
jmeter系列-线程组详解(10)-Open Model Thread Group
Open Model Thread Group
中文翻译:开放模式的线程组
介绍:
一般而言,当我们用JMeter编写测试计划时,我们要创建一个由一组线程循环的测试计划,线程只在一段时间内运行。但是,当启动时间ramp-up结束,线程在结束自己的第一次迭代的时候,这些线程将重新开始整个过程。
这就是我们所说的“并发性(concurrency)"。我们可以说我们的应用程序可以支持一定数量的用户(如果测试顺利的话)。这是一个很好的现实生活场景的模拟,但它在几个关键领域失败了。
第一,这意味着我们需要设计一些方法,使我们的虚拟用户看起来更像真实世界的用户(考虑使用HTTP缓存管理器在每次迭代开始时清除缓存)。第二,如果我们希望我们的用户组做任何事情,而不仅仅是一直以相同的速度重复循环,这种设置非常有限。
这就是Open Model Thread Group出现的原因
添加方式:
从JMeter 5.5开始,当您右键单击Test Plan时,在Threads菜单下的Open Model Thread Group就可用了,如下所示。
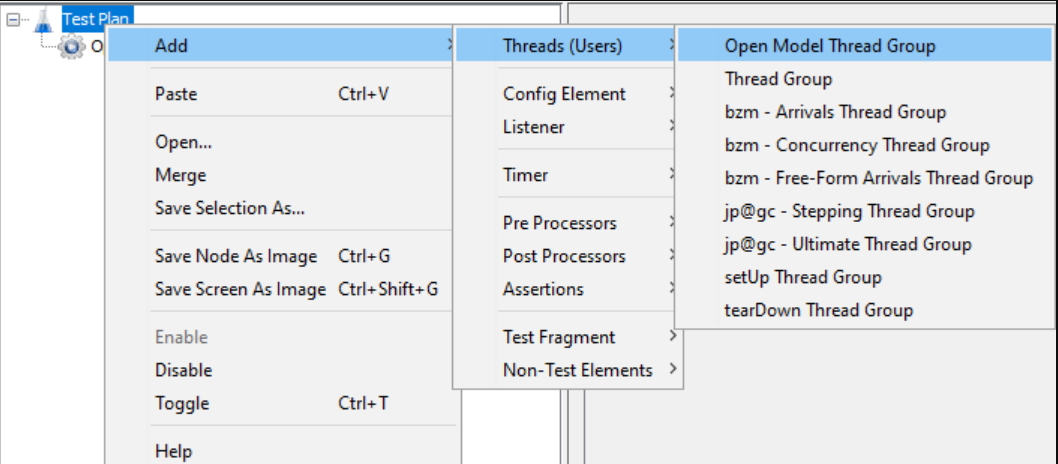
这是5.5以后的一个实验性功能,将来可能会改变。
通常,我们定义一个线程组中的线程/用户数。在利用测试计划的最佳线程数方面,没有经验法则可供遵循。有许多因素会影响系统可以运行的线程数。
Open Model Thread Group允许一个已定义的线程池 (用户) 运行而无需明确提及线程的数量。
页面说明:
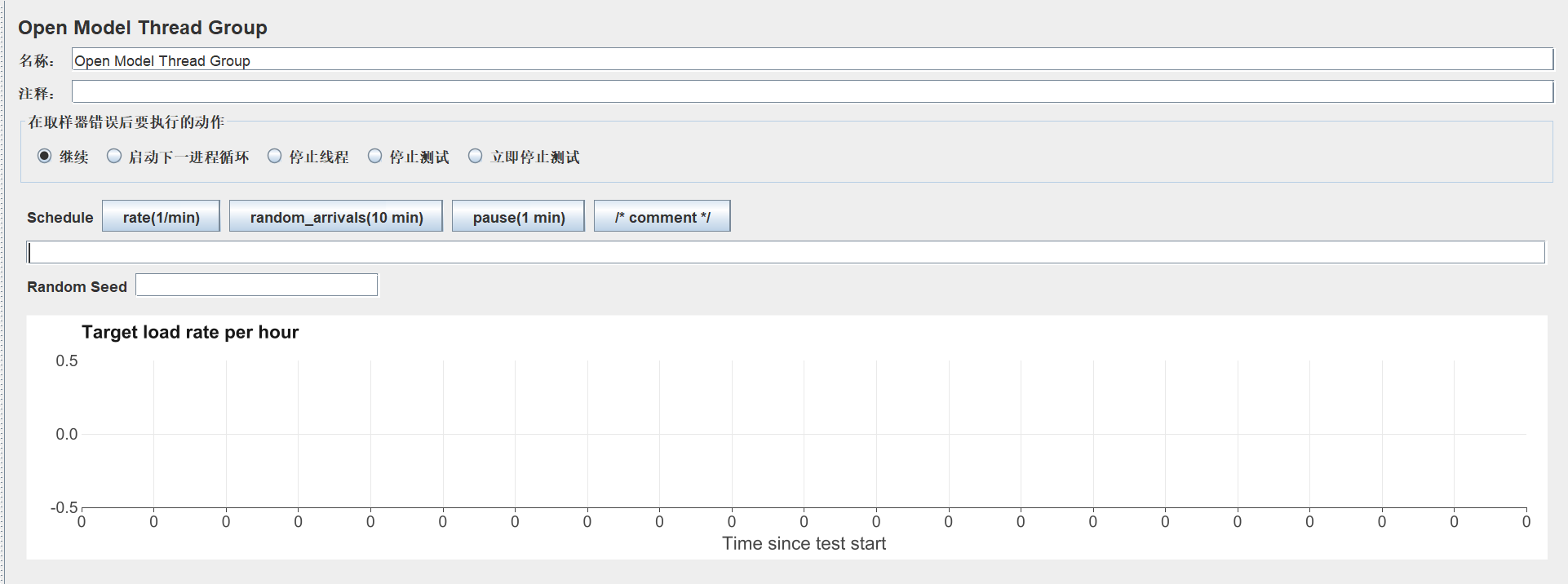
Open Model Thread Group允许您创建可定制的线程调度。您可能想知道这与Ultimate Thread Group有何不同。关键的区别在于Open Model Thread Group处理arrivals 而不是concurrency。如果它处理的是arrivals,那么它与Arrivals Thread Group有何不同? Arrivals Thread Group缺少调度线程的功能,仅仅有ramping up和holding 请求数。
