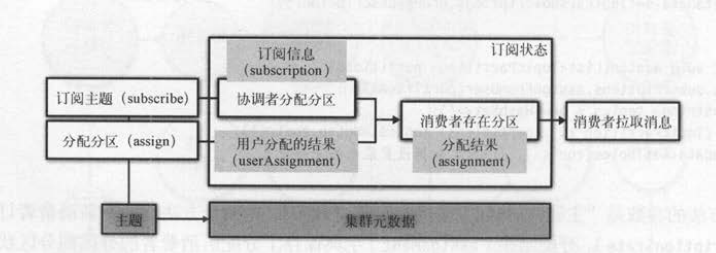
1. 分区状态对象
如下表所示,高级API使用分区信息( PartitionTopicinfo )、分区拉取状态( PartitionFetchState )两个对象表示分区的状态 。消费者拉取线程根据
“拉取状态”拉取分区消息,客户端迭代消息更新分区的“消费状态” 。 新API只用一个分区状态对象,代替高级API的两个对象。 
新创建分区状态对象时,这两个偏移量变量初始时都为空,表示刚创建时消费者还没有开始“拉取”这个分区 ,并且还没有为这个分区“提交”过偏移量
。 但实际上,分区最新的“拉取偏移量”和已经“提交的偏移量”应该是有状态的,跟悄费者应该是无关的 。 比如分配给消费者1 的分区P0 ,它
的拉取偏移量是 100 ,消费偏移量是90 。 当P0分配给消费者2时 ,消费者2获取P0的状态应该是有数据的 。 所以消费者2的拉取钱程在工作之前,
应该先初始化分区状态,比如设置P0的拉取偏移量为 100 。
如下图(左)所示,消费者拉取消息的过程中,更新拉取状态是为了拉取新数据,更新消费状态是为了提交到ZK或协调节点 。更新偏移量的步骤在分区
状态中都有对应的方法 [ 如下图(右)所示 ] ,比如重置偏移量 seek ()方法对应了第一次从ZK或协调节点读取拉取状态, position() 和committed()
方法分别对应了更新拉取状态和更新消费状态 。

分区状态的拉取偏移量( position变量)表示分区的拉取进度,它的值不能为空,消费者才可以拉取这个分区 。 新API的拉取线程工作时,
要确保及时地更新分区状态的拉取偏移量,每次构建的拉取请求都以拉取偏移量为准 。 我们可以把 seek ()
方法看作“第一次读取ZK”更新拉取偏移盘,把position()方法看作“每次拉取到消息后”更新拉取偏移量 。
2 . 订阅状态提供的方法
订阅状态保存了分配给消费者的所有分区及其状态如果要更新分区的状态,必须指定分区,订阅状态会根据分区从分配结果中获取分区状
态,再更新这个分区状态的变量。 订阅状态提供了下面几个方法更新指定分区的相关状态。
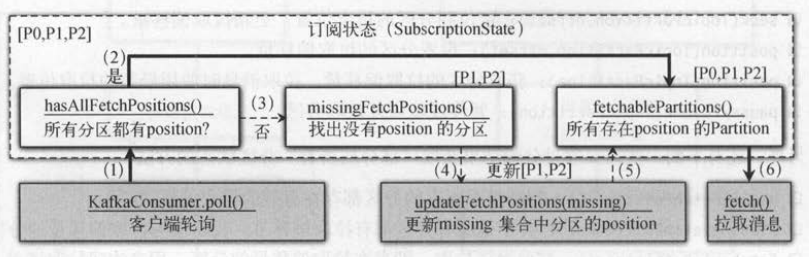
如下图所示,消费者第一次轮询不满足 hasAllFetchPositions () ,执行步骤(1)、(3)、(4)、(5)和(6 ),
即图中虚线路径 。 比如消费者分配了 [P0,P1,P2]这3个分区,消费者第一次轮询时分区P0有拉取偏移量,而分区[P1,P2]都没有拉取偏移量 。
步骤(4)会更新[P1,P2]两个分区的偏移量,最后到步骤(6)时3个分区都有拉取偏移量。 第二次轮询时,所有的分区都有拉取偏移量了,
所以不需要更新分区,只需要执行步骤。(1)、(2)和(6),即图中实线路径 。
(1 ) 客户端订阅主题后通过 KafkaConsumer轮询,准备拉取消息 。
(2)如果所有的分区都有拉取偏移量,进入步骤( 6),否则进入步骤( 3 ) 。
(3)从订阅状态的分配结果中找出所有没有拉取偏移量的分区 。
(4)通过 updateFetchPositions ()更新步骤( 3)中分区的拉取偏移量 。
(5)不管是从步骤(2)直接进来还是步骤(4)更新过的分区,现在都允许消费者拉取 。
(6)对所有存在拉取偏移量并且允许拉取的分区,构建拉取请求开始拉取消息 。
