






电商分表分库, 根据orderCode,uid方案思路
一、电商两种方案分库分表
1.根据订单号分表分库
分库方案:
根据订单号后3位, 取模分库
后3位规则:
1. 小于512 //图1中,我也不知道为什么运算完, 最大值不会超过512(捂脸哭)
2. 由Long userId, Long merchantId进制转换为3位数 //因为项目有商家和用户的维度, 一个商家对应对个用户
图1: 生成orderCode方法

根据配置区分哪张表分库
图2: xml配置分库的表
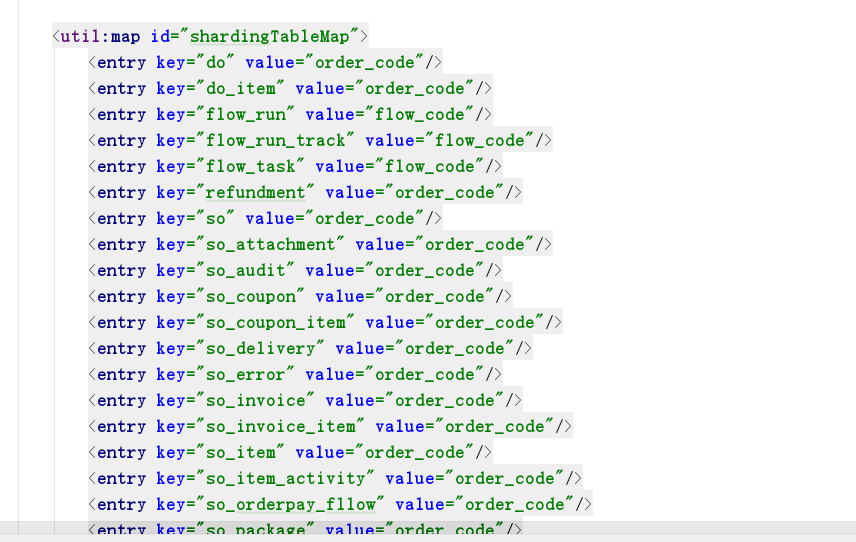
实现dataSource连接池, 判断分库的表
图3: xml配置分库的表

配置SqlSessionFactoryBean数据源
图4

分库链接配置
图5

思路:
查询 : userId, merchantId 转换为3位数, 取模
分库方案:
也是根据后3位算法, 取模 有30张表就 %30,
2.根据用户uid分表分库
方案1.
某个范围的uid订单到哪些库。0到2千万uid,对应的订单数据到a库、a表。2千万到4千万对应的订单到b库。
为什么这种方案用得比较少呢?
容易出现瓶颈吗。某个范围内的用户,下单量比较多,那么造成这个库的压力特别大。其他库却没什么压力。
方案2.
使用uid取模运算。第二种方案业界用得比较多。
要扩容的时候,为了减少迁移的数据量,一般扩容是以倍数的形式增加。比如原来是8个库,扩容的时候,就要增加到16个库,
再次扩容,就增加到32个库。这样迁移的数据量,就小很多了。这个问题不算很大问题,毕竟一次扩容,可以保证比较长的时间,
而且使用倍数增加的方式,已经减少了数据迁移量。
方案二思路:
下面是根据用户uid分表分库方案二思路
按照用户id取模的方式分库分表。按照用户id作为key来切分订单数据,具体如下:
1、 库名称定位:用户id末尾4位 取模 32。
用户id的后4位数,取32的模(取模就是除以这个数后,余多少)。余下的数,是0-31之间。
代码符号是用%表示:15%4=3。
代表着32个库名称:order_db_0、order_db_2.........................order_db_31
2、表名称定位:(用户id末尾4位 / 32) 取模 32。
id末尾4位除以一个数,取结果的整数。比如得到结果是25.6,取整就是25。
按照上面的规则:总共可以表示多少张表呢?32个库*每个库32个表=1024张表。如果想表的数量小,就把32改小一些。
思考优点和缺点
优点:
查询指定用户的所有订单,避免了跨库跨表查询。
因为,根据一个用户的id来计算节点,用户的id是规定不变的,那么计算出的值永远是固定的(x库的x表)
那么保存订单的时候,a用户的所有订单,都是在x库x表里面。需要查询a用户所有订单时,就不用进行跨库、跨表去查询了。
缺点:
1.即要扩容的时候,比较麻烦。就需要迁移数据了。要扩容的时候,为了减少迁移的数据量,一般扩容是以倍数的形式增加。
比如原来是8个库,扩容的时候,就要增加到16个库,再次扩容,就增加到32个库。这样迁移的数据量,就小很多了。
这个问题不算很大问题,毕竟一次扩容,可以保证比较长的时间,而且使用倍数增加的方式,已经减少了数据迁移量。
2.数据分散不均匀,某些表的数据量特别大,某些表的数据量很小。因为某些用户下单量多,打个比方,1000-2000这个范围内的用户,下单特别多,
3.而他们的id根据计算规则,都是分到了x库x表。造成这个表的数据量大,单表的数据量撑到极限后,咋办呢?
总结一下:每种分库分表方案也不是十全十美,都是有利有弊的。目前来说,这种使用用户id来切分订单数据的方案,还是被大部分公司给使用。实际效果还不错。程序员省事,
至于数据量暴涨,以后再说呢。毕竟公司业务发展到什么程度,不知道的,项目存活期多久,未来不确定。先扛住再说。
参考资料:
1.订单表的分库分表方案设计(大数据)
https://www.cnblogs.com/wangtao_20/p/7115962.html

