九章算法笔记 1.Introducing Algorithm Interview & Coding Style
Implement strStr
算法视频QQ_1603159172
http://www.lintcode.com/problem/strstr/
Returns the position of the first occurrence of string target in string source, or -1 if target is not part of source.
遇到这道题和面试官说什么,有什么要确认的么?算法视频QQ_1603159172
对性能有要求么?
–面试常见错误1:我知道有个算法叫KMP
–不应该扯KMP的原因,而应该从最简单的算法开始:
1.算法往往没那么难
2.用那么难得算法,写出不来咋办
3.用简单的算法,即使不能写全,写到完美,至少能得一部分分
4.所以我们要写一个O(m+n)的两个for的傻叉算法就可以了
面试常见错误2:Coding Style 算法视频QQ_1603159172

–命名风格 s1, s2 神码鬼?
要用source, target
–if(){
}
一行也要用花括号, c++详见google coding style
–什么时候加空格?
1.二元运算符左右各一个space
2.++ — 不加space
3.分号右加左不加
常见错误3:没考虑corner case 算法视频QQ_1603159172

要体现自己细心靠谱,考虑各种面试官都不一定能想到的情况:
1.检测空(字符串,集合….)
2.检测下标越不越界:
凡是返回下标的,都要检查越界不,万一返回-1呢?会不会返回大于n呢?
3.要有缩进
–如果问比O(n^2)更好的算法
Rabin-Karp算法:基于hash function的原理
–主动给出Test case而不是uni test????区别
null和空的情况啦
你真的会面试么? 算法视频QQ_1603159172
–白纸上要写一遍
lintcode上面的N/A小于3是比较好的,自己动脑debug,不要提交错了再改
–吃透几道题?
看答案写出来的,过一周到两周要自己再做一遍
–面试不会就说不会么?
面试官是coworker, 程序员要有自己google然后搞定的能力
–面试官为难你?
追问是正常的,不要觉得面试官是傻逼
为什么要面试算法?算法面试难么? 算法视频QQ_1603159172
算法难,算法面试不难,因为考察的范围很窄.
–为啥这些算法没啥用还考?为啥不写project呢?
1.45分钟内完成一段代码
2.主要考察写代码的能力,所以会考不太难想的算法,但是实现不太容易的算法
3.主要不是想题,而是写程序:像贪心法这种没有太大通用性的,考得很少
刷题的经验:算法视频QQ_1603159172
–总结类似题目,一道变一类
–给一类题目弄出个模板程序
排列与组合算法视频QQ_1603159172
搜索的复杂度
–构造每个答案的时间 * 答案的个数
子集这道题为:
=O( n * 2^n)
–permutation 排列
=O(n! * n)
有时答案个数不确定的时候,假设S是所有答案的个数
= O(S * n)
问时间复杂度,基本可以和面试官交流就ok了
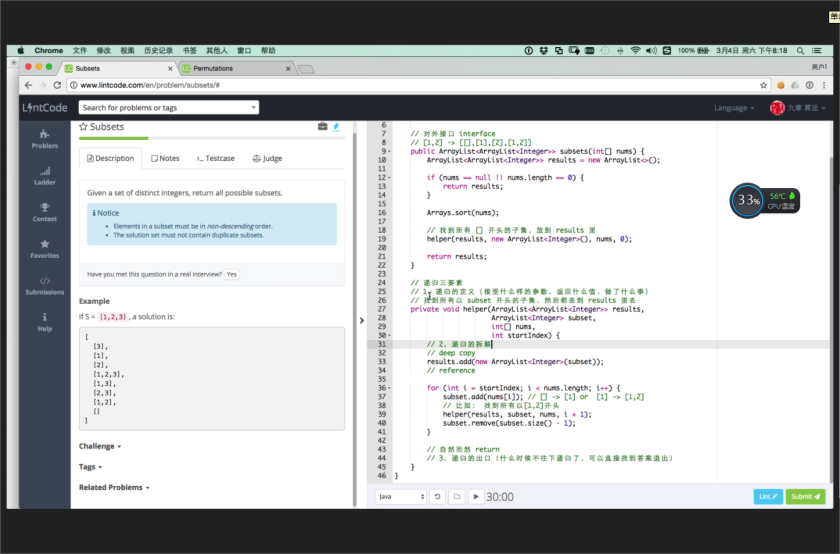
找子集问题算法视频QQ_1603159172
http://www.lintcode.com/en/problem/subsets/
Given a set of distinct integers, return all possible subsets.
Example
If S = [1,2,3], a solution is:[ [3], [1], [2], [1,2,3], [1,3], [2,3], [1,2], [] ]

–从空集出发,怎样构造?
一层一层去想的,去搜索的,这种叫做宽度优先搜索
–深搜有什么好处呢?
1.宽搜需要记录上一层的状态,而深搜只需要记录上一个状态。
2.如果面试官要求打印出来就行,又因为print是不占用空间的,所以深搜空间更优。
深搜
DFS即深度优先搜索,本质是回溯,是back tracking。
是后悔的过程,是撞了南墙后悔,再回到之前的状态。