3. 重置和更新拉取偏移量
调用KafkaConsumer的更新拉取偏移量方法有下面两个步骤 。
(1 )通过“消费者的协调者”( ConsumerCoordinator )更新分区状态的提交偏移量 。
(2)通过“拉取器”( Fetcher)更新分区状态的拉取偏移量 。
“偏移量”是消费者中一个很重要的基本概念 。 “拉取偏移量”用于在发送拉取请求时指定从分区的哪里开始拉取消息,
“提交偏移量”表示消费者处理分区消息的进度 。 消费者拉取消息时要更新拉取偏移量,处理消息时需要更新提交偏移量。
通常“提交偏移量”会赋值给“拉取偏移量”,尤其是发生再平衡时,分区分配给新的消费者 。 新消费者之前在本地没有记录这个分区的消费进度,
它要获取“拉取偏移量,需要从协调者获取这个分区的“提交偏移量”,把“拉取偏移量”作为分区的起始“拉取偏移量” 。 比如,旧API的消费者在拉取线程启动前,
会从ZK或协调节点读取分区的“已提交偏移量”,作为新创建分区信息对象的“拉取偏移量”。
新API的消费者每次轮询时,对没有拉取偏移量的分区也采用类似的方式,通过消费者的协调者对象发送“获取偏移量”请求( OFFSET_FETCH )
给服务端的协调者节点 。 “获取偏移量”请求返回的结果表示这个分区在协调者节点已经记录的“提交偏移量” 。 服务端记录的这个偏移量可能是同一个消
费组的其他消费者提交的。
消费者发送“获取偏移量”的请求有可能返回空值,说明服务端的协调者节点并没有记录这个分区的“已提交偏移量”,那么分区状态的“己提交偏移量”也为空,
就不能把空的“已提交偏移”赋值给“拉取偏移量” 。 这时候需要根据消费者客户端设置的重置策略,向分区的主副本节点发送“列
举偏移量”请求( LIST_OFFSETS )获取分区的偏移量 。
“获取偏移量”请求对象( OffsetFetchRequest )由消费组和分区组成,服务端的协调者会返回分区对应的“提交偏移量” 。
“列举偏移量”请求对象( Li.stOffsetRequest )中并没有消费组,那么仅仅根据分区查询偏移量,只能将请求发送到分区的主副本节点,
而且要通过直接读取日志文件的方式完成。
消费者轮询的准备工作
客户端的消费者与服务端的协调者通信通过消费者的协调者类完成,在拉取消息前有两个方法:第一个确保客户端已经连接上协调者;第 二 个是
确保消费者收到协调者分配给它的分区,如果消费者没有分配到分区,就无法拉取消息。 客户端在第一步必须先连接上协调者,才能调用第二步从协调者获取分区,
否则第二步就无法执行。
上面假设消费者分配到分区,不过对于订阅模式,消费者的分区是由协调者分配的,拉取消息之前一定要确保存在协调者,并且协调者也成功地为当前消费者分
配了分区 。消费者能够分配到分区的条件是要加入到消费组中 。 这些事件发生的顺序为: 消费者向协调者申请加入消费组,服务端存在管理消费组的协调者,
协调者将消费者加入消费组,协调者为所有消费者分配分区,消费者从协调者获得分配给它的分区,消费者拉取分区的消息 。
消费者拉取消息的准备工作有: 连接协调者,向协调者发送请求加入消费组,从协调者获得分配的分区 。
“消费者提交偏移量”给管理消费组的协调者,与这里“消费者连接”管理消费组的协调者本质上是一样的 。 属于同一个消费组
的所有消费者连接的协调者都是同一个节点,不管是提交偏移量操作,还是发送与消费组相关的请求。
