第三章:搜索引擎索引(上)
索引是在计算机科学中非常常用的数据结构,其根本目的是为了在具体应用中加快查找速度。
索引基础
单词——文档矩阵是表达两者之间所具有的一种包含关系的概念模型。
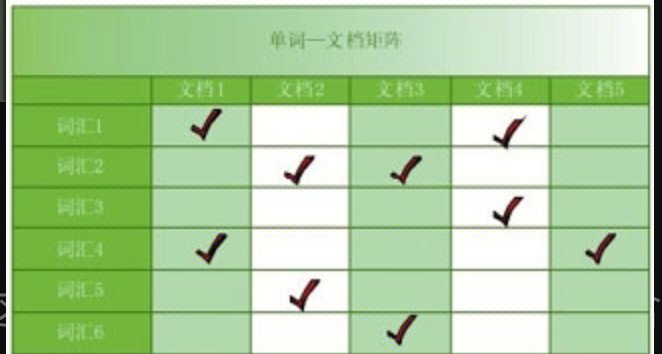
从横向来看可以得到某个词汇在哪些文档里。
从纵向来看可以得到某个文档中含有哪些词汇。
搜索引擎的索引其实就是实现单词——文档矩阵的具体数据结构。可以有不同的方式实现上述概念模型,比如倒排索引、签名文件、后缀树等方式。倒排索引是单词到文档映射关系的最佳实现方式。
倒排索引基本概念
-
文档 Document:以文本形式存在的存储对象。一封邮件,一条微博等都可以称作文档
-
文档集合 Document Collection:若干个文档构成的集合
-
文档编号 Document ID:每一个文档赋予一个唯一的内部编号
-
单词编号 Word ID :搜索引擎通常的索引单位是单词,而单词编号是每个单词的唯一标识
-
倒排索引 Inverted Index:实现单词文档矩阵的一种具体存储形式,由两个部分组成:单词词典和倒排文件
-
单词词典 Lexicon : 单词词典是文档集合中出现的所有单词构成的字符串集合,单词词典内的每条索引项记载单词本身的一些信息以及指向倒排列表的指针
-
倒排列表 PostingList:倒排项的集合
-
倒排项 Posting:记录了出现过某个单词的所有文档的文档列表以及单词在这个文档中出现的位置信息
-
倒排文件:存储倒排索引的物理文件。
倒排索引基本示意图如下:
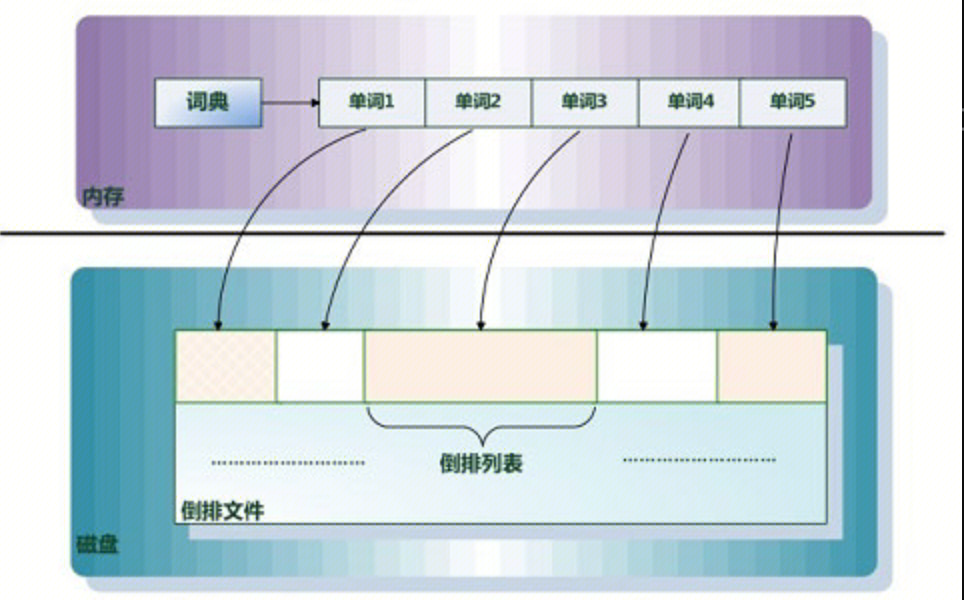
单词词典
单词词典维护
-
文档中出现的所有单词的相关信息
-
某个单词对应的倒排列表在倒排文件的位置信息
