第一章:搜索引擎及其技术架构
搜索引擎的重要性
在没有更有效的替代解决方式出来之前,搜索是目前解决信息过载的相对有效方式。
搜索引擎技术发展史& 与技术发展的关系
1. 分类目录
纯人工方式收集并整理高质量的网站。无技术含量
进步:被收录的网站质量较高。
不足:可扩展性不强,绝大多数网站不能被收录。
2. 文本检索
文本检索采用经典的信息检索模型来计算用户查询关键词和网页文本内容的相关程度。重点关注查询关键词和网页内容的相关性。
进步:相比于分类目录,文本检索收录了大部分网页,并且可以按照网页内容和用户查询的匹配程度进行排序。
不足:并未充分使用网页之间的丰富链接关系等信息;搜索结果质量不是很好
3. 链接分析
充分利用网页之间的链接关系,深入挖掘和利用网页链接所代表的含义。
关键技术:链接分析技术。综合考虑了信息的相关性和可信性
进步: 有效改善搜索结果质量
不足:并未考虑用户的个性化要求,只要输入的查询请求相同,所有用户都会获得相同的搜索结果。网站拥有者可以针对链接分析算法提出了不少作弊方案,导致了搜索结果质量变差。
4. 用户中心
目前的搜索引擎大都可以归入这一类,以理解用户需求为核心。
不同用户即使输入同一个查询关键词,目的可能不一样。
同一个用户输入相同的查询关键词,也会因为所在的时间和场合不同,需求有所变化。
目前的搜索引擎大多都致力于解决以下问题:如何能够理解用户发出的某个很短小的查询词背后包含的真正需求。
搜索引擎的3个目标
- 更全:索引的网页数量越全越好。可通过提高网络爬虫相关技术来实现
- 更快:索引相关技术,缓存都是直接为了达到这个目的。
- 更准:最为关键
如何使得搜索结果更准确?
这里面涉及到 3个核心问题
1. 探明用户真正的需求是什么
- 查询的平均长度是 2.7个词,如何从如此短的查询请求里获知到隐藏其后的真实用户需求?
- 不同用户使用同一个查询词的目的不同,这种差异应该如何识别?
- 同一个用户发出的同一个查询词,也可能会因为所处场景不同,其目的存在差异。这种差异应该如何识别?
用户在某时某刻发出某个查询,他的真实搜索意图到底是?
2. 判断内容和用户查询关键词的相关性。
搜索引擎本质上是一个匹配的过程,即从海量的数据里面找到能够匹配用户需求的内容。
3. 判断哪些信息用户可以信赖?
搜索引擎的技术架构
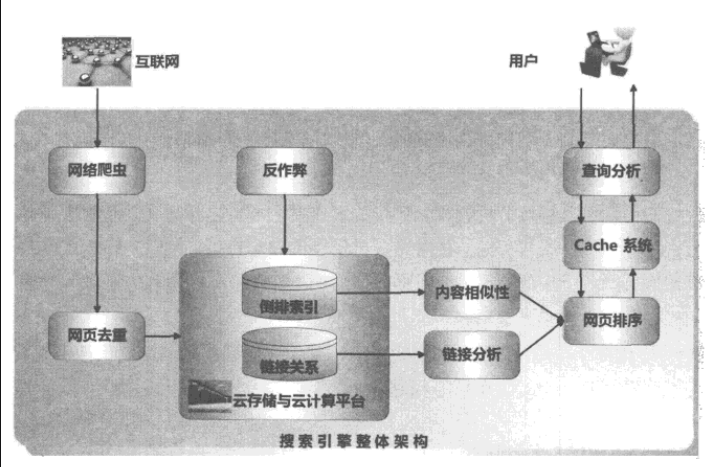
搜索引擎的后台计算系统:
- 网络爬虫技术:将整个互联网的信息获取到本地
- 网页去重:去除上一步中获得的信息的重复内容
- 搜索引擎解析网页,抽取出主体内容以及页面中包含的指向其他页面的链接。为了加快响应用户查询的速度,使用倒排索引保存网页内容和网页之间的链接关系。
- 云存储与云计算平台:作为搜索引擎及其相关应用的基础支撑。大量的网页原始信息和中间处理结果都需要存储。使用单台或者少量机器无法处理
搜索引擎的前台计算系统
响应用户查询并实时地提供准确结果
- 收到用户查询词后,对查询词进行分析,推导出用户的真正搜索意图
- 首先在缓存中查找,命中直接返回
- 保存在缓存中的信息无法满足用户需求,调用网页排序模块,根据用户的查询实时计算哪些网页是满足用户信息需求的,并排序输出作为搜索结果。
反作弊模块:
搜索引擎的反作弊模块:如何自动发现作弊网页并对其进行处罚。