1. 发送请求并获取结果的几种方案
每个消费者都要向协调者发送“加入消费组的请求”( JoinGroupRequest ),协调者才会知道消费组有哪些消费者,才可以执行全局的分区分配算法。
每个消费者从“加入消费组的响应”( JoinGroupResponse )可以获取到分配给它的分区 。消费者什么时候分配到分区由协调者决定,如果协调者的分配算法还没
有执行完,消费者就不能得到分配分区 。 一种比较复杂的获取分区流程如下 。
(1)消费者发送“加入消费组的请求”,向协调者申请加入消费组 。
(2)协调者接受消费者加入消费组 。
(3)协调者等待消费组中其他消费者也发送“加入消费组的请求” 。
(4)协调者执行分区分配算法为所有消费者分配分 区 。
(5)消费者再次发送获取分区的请求 。
(6)协调者返回分区给消费者 。
上面的做法采用同步的模式 : 消费者发送完请求会一直等待 , 直到收到响应结果 。 但实际上协调者为了保证同一个消费组的所有消费者都能分配到分区,
要等待所有消费者都加入消费组后,才开始执行分区分配算法 。 所以消费者发送请求后返回的是一个带有“加入消费组的响应”的异步对象
( Future ),表示响应结果会在未来的某个时刻返回给消费者客户端。
2 . 消费者加入消费组
消费者通过客户端的协调者调用ensureActiveGroup ()方法加入一个消费组需要3步 : 准备阶段调用onJoinPrepare ()方法,
发送“加入消费组的请求”阶段调用sendJoinGroupRequest ()方法,“成功加入消费组 ” 阶段获取到分区调用onJoi.nCoP!plete ()方法。
消费者只有在再平衡时才需要重新加入消费组。
发送请求前的准备阶段也使用了一个布尔变量needsJoinPrepare控制 ,初始时为true , 调用onJoinPrepare ()后设置为false , 表示准备阶段已经
完成。 调用onJoinComplete ()重置为true ,为下次重新加入做准备。
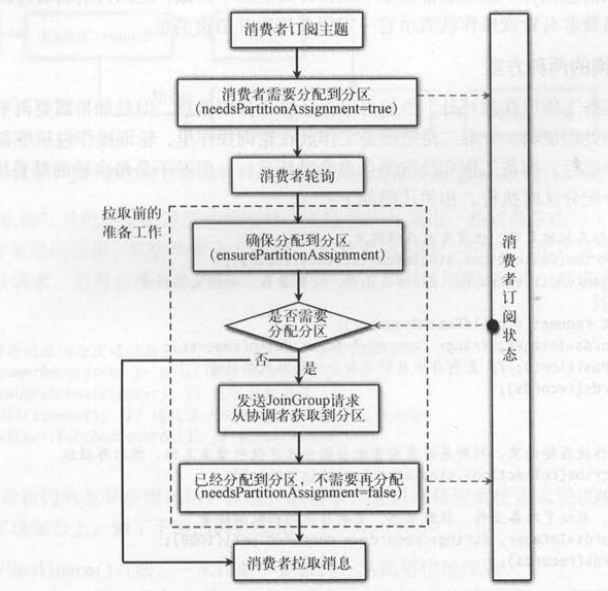
下面以消费者调用两次轮询为例说明确保分配到分区的执行流程,第一次轮询步骤如下 。
(1 )初始 needsJoinPrepare和rejoinNeeded都为 true ,消费者启动时默认要加入消费组 。
(2)满足 needRejoin (),先调用 onJoinPrepare ()做准备工作,比如提交偏移量等 。
(3)准备工作完成后修改 needsJoinPrepare=false ,防止加入消费组完成前多次执行准备工作 。
(4)满足 needRejoin (),执行循环体:发送请求,调用一次客户端轮询尝试获取结果 。
(5)消费者分配到分区,更新rejoinNeeded为 false ,并重置 needsJoinPrepare为 true 。
如下图所示,在第一次轮询的最后一步中, onJoinComplete ()方法在消费者成功加入消费组并分配到分区后,会更新订阅状态的 needsPartitionsAssigned为false ,
这个变量也会被消费者用来判断是否需要重新加入消费组 。 如果它的值为 false ,表示消费者已经分配到分区了,不需要再次加入消费