对于一个规模很大的文档集合,可能包含几十万甚至上百万不同的单词,如果要快速定位某个单词,则需要高效的数据结构对单词词典进行构建和查找,常用的数据结构包括:哈希加链表结构 和 树形词典结构
哈希加链表
每个哈希表项保存一个指针,指针指向冲突链表,在冲突链表里,相同哈希值的单词形成链表结构。
具体如下图:
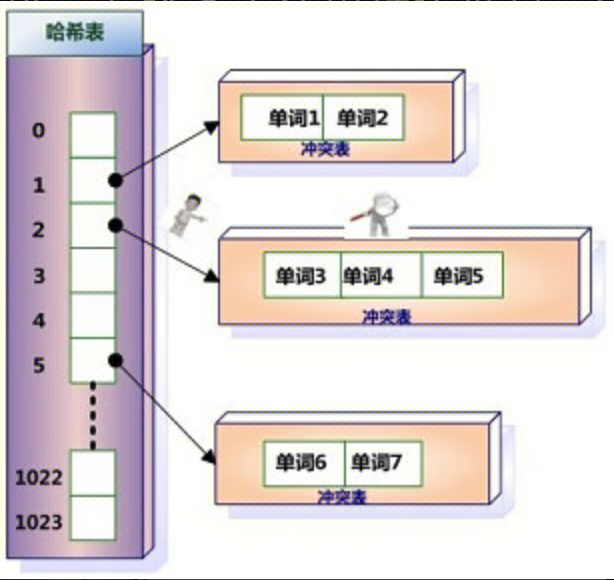
词典构建的过程如下:
- 解析文档,得到单词,用哈希函数获得其哈希值
- 根据哈希值定位到哈希表项,读取指针,得到对应的冲突链表。
- 如果冲突链表中存在这个单词,则说明单词在之前解析的文档中有;反之,则将单词加入冲突链表中。
当文档集合内的所有文档解析完毕后,相应的词典结构也就建立起来了。
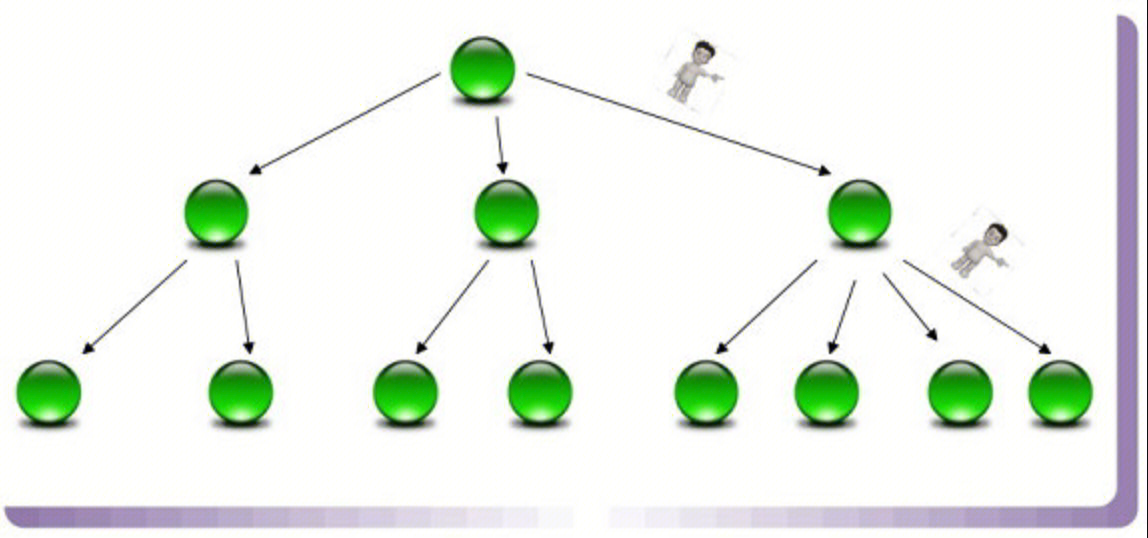
树形词典
B 树或者 B+树 作为查找结构。
树形结构需要字典项能够按照大小排序(数字或者字符序),而哈希方式则无须数据满足此项要求。
B 树的中间节点用于指出一定顺序范围的词典项目存储在哪一个子树中,起到根据词典项比较大小进行导航的作用,最底层的叶子结点存储单词的地址信息。
倒排列表
文档集合中会有很多文档包含某个单词,
而关于这个单词。每个文档的DocID,单词在这个文档中出现的次数(TF),单词在文档中哪些位置出现过等信息都会被记录到 倒排项中。某个单词的所有倒排项形成了列表结构。在文档集合中出现过的所有单词以及其对应的倒排列表组成了倒排索引。倒排索引就是用来记录有哪些文档包含了某个单词。

注意:实际搜索引擎,存储的并不是文档的实际编号,而是文档编号的差值。也就是原始的文档编号为 187,196,199 存储时会存为 187,9,3。这样做的目的是将大数据转换成小数据,有助于增加数据的压缩率。
索引建立
建立索引的方法包括:
-
两遍文档遍历法 2-Pass In-Memory Inversion