Open Model Thread Group可以看做是Ultimate Thread Group和Arrivals Thread Group的孩子。它采取了Ultimate Thread Group最好的部分-设置线程场景,并于Arrivals Thread Group相结合。这使得我们能够决定虚拟用户到达的速度,并创建一个有意义的场景,即用户在应用程序上生成负载而不必确定在任何给定时间内并发的用户数量。
并发性成为用户访问您的应用程序的速度以及他们向您的服务提出请求所花费的时间的副产品。这是一种完全不同的思维方式,但它创造了新的可能性。
模拟主要流量峰值
如果你想在你的应用上模拟一个大的流量事件或负载峰值,那么让测试在几秒钟内急剧增加负载是不太现实的。其他线程组的线性特性可能无法为我们提供对该场景的特别精确的模拟。因此,从到达的角度考虑这个问题,并将其转化为Open ModelThread Group。我们从应用程序上的一些基本流量开始一一例如,每秒5个用户,持续10分钟。这将在一段特定的时间内向我们的流引入新用户,并使我们的应用程序预热到“正常”流量。
rate(5/sec)random_arrivals(10min)

现在再加上大的流量高峰。将速率提高到每秒50个用户,我们希望峰值只发。分钟,然后让到达的用户数再下降一分钟,回到每秒5个新用户的正常流
rate(5/sec) random_arrivals(10 min) rate(5/sec) random_arrivals(15 sec) rate(50/sec) random_arrivals(1 min) rate(50/sec)random_arrivals(1 min) rate(5/sec) random_arrivals(10 min)

“rate”元素可以看作是“random_arrivals”元素的子元素即目标负载率。而"random_arrivals"将确定随机到达的线程的时间,其目标是与我们预期的速率一致的负载。如果“random_arrivals”元素两侧的速率相同,那么您将在整个期间保持一致的速率。
通过解决这个问题,我们在短短几分钟内创建了一个现实的负载场景,我们不再依赖于估计任何时候有多少用户将在系统上。相反,我们允许应用程序上的并发性自然来自用户到达我们系统的速率。 我们的系统如何对此负载做出反应将产生我们可能没有预料到的有趣的并发结果。
如何在JMeter中设计Open ModelThread Group?