组(除非再平衡时)。 因正在第二次轮询时, ensurePartitionAssignment ()方法会立即返回, 不会调用ensureActiveGroup () 。
在高级API中,消费者启动时向ZK注册不同事件的监听器(比如分区变化 、 消费者成员变化 、 会话超时),当注册的事件发生时会触发ZKRebalancelistener的再平衡操作。
新API的再平衡控制策略采用变量的方式,相比ZK监听器没有额外的通信开销,直接在内存中修改变量,不需要和其他组件交互,虽然看起来很原始,却很高效 。
消费者轮询的流程
消费者订阅主题的下一步是“轮询” 。 前面分析的准备t作(确保协调者存在,确保分配分区,更新拉取偏移量)都内置在轮询操作里,所以本节的“轮询”主要指准
备工作之后的拉取消息流程 。 这些准备工作不放在订阅主题中去做,是因为消费者订阅了主题不一定会消费消息,但消费者有轮询操作就表示它一定想要拉取并消费消息 。
1. 客户端轮询的两种方案
方案一 是把准备工作放在循环外,虽然可以保证循环拉取消息,但是如果需要再平衡,就无法执行重新分配分区的处理逻辑 。
方案二 是把准备工作放在轮询操作里,轮询操作包括准备工作和拉取消息 。 轮询在循环中运行,准备工作和拉取消息也会循环运行。 但并不是每次轮询都要执行准备工作,
只会在需要重新分配分区时执行。
下面列举了多次轮询事件,每次轮询的工作都不同,具体步骤如下 。
(1 ) 消费者订阅主题 → 轮询 (执行准备工作→分配分区→拉取消息)。
(2 ) 轮询 (已经分配到分区,不再执行准备工作→拉取消息)→轮询 (拉取消息)…… 。
(3 ) 外部事件导致再平衡 → 轮询 (需要重新分配分区→执行准备工作→拉取消息)。
(4 ) 轮询(已经分配到分区,不再执行准备工作→拉取消息)→轮询(拉取消息)··
在消费者上的轮询和网络层的轮询有什么区别呢?先来回顾一下“网络层的轮询” 。 生产者的发送线程通过NetworkClient发送生产请求或接收生产响应。
网络层的轮询操作基于选择器,只用一个事件循环处理不同的读写请求 。 消费者相对于Kafka集群也是一种客户端,消费者拉取消息也会通
过 NetworkClient发送拉取请求和接收拉取结果 。 Java 版本的 Kafka 生产者和消费者都基于NetworkClient,不过消费者在 NetworkClient之上又封装了一个 ConsumerNetworkClient 。
如下图所示,生产者和消费者都需要“循环”调用 NetworkClient的轮询方法,生产者的循环在发送线程控制,消费者则在客户端应用程序向己控制是否需要循环拉取消息 。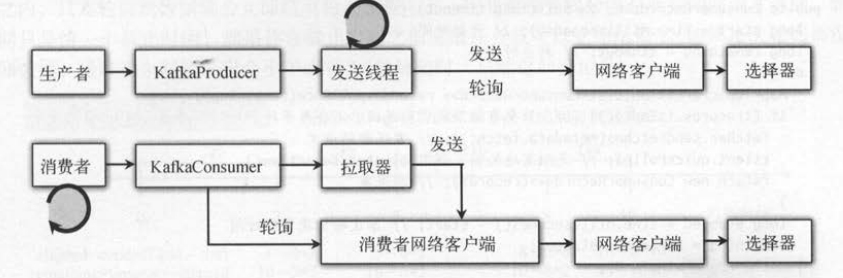
“网络层的轮询”只负责发送请求和接收响应(还会额外调用一些回调方法等),所以在此之前,客户端需指定要发送的请求 。 从这个意义上来看,
“消费者的轮询”等价于“生产者发送线程的工作”,前者会准备拉取请求,后者会准备生产请求,最后都通过“网络层的轮询”,把请求发送出去 。
Kafka消费者轮询的 主要步骤包括 : 发送拉取请求、通过网络轮询把请求发送出去、获取拉取结果 。 在具体的实现细节上,做了下面的两点优化。
- 循环调用 pollOnce ()方法, 一次拉取少量数据,从而更快地拉取 。
- 并行拉取方式,返回拉取结果前再发起一次轮询,下次轮询可以更快地得到结果 。
2. 消费者的一次轮询
