自学Python八 爬虫大坑之网页乱码
Bug有时候破坏的你的兴致,阻挠了保持到现在的渴望。可是,自己又非常明白,它是一种激励,是注定要被你踩在脚下的垫脚石!
python2.7中最头疼的可能莫过于编码问题了,尤其还是在window环境下,有时候总是出现莫名其妙的问题,有时候明明昨天还好好的,今天却突然。。。遇到这种问题真的是一肚子的火。。。fuck!
首先,在我们编写python代码的时候就要注意一些编码的规范。
1.源码文件用#-*-coding:utf-8-*- 指定编码并把文件保存为utf-8格式
2.文件开头使用from __future__ import unicode_literals 以此避免在中文前面加u,以考虑到迁移到python3。
3.python内部是用Unicode存储的,所有的输入要先decode变成unicode,输入的时候encode变成想要的编码。在window环境下常用到的有utf-8,gbk,gb2312,gb18030等。
4.一般网站基本都是utf-8或者gb2312。可以尝试进行decode,然后encode 当前输出环境的编码格式,系统默认的编码格式通过sys.getfilesystemencoding()。涉及到文件路径的时候要转换为系统默认的编码。
5.unicode字符串在写入文件时必须转换为某种字符编码。
在抓取网页时,我们可以先看看该网页的字符编码,这些内容可以在html代码或者f12看network中看到:

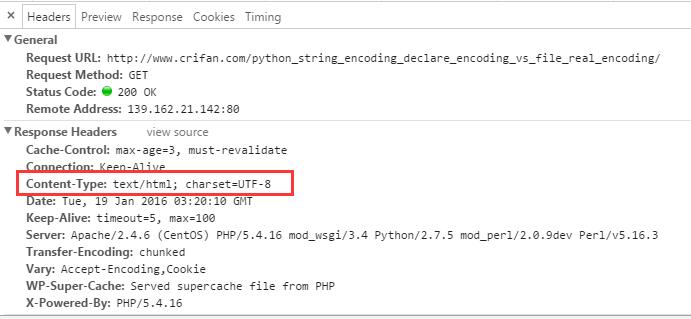
当你得到网页源码后进行print的时候,那么你就要小心了。你可能会得到UnicodeEncodeError!
你可以这样:
1 type = sys.getfilesystemencoding() 2 #utf-8为网页编码,可能为gbk等 3 html = html.decode('utf-8').encode(type)
另外还有一种万能的方式,就是用chardet包确定网页编码。刚试了试 比较慢。。。需要安装chardet包,地址为https://pypi.python.org/pypi/chardet 可以通过pip install chardet 或者 easy_install chardet安装。使用代码如下:
1 htmlCharsetGuess = chardet.detect(pageCode) 2 htmlCharsetEncoding = htmlCharsetGuess["encoding"] 3 htmlCode_decode = pageCode.decode(htmlCharsetEncoding) 4 type = sys.getfilesystemencoding() 5 htmlCode_encode = htmlCode_decode.encode(type) 6 print htmlCode_encode
还有一种可能就是,你得到的网站内容是被gzip压缩过的,这时候我们还需要去解压缩。大部分的服务器是支持gzip压缩的,我更改了一下HttpClient.py。我们默认就去已gzip的方式去访问网站,得到压缩过的内容再处理,这样抓取速度就更快了,下面来看一下HttpClient.py的Get方法:
1 import zlib 2 def Get(self, url, refer=None): 3 try: 4 req = urllib2.Request(url) 5 req.add_header('Accept-encoding', 'gzip')#默认以gzip压缩的方式得到网页内容 6 if not (refer is None): 7 req.add_header('Referer', refer) 8 response = urllib2.urlopen(req, timeout=120) 9 html = response.read() 10 gzipped = response.headers.get('Content-Encoding')#查看是否服务器是否支持gzip 11 if gzipped: 12 html = zlib.decompress(html, 16+zlib.MAX_WBITS)#解压缩,得到网页源码 13 return html 14 except urllib2.HTTPError, e: 15 return e.read() 16 except socket.timeout, e: 17 return '' 18 except socket.error, e: 19 return ''
写了这么多发现没写到点子上,自己经验比较少,然而字符编码这种事情是需要经验的。总结起来就是一句话,如果出现了UnicodeEncodeError错误了,就说明字符编码出问题了,python解释器也是一个工具,你需要让他明白,所以要decode,然后他为了让你明白所以要encode。 为了万无一失推荐使用chardet包!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号