第二章 Python基础(二)
有一个简单的个人名片,包含 name、age、job、hobby信息:
------------ info of Mr.Wang ----------- Name : Mr.Wang Age : 23 job : Student Hobbie: boy ------------- end -----------------
如果通过简单的字符拼接的方法完成上面的需求,会发现第一,很难实现。第二,实现后如果需要更改名片上的个人信息很困难。所以我们需要一个新的操作姿势来完成这些问题——“格式化输出”。
只需要把需要打印的格式先准备好,里面需要用户输入的值我们先放置占位符,再把字符串里的占位符与外部的变量做个映射就ok:
# 名片格式化输出 name = input("请输入姓名:") age = int(input("请输入年龄:")) job = input("请输入工作:") hobbie = input("请输入性别:") print("---------- info of %s ----------" % name) print("Name: %s" % name) print("Age: %d" % age) print("Job: %s" % job) print("Hobbie: %s" % hobbie) print("------------- end -------------")
或者说:
name = input("Name:") age = input("Age:") job = input("Job:") hobbie = input("Hobbie:") info = ''' ------------ info of %s ----------- #这⾥的每个%s就是⼀个占位符,本⾏的代表 后⾯拓号⾥的 name Name : %s #代表 name Age : %s #代表 age job : %s #代表 job Hobbie: %s #代表 hobbie ------------- end ----------------- ''' % (name,name,age,job,hobbie) # 这⾏的 % 号就是把前⾯的字符串与拓号后⾯的变量关联起来 print(info)
向上面将字符串按照一定的格式打印或者填充就被称作为“字符串的格式化输出”。
两种方式:
-
利用百分号格式化
-
在字符串中利用 % 表示一个特殊的含义
-
%d:此处应该放置一个整数(int型)
-
%s:表示此处应该放置一个字符串
(也可以全部都使用 %s,因为任何东西都可以直接转换为字符串 -->仅限 %s )
s = "I am %s, i am %s years old" print(s) #注意出错原因跟 #有几个占位符必须用几个实际的内容代替,或者一个也不要 #print(s%“tulingxueyuan”) print(s%("Mr.Wang",18))
那么现在又有一个问题,我们如果输入以下一个程序:
我叫xxx, 今年xx岁了,我们已经学习了2%的python基础了
这里的问题是我们如果计划使用 %s 这样的占位符,那么所有的 % 都将变成占位符,我们的%2也将成为占位符。而“%的”是不存在的,这里的话我们就需要用 “%%”来表示 %。
注意:如果我们的字符串中没有出现“%s 、%d”这样的占位,那么就不用考虑这些问题。该用 % 就用 %。
print("我叫%s, 今年22岁了, 学习python2%%了" % '王尼玛') # 有%占位符 print("我叫王尼玛, 今年22岁, 已经凉凉了100%了") # 没有占位符
-
-
format函数格式化
-
直接使用format函数进行格式化
-
在使用上,以 {} 和 :代替 % 号。后面用format带参数完成。
s = "I love {}". format("Beautiful Girl") print(s) #format后的内容按照先后顺序带入序号 s = "Yes, I am {1} years old, I Love {0} and i am {1} years old".format("Beautiful Girl", 18) print(s)
2 运算符
- 由一个以上的值经过变化得到新值的过程就叫做运算
2.1 分类
-
算数运算
-
比较运算
-
逻辑运算
-
赋值运算
-
成员运算
-
身份运算
-
位运算
2.2 算数运算
“ + 、- 、 * 、/ 、 %(取余)、 **(次幂) 、 //(取整)”
2.3 比较运算