其中{1,3}之后不能加2,是因为不能重复,因为{1,2, 3}和{1, 3, 2}一样
–避免重复不应该采用的方法为:
记录所有状态,然后回去查查,如果重了,就不加。
因为这样的话,时间复杂度从O(n!)变成O(n^n)
–应该采用的方法为选代表:
{1,2,3} {1,3,2} {2,1,3} {2,3,1} {3,1,2} {3,2,1}
选代表的原则是:看脸,看谁帅谁顺眼选谁
{1,2,3}明显比较顺眼,因为有规则的增序,所以最后的路径就是如图上的粉箭头的指向。
递归算法视频QQ_1603159172
递归的本质是由大化小
–递归需要主要的问题:
递归是不是太深?在找子集问题上,不会太深,因为解一共有(2^n)个,如果n太大,解根本解不完。所以n一定是一个很小的数,n不大,递归也就不会太深。
–开始new一个空的子集
并且所有函数先解决corner case,做异常检测。
此题即解决0和null的问题。
–这道题还需要排个序,因为题目有要求
–递归的是一个function叫func(A)自己调用自己,我们在这里构造一个helper()函数
这个helper的参数呢,需要subset和可加的nums以及传答案的results以及为了避免重复而传进去的最后一个数的index(可以不传,这里传进去比较直观)
递归三要素
1.递归的定义:
接受什么参数,返回什么值,做了什么事儿
这里是找到所有以subset开始的集合,然后丢到result里面
ps:一行不要超过80到100个字符,所以参数多要分行
2.递归的拆解,怎么拆成更小的?
{1} 拆成 {1, 2} {1, 3} {1, 4}
ps:soft copy 要注意,soft copy是reference
subset = [];
results.add(subset);
results.add(subset);
results.add(subset);
subset = 1;
最后results: [1] [1] [1]
所以results.add{new一个出来的deep copy}
–函数调用后全部删除:
四大步骤:1. add{new一个空的出来} 2.加一个数 3.调用自己的小任务 4.删这个数
3.递归出口(什么时候不忘下递归了,可以直接找到答案退出)
–怎么看一个题目是深搜
有all possible字样的
写程序不是从上往下写,先写思路。
重点是bug free和速度
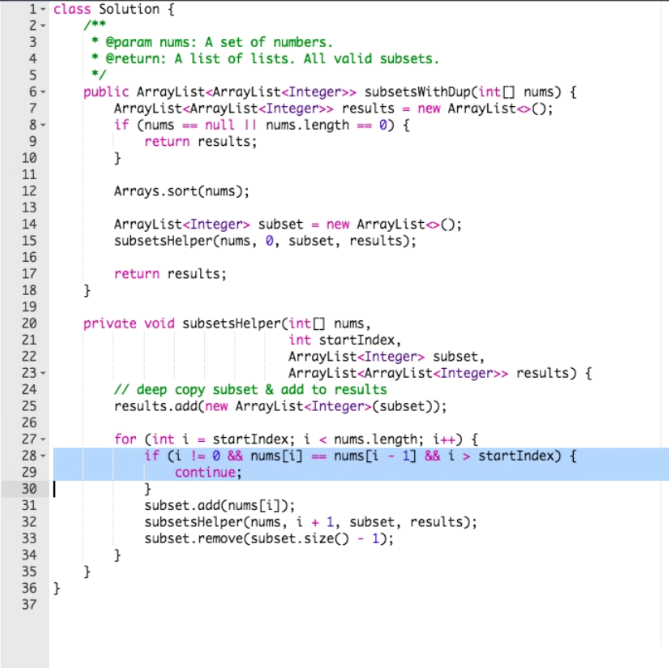
课后小视频之Subsets II算法视频QQ_1603159172
看到all 字样,很容易是深搜
如何去重呢? 错误的想法是找到所有的答案,然后再看重复与否, 去掉.
比如[1,1,1,1,1,1] 只有7个子集,但是有写2^6个答案, 浪费时间
应该开始就不加入重复的
helper应该是private的
[1,2,2′]什么时候我们应该避免重复呢?
遇到2’的时候,如果2’之前有2,而且2没有在已有的集合中,此时加2′,就会重复
课后小视频之字符串查找之 Rabin Karp 算法 算法视频QQ_1603159172
这种算法的本质是用hash function把字符串之间的比较由O(m)长的时间变为O(1)
hash function
哈希表就是个大数组, hash function是个把字符串, float, double, int都转换到数组一个位置的mapping.
ABCDE
= (a * 31^4 + b * 31^3 + c * 31^2 + d * 31 + e) % 10^6
其中31是个经验值, hash size 10^6, 越大越不容易重, 越小越容易冲突, 所以选一个不越界的大的值
如果用int的话, 保证 31 * 10^6不越界.
如果用10^8的话, 就需要long int 了
key到value唯一, 反之不成立. abc 只等于123, cde也只等与123, 但是123对应两个string

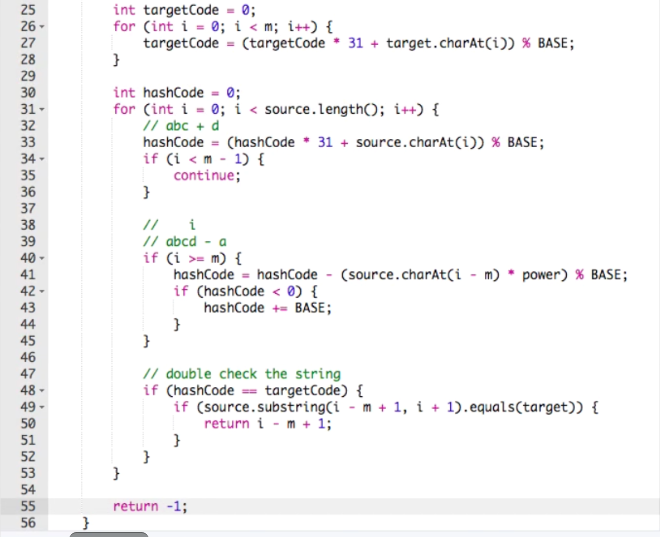
开始要处理null和length=0
22行的power要边乘边模,防止越界.
42行负数的情况最好不要直接模, 因为不同的语言负数的模结果不同,所以手动if一下
48行, hash code一样串不一定一样,hash code 不一样的串一定不一样, false positive, 所以再比较一次