JMeter中的Open ModelThread Group接受一个Schedule(附表)和一个可选的随机种子。
通过使用以下表达式,我们可以定义附表
- rate
- random arrivals
- pause
- comments
rate是目标负载率如ms, sec, min, hour, and day。例子:rate(1/min)
random_arrivals有助于定义给定持续时间的随机 arrival 模式,例子: random_arrivals(10 min)
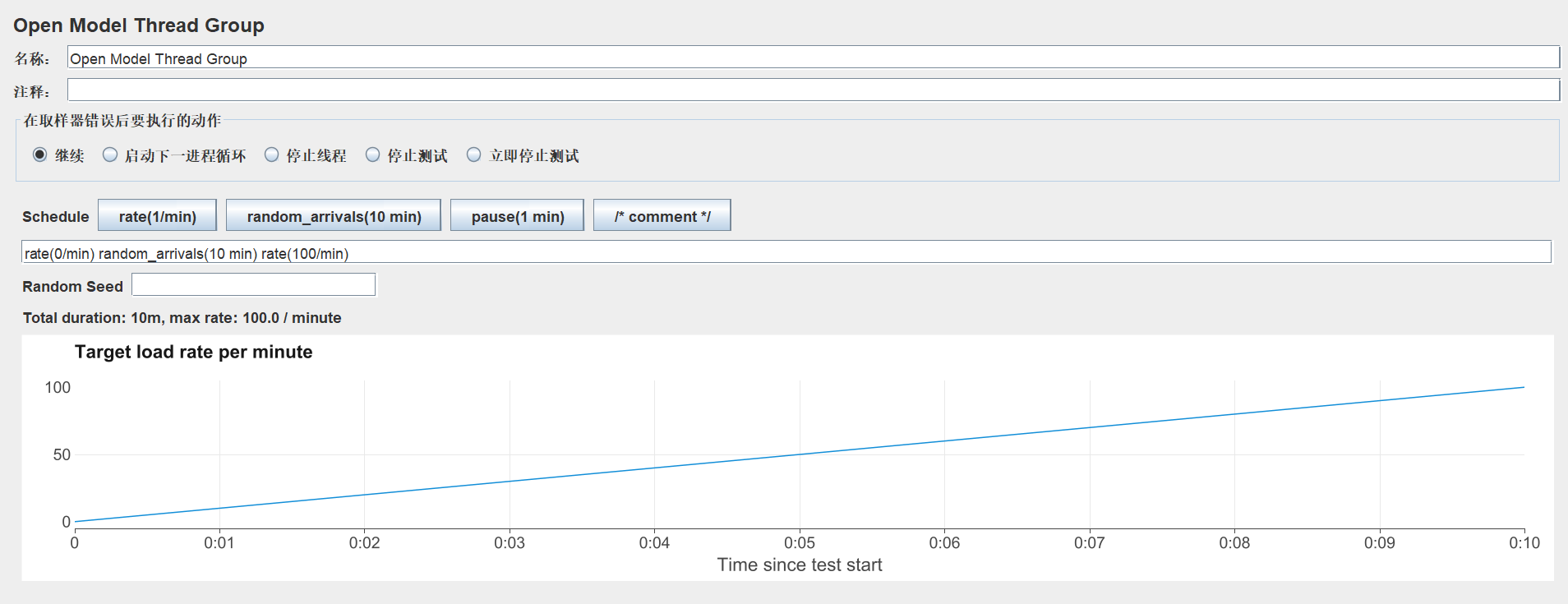
定义开始负载率,然要定义一个递增的负载模式,首先使用rate () ,然后使用random_arrivals(),最后使用rate()结束负载率。例子:rate(0/min) random_arrivals(10 min) rate(100/min)
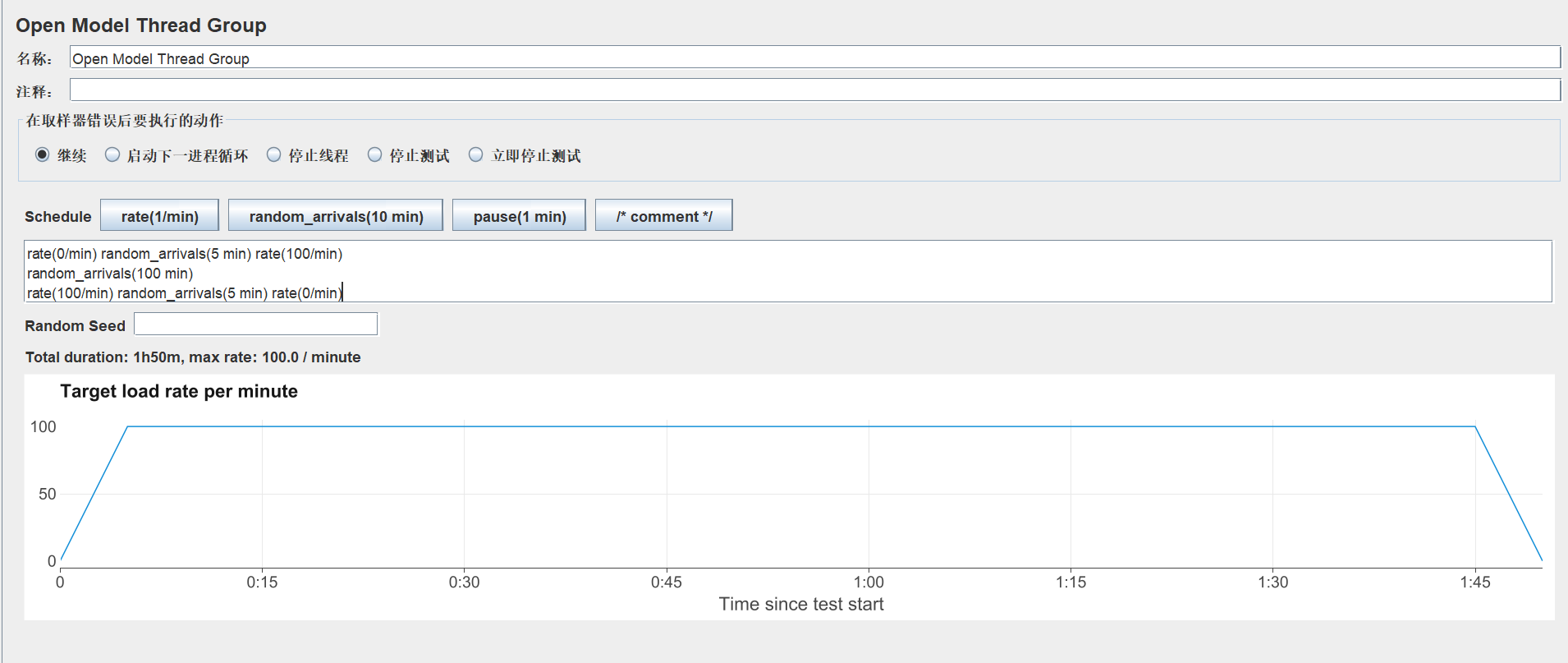
要定义稳定模式,请使用以下表达式:
