Hive Hooks介绍
Hive作为SQL on Hadoop最稳定、应用最广泛的查询引擎被大家所熟知。但是由于基于MapReduce,查询执行速度太慢而逐步引入其他的近实时查询引擎如Presto等。值得关注的是Hive目前支持MapReduce、Tez和Spark三种执行引擎,同时Hive3也会支持联邦数据查询的功能。所以Hive还是有很大进步的空间的。
当然,诸如SparkSQL和Presto有着他们非常合适的应用场景,我们的底层也是会有多种查询引擎存在,以应对不同业务场景的数据查询服务。但是由于查询引擎过多也会导致用户使用体验不好,需要用户掌握多种查询引擎,而且要明确知道各个引擎的适用场景。而且多种SQL引擎各自提供服务会对数据仓库建设过程中的血缘管理、权限管理、资源利用都带来较大的困难。
之前对于底层平台的统一SQL服务有考虑过在上层提供一层接口封装,进行SQL校验、血缘管理、引擎推荐、查询分发等等,但是各个引擎之间的语法差异较大,想要实现兼容的SQL层有点不太现实。最近看了快手分享的《SQL on Hadoop 在快手大数据平台的实践与优化》,觉得有那么点意思。大家有兴趣的话可以看一看。
其实快手的实现核心逻辑是一样的,有一个统一的SQL入口,提供SQL校验,SQL存储、引擎推荐、查询分发进而实现血缘管理等。优秀的是它基于Hive完成了上述工作,将Hive作为统一的入口而不是重新包装一层。既利用了HiveServer2的架构,又做到了对于用户的感知最小。而实现这些功能的基础就是Hive Hooks,也就是本篇的重点。
Hook是一种在处理过程中拦截事件,消息或函数调用的机制。 Hive hooks是绑定到了Hive内部的工作机制,无需重新编译Hive。所以Hive Hook提供了使用hive扩展和集成外部功能的能力。 我们可以通过Hive Hooks在查询处理的各个步骤中运行/注入一些代码,帮助我们实现想要实现的功能。
根据钩子的类型,它可以在查询处理期间的不同点调用:
Pre-semantic-analyzer hooks:在Hive在查询字符串上运行语义分析器之前调用。
Post-semantic-analyzer hooks:在Hive在查询字符串上运行语义分析器之后调用。
Pre-driver-run hooks:在driver执行查询之前调用。
Post-driver-run hooks:在driver执行查询之后调用。
Pre-execution hooks:在执行引擎执行查询之前调用。请注意,这个目的是此时已经为Hive准备了一个优化的查询计划。
Post-execution hooks:在查询执行完成之后以及将结果返回给用户之前调用。
Failure-execution hooks:当查询执行失败时调用。
由以上的Hive Hooks我们都可以得出Hive SQL执行的生命周期了,而Hive Hooks则完整的贯穿了Hive查询的整个生命周期。
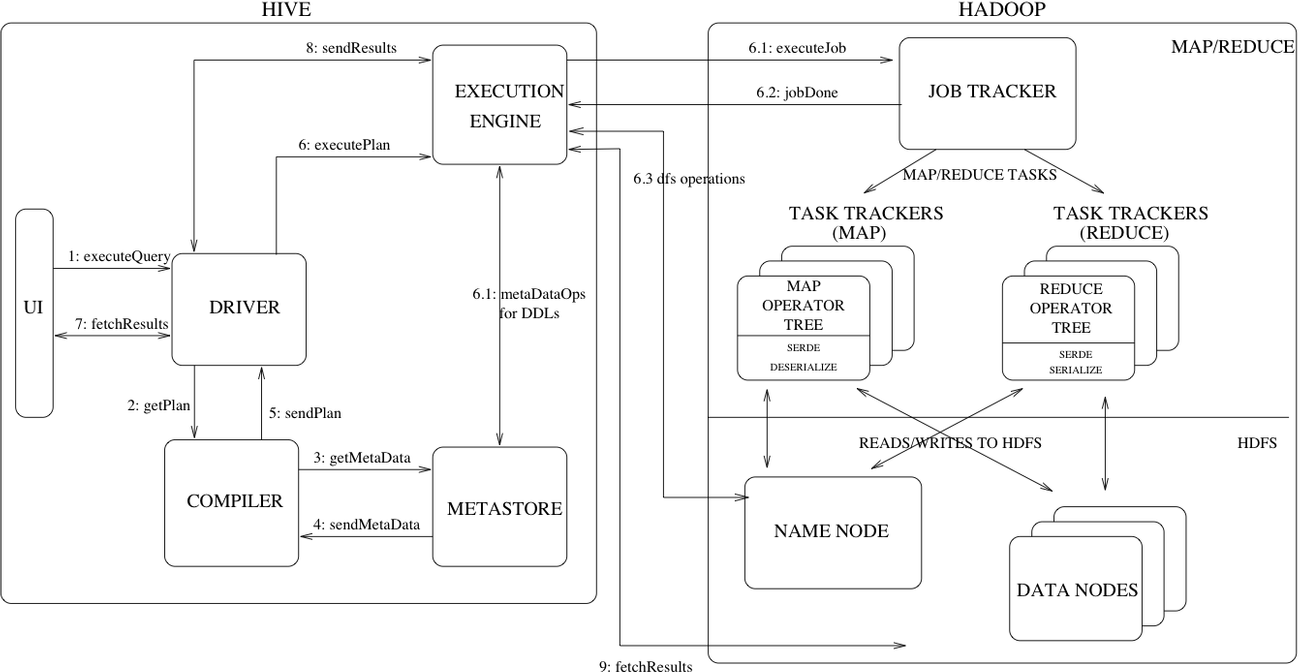
对于Hive Hooks有了初步理解之后,后面我们会通过示例介绍如何实现一个Hive Hook,并且尝试一下如何基于Hive实现统一的SQL查询服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号