-
排序法 Sort-based Inversion
-
归并法 Merge-based Inversion
这里暂时先不扣细节,等到之后,学到 Lucene 索引建立的时候再补充。挖坑了。
动态索引
在真实环境中,搜索引擎需要处理好的文档集合往往是动态的,这意味着在建好初始的索引后,后续不断有新文档进入系统,同时原先的文档集合内有些文档可能被删除或者内容被更改。原本建立的索引不可以一直用,需要实时的更新,以反映这种实时的变化,这就是动态索引。
动态索引中包含 倒排索引,临时索引和已经删除的文档列表。
-
倒排索引就是对初始文档集合建立好的索引结构,一般单词词典存储在内存,对应的倒排列表存储在磁盘文件中。
-
临时索引是在内存中实时建立的倒排索引,其结构和倒排索引一样,区别在于词典和倒排列表都在内存中存储。当有新文档进入系统时,实时解析文档并将其追加进这个临时索引结构中。
-
已删除文档列表则用来存储已被删除的文档的相应文档ID,形成一个文档ID列表。这里需要注意的是:当一篇文档内容被更改,可以认为是旧文档先被删除,之后向系统内增加一篇新的文档,通过这种间接方式实现对内容更改的支持。
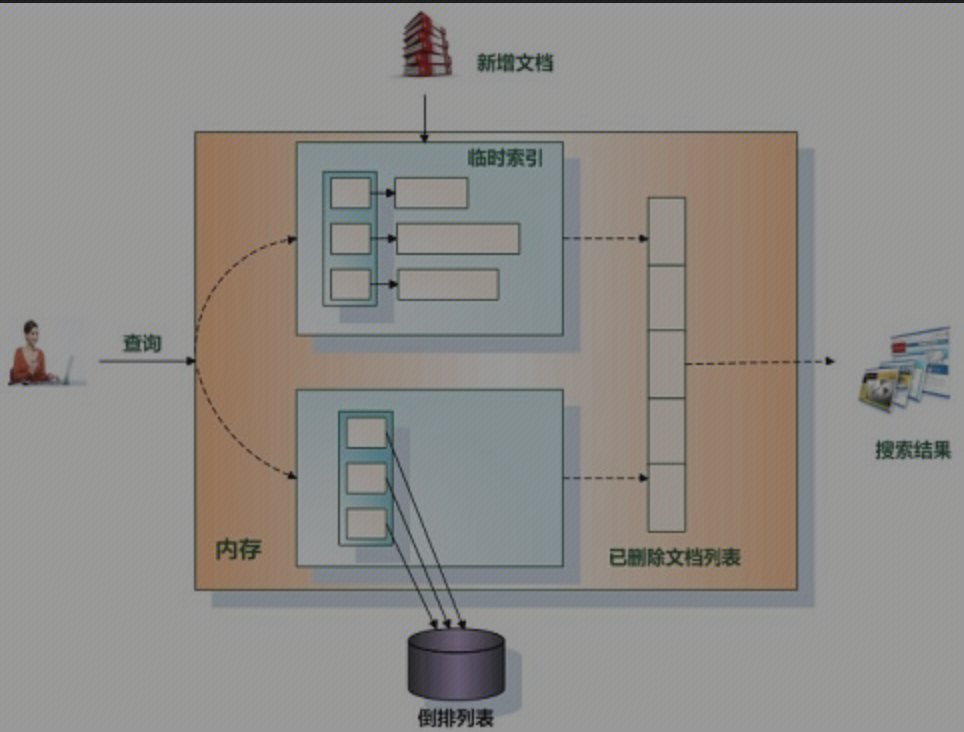
当有新文档进入时,系统立即将其加入临时索引中。
当有文档被删除时,则将其加入删除文档队列。
当文档被更改时,则将原先文档放入删除队列,解析更改后的文档内容,并将其加入临时索引中。
通过这种方式可以满足实时性的要求。
而面对用户的查询请求,搜索引擎同时从倒排索引和临时索引中读取用户查询单词的倒排列表,找到包含用户查询的文档集合,并对两个结果进行合并,之后利用删除文档列表进行过滤,将搜索结果中那些已经被删除的文档从结果中过滤,形成最终的搜索结果,并返回给用户。这样就能够实现动态环境下的准实时搜索功能。