rate(0/min) random_arrivals(5 min) rate(100/min) random_arrivals(100 min) rate(100/min) random_arrivals(5 min) rate(0/min)
对于步进模式(阶梯),使用:
${__groovy((1..10).collect { "rate(" + it*10 + "/sec) random_arrivals(10 sec) pause(1 sec)" }.join(" "))}
or
${__groovy((1..3).collect { "rate(" + it.multiply(10) + "/sec) random_arrivals(10 sec) pause(1 sec)" }.join(" "))}
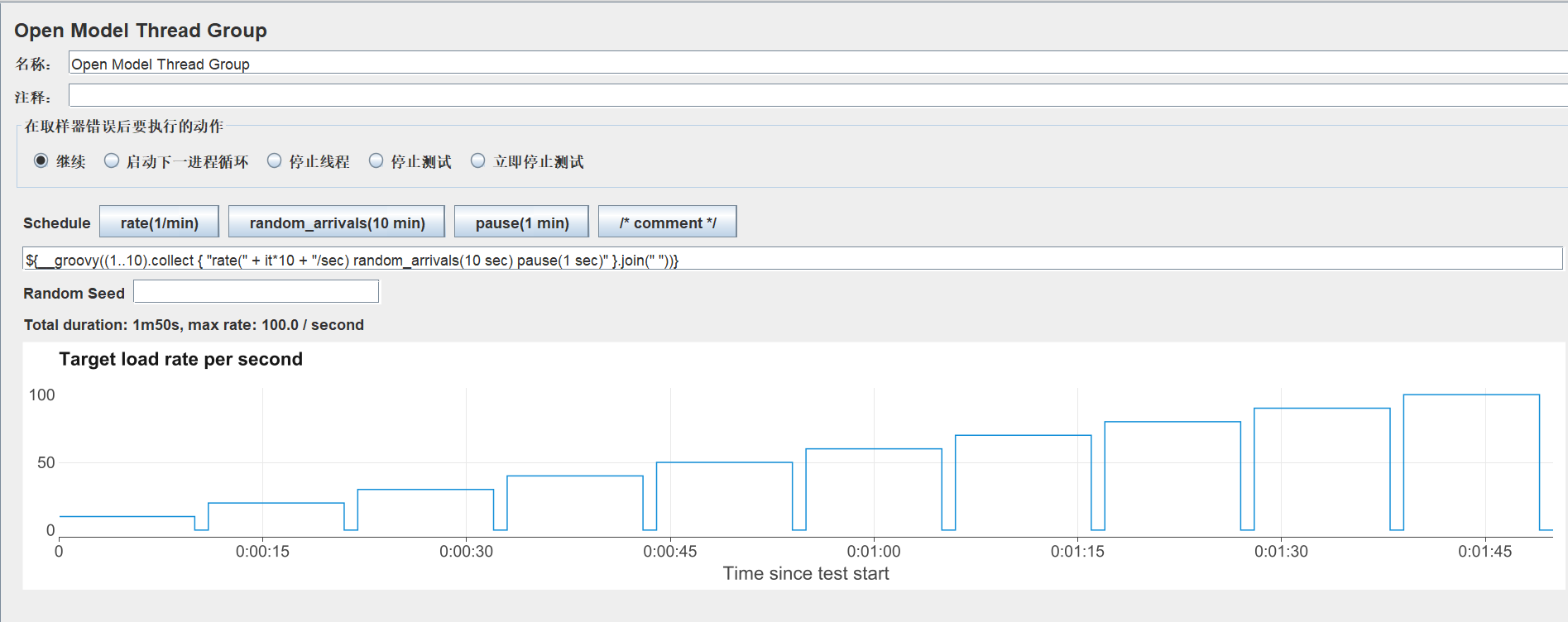
表达式中也接受JMeter函数
pause(2 min) rate(${__Random(10,100,)}/min) random_arrivals(${__Random(10,100,)} min) rate(${__Random(10,100,)}/min) pause(2 