消费者客户端调用一次KafkaConsumer.poll ()轮询方法只会返回一批结果记录 。 如果客户端想要一直消费消息,就要在客户端代码中手动循环调用轮询方法 。
因为消费者可以分配多个分区,所以轮询的结果数据会按照分区进行分组 , 尽量保证同一个分区的消息一起返回给客户端。虽然最后返回给客户端的消费者记录集( ConsumerRecords )
没有分区信息,但实际上它对轮询结果数据做了一层迭代器封装,所以还是可以保证分区级别的消息的有序性的 。
比如一次轮询的结果数据是{ P0-> List[(K1,V1),(K2, V2 ) ], P1-> List [(K3, V3 ), P2-> List [ ( K4, V4 ) ] } ,
封装后的消费者记录集为: [(K1,V1), (K2, V2 ), (K3, V3 ), (K4, V4 )] 。
客户端会为轮询操作指定一个最长的等待时间 ,如果达到超时时间,还是没有拉取到任何数据,就会返回空的集合给客户端。
pollOnce ()方法传递“剩余时间”,并不一定就是一次轮询花费的时间 。 比如,超时时间设置为 10秒 , 尽管第一次轮询剩余时间为 10秒,但第一次轮询可能只会花费 1秒。
下一次轮询时剩余时间为9秒,但轮询可能会花费2秒。 这样就需要调用多次轮询 ,并且剩余时间的值会不断减少。要在每次轮询后更新剩余时间、循环判断是否还有剩余时间 、
把最新剩余的时间再传给轮询方法。“超时时间”参数保证了在这个时间内,如果没有数据就会一直重试,直到超时 ,如果一有数据就立即返回(不需要等到超时后再返回)。
如果剩余时间小于等于0时 ,轮询的结果集还是空的,表示客户端在超时时间内没有拉取到任何消息 。
3 . 串行和井行模式轮询
客户端调用一次轮询 , 拉取消息并消费消息的流程是:发送请求→客户端轮询 → 获取结果→消费消息 。 客户端循环调用轮询和消费消息的步骤是串行的 。
而且发送 伪代码如下 : 
并行模式会在一次轮询中发送多次请求。 实际上,一次轮询最多只允许发送两个请求,而且发送第二个请求只能发生在上面流程中的步骤(3)和步骤(4)之间 。
如果发送新请求在步骤(2)和步骤(3)之间,执行步骤(3)时获取的数据无法区分是哪个请求的,因为第一个请求和第二个请求都会产生结果数据 。
当然,也不要放在步骤(4)之后,那样就退化到前面的串行模式了 。
如下图所示,消费者发生了3次轮询,一共发送了4次请求,得到了3个请求的结果 。 图中粗体编号表示请求 1的执行顺序,灰色背景部分是请求2。
第一次轮询时发送了请求 1 , 得到请求1的结果,发送请求2 ; 第二次轮询时 ,先得到第一次轮询请求2的结果,并发送请求3 ; 第三次轮询时,得到第二
次轮询请求3的结果, 并发送请求4。 也就是说,每次轮询时,都会在步骤(3)获取当前请求的结果和步骤(4)处理结果之间发送新的请求,然后返回当前
请求的结果,好处是可以尽可能增加相同时间内处理的请求量 。
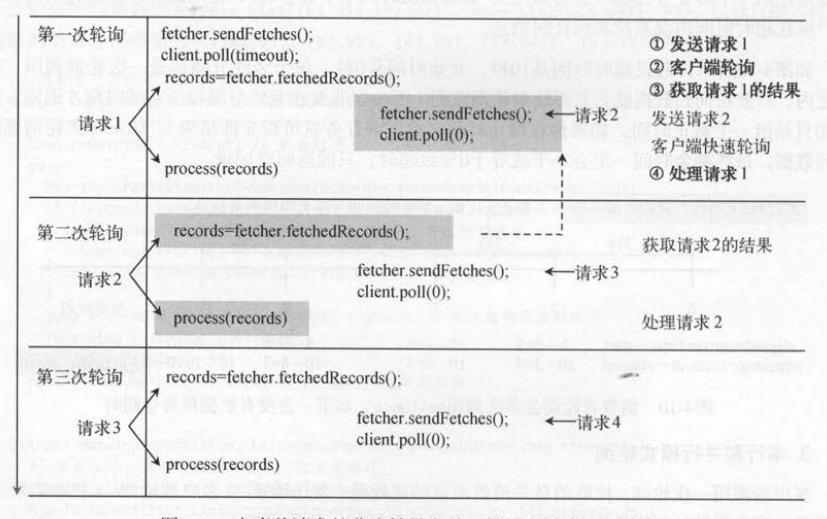
我们在每次轮询获取到当前请求的结果后,发送新的拉取请求, 下面的两个条件确保了新请求不会影响第一个请求。
--发送请求返回的是一个异步请求对象,调用发送请求会立即返回到主流程 。
--快速轮询将新请求发送出去后,并不会等待获取响应结果,所以它也不会影响第一个请求 。