- “ == ”—— 等于:比较对象是否相等
- “!=”—— 不等于
- “<>”—— 不等于
- " > 、<" —— 大于、小于
-
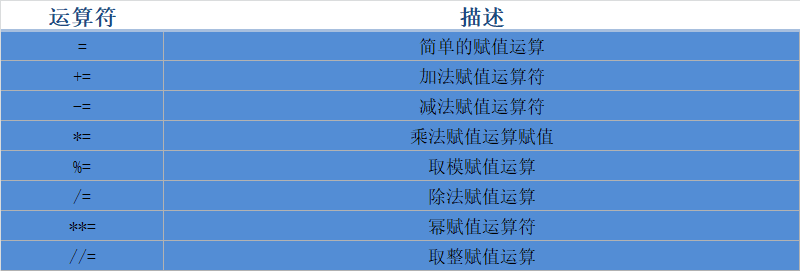
2.4 赋值运算
2.5 逻辑运算

针对逻辑运算的进一步研究:
-
在没有()的情况下not的优先级高于and,and的优先级高于or,即:
统一优先级从左往右算:()> not > and >or
例题:
# 判断下列逻辑语句的True,False。 print(3 > 4 or 4 < 3 and 1 == 1) # F print(1 < 2 and 3 < 4 or 1 > 2) # T print(3 > 4 and 2 < 5 or 8 > 6 and 4 < 3 or 6 < 8) # T print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) # F print(not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6) # F
-
x or y,x为真,值就是x,x为假,值就是y;
x and y,x为真,值是y,x为假,值就是x。
例题: 求出下列逻辑的值
print(8 or 4) # 8 print(4 or 8) # 4 print(0 or 4) # 4 print(4 and 0) # 0 print(0 or 4 or 8) # 4 print(4 or 5 and 0) # 4 print(0 or 4 and 8 and 7 or 6) # 7
3 编码的问题
python2解释器在加载 .py ⽂件中的代码时,会对内容进⾏编码(默认ascill),⽽python3对内容进⾏编码的默认为utf- 8。 计算机: 早期. 计算机是美国发明的. 普及率不⾼, ⼀般只是在美国使⽤. 所以. 最早的编码结构就是按照美国⼈的习惯来编码 的. 对应数字+字⺟+特殊字符⼀共也没多少. 所以就形成了最早的编码ASCII码. 直到今天ASCII依然深深的影响着我们. ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字⺟的⼀套电 脑编码系统,主要⽤于显示现代英语和其他⻄欧语⾔,其最多只能⽤ 8 位来表示(⼀个字节),即:2**8 = 256,所 以,ASCII码最多只能表示 256 个符号。
随着计算机的发展. 以及普及率的提⾼. 流⾏到欧洲和亚洲. 这时ASCII码就不合适了. ⽐如: 中⽂汉字有⼏万个. ⽽ASCII 最多也就256个位置. 所以ASCII不⾏了. 怎么办呢? 这时, 不同的国家就提出了不同的编码⽤来适⽤于各⾃的语⾔环境. ⽐如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使⽤计算机了.
GBK, 国标码占⽤2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是⽤英⽂写的. 你不⽀持英⽂肯定不⾏. ⽽英 ⽂已经使⽤了ASCII码. 所以GBK要兼容ASCII.
这⾥GBK国标码. 前⾯的ASCII码部分. 由于使⽤两个字节. 所以对于ASCII码⽽⾔. 前9位都是0
字⺟A:0100 0001 # ASCII
字⺟A:0000 0000 0100 0001 # 国标码
国标码的弊端: 只能中国⽤. ⽇本就垮了. 所以国标码不满⾜我们的使⽤. 这时提出了⼀个万国码Unicode. unicode⼀ 开始设计是每个字符两个字节. 设计完了. 发现我⼤中国汉字依然⽆法进⾏编码. 只能进⾏扩充. 扩充成32位也就是4个字 节. 这回够了. 但是. 问题来了. 中国字9万多. ⽽unicode可以表⽰40多亿. 根本⽤不了. 太浪费了. 于是乎, 就提出了新的 UTF编码.可变⻓度编码
UTF-8: 每个字符最少占8位. 每个字符占⽤的字节数不定.根据⽂字内容进⾏具体编码. 比如. 英⽂. 就⼀个字节就够了. 汉 字占3个字节. 这时即满⾜了中⽂. 也满⾜了节约. 也是⽬前使⽤频率最⾼的⼀种 编码
UTF-16: 每个字符最少占16位.
GBK: 每个字符占2个字节, 16位.
单位转换:
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
1024TB = 1EB
1024EB = 1ZB
1024ZB = 1YB

 浙公网安备 33010602011771号
浙公网安备 33010602011771号