min) rate(${__Random(10,100,)}/min) random_arrivals(${__Random(10,100,)} min) rate(${__Random(10,100,)}/min) pause(2 min) rate(${__Random(10,100,)}/min) random_arrivals(${__Random(10,100,)} min) rate(${__Random(10,100,)}/min)
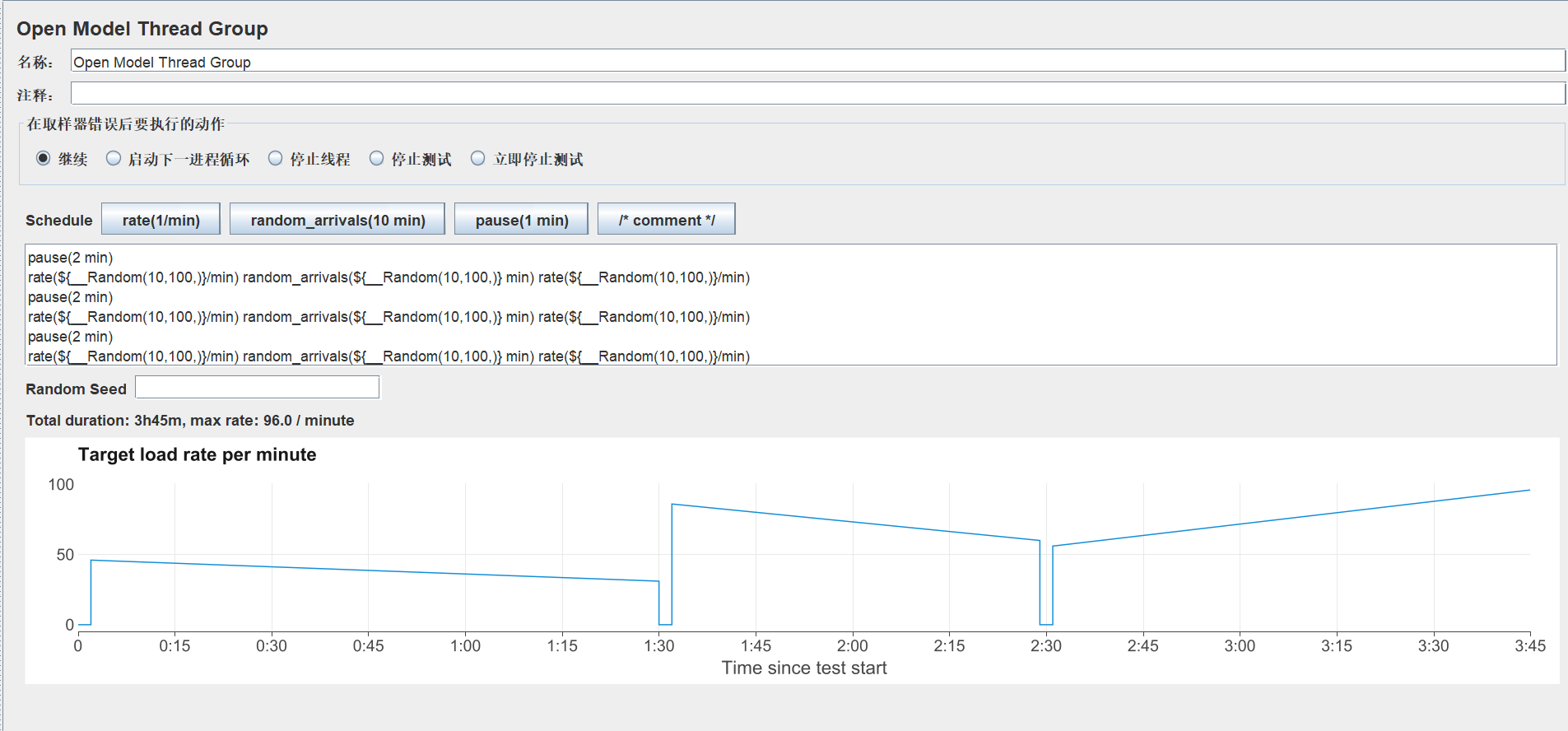
除了上述参数,表达式还允许单行和多行注释
/* multi-line comment */ // single line comment rate(1/min) random_arrivals(10 min) pause(1 min)
在Open Model Thread Group中,还没有实现这个特性:even_arrivals()
Open Model Thread Group在测试开始时执行,这意味着Open Model Thread Group中的任何函数都只执行一次;它们的第一个结果将用于执行。
工作负载模型示例
让我们使用下面的表达式设计下面的工作负载模式
rate(0/s) random_arrivals(10 s) rate(10/s)
random_arrivals(1 m) rate(10/s)
本次测试的总时长为1分10秒。前10秒内,速率达到10/s,然后,在1分钟内吞吐量将保持在10/s。
最大吞吐量为600个/分钟。
下面是测试计划中的虚拟采样器,其随机响应时间分别为${__Random(2000,2000)} 和 ${__Random(50,500)}
由于吞吐量是600,这个测试计划将尝试分别维护两个采样器的速率,即600+600=1200个请求。
由于第一个虚拟采样器的响应时间是2000 ms,测试计划将创建更多的线程来保持吞吐量。
下面是汇总报告。每个虚拟采样器的吞吐量为9.4/秒,总共达到1280个请求。

结论
Open Model Thread Group在设计自定义负载模式时将非常有用,而无需计算线程的数量。表达式中的函数有助于生成动态工作负载模型。使用这个线程组,不需要计算测试所需线程的确切数量,只要负载生成器足够强大,可以生成负载模式。它是一个新的功能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号