快速轮询和普通轮询方法的不同点是前者的超时时间设置为0,而后者的超时时间等于剩余时间(通常大于0 )。 超时时间为0 ,这表示轮询时不会被阻塞而是立即返回 。
4 并行模式轮询的设计
消费者拉取消息的流程是:发送请求→客户端轮询→获取拉取结果→处理拉取结果 。 那么如第一次轮询有六个步骤一一发送第一个请求 、 客户端轮询、获
取第一个请求的拉取结果 、 发送第二个请求 、 客户端快速轮询、返回第一个请求的拉取结果 、 处理拉取结果,这是一个标准的并行模式示例 。
第二次以及之后的每次轮询有四个步骤 : 获取(上一次)请求结果 、 发送下一次请求 、 返回请求结果 、 处理拉取结果。
那么如何判断是不是第一次轮询呢?如果按照发送请求→轮询→获取记录的顺序执行,最后一定可以获取到结果 。 Kafka的做法是在pollOnce ()
方法中先获取记录,如果记录为空,就表示是第一次轮询,接着会执行发送请求→轮询→获取记录 。 第一次轮询在获取第一个请求的记
录后,会发送第二个请求并快速轮询,最后返回第一个请求的记录 。第二次轮询时,也是先获取记录,因为第二个请求的发送请求→轮询已经在
了 。 所以第二次轮询时, pollOnce () 中“获取记录”返回结果不为第一次轮询中完成空 。 第二次轮询在获取第二个请求的记录后,
会发送第三个请求并快速轮询,最后返回第二个请求的记录。 后续的轮询以此类推。
如下图 (左)所示,第一次轮询时依次执行右侧的(1)发送请求→(2)轮询→(3)获取记录集→(4)发送新请求→( 5)快速轮询→( 6)返回记录集 。
第二次之后的轮询依次执行左侧的(1)获取记录集→( 2)发送新请求→(3)快速轮询→(4)返回记录集 。
如下图 (右)所示,调用一次 pollOnce ()方法如果没有返回记录,就会继续循环,直到超时后退出循环,返回空的记录
(比图(左)多了一个循环的过程)。 只要有调用“获取记录集”,就需要判断记录集是否为空 。 如果记录集有数据,就会发送新
请求→快速轮询,然后返回获取的记录集,客户端轮询就结束了 。 
5 . 轮询与结果
KafkaConsumer的轮询操作中“发送拉取请求”和“获取拉取结果”都通过拉取器( Fetcher)完 成,这两个步骤中间的“客户端轮询”起到了承上启下的作用 。
如下图(左)所示,客户端轮询会把请求通过网络真正发送出去,并且在收到响应结果后将结果设置到拉取器中,这样获取拉取结果时才有数据。
但实际上将拉取结果放到拉取器中并不应该交给客户端轮询去做,客户端的轮询如果涉及具体的请求,就要处理各种各样的请求类型。 让客户端轮询
只专注于网络层的发送和接收,和业务逻辑解耦才是正确的方法 。 如上图 (右)所示,解决方法是在发送请求时定义一个回调方法,它会将响应结
果放到拉取器中,具体步骤如下 。
(1)发送请求时定义回调对象,其回调方法会处理响应结果 。
(2)客户端轮询,将请求发送给服务端去执行 。
(3)客户端轮询得到服务端返回的响应结果 。
(4)客户端轮询调用发送请求的回调方法 。
(5)自定义的回调方法会处理响应结果,然后放到拉取器中 。
(6)消费者从拉取器中获取步骤(5)放入的结果 。
上面已经分析了消费者的轮询流程, 轮询操作定义了拉取消息的执行流程。 只有拉取到消息,消费者客户端才可以对消息进行处理和消费 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号