认识分布式
什么是分布式
维基百科:
在计算机科学中,分布式计算(英语:Distributed computing),又译为分散式运算。这个研究领域,主要研究分布式系统(Distributed system)如何进行计算。分布式系统是一组电脑,透过网络相互连接传递消息与通信后并协调它们的行为而形成的系统。组件之间彼此进行交互以实现一个共同的目标。把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算,再上传运算结果后,将结果统一合并得出数据结论的科学。分布式系统的例子来自有所不同的面向服务的架构,大型多人在线游戏,对等网络应用。
当前常见的分布式计算项目通常使用世界各地上千万志愿者计算机的闲置计算能力,通过互联网进行数据传输(志愿计算)。如分析计算蛋白质的内部结构和相关药物的Folding@home项目,该项目结构庞大,需要惊人的计算量,由一台电脑计算是不可能完成的。虽然现在有了计算能力超强的超级计算机,但这些设备造价高昂,而一些科研机构的经费却又十分有限,借助分布式计算可以花费较小的成本来达到目标。
最简单定义的分布式系统是一组计算机一起工作,以最终用户身份显示为一台计算机,这些机器具有共享状态,并发操作并可独立故障,而不会影响整个系统的正常运行时间。
我们通过分配系统的例子逐步完成工作,以便更好地理解这一切。
传统的堆栈:
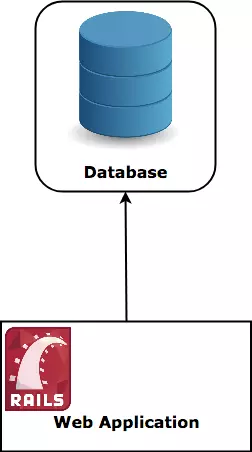
传统的数据库存储在一台机器的文件系统上,无论何时我们想要读取/插入信息,是直接和该机器通信的。
为了分发这个数据库系统,我们需要让这个数据库同时在多台机器上运行,用户必须能够与他选择的任何一台机器 通信,并且不应该能够告诉他他没有与一台机器通话 - 如果他将一条记录插入节点#1,则节点#3必须能够返回该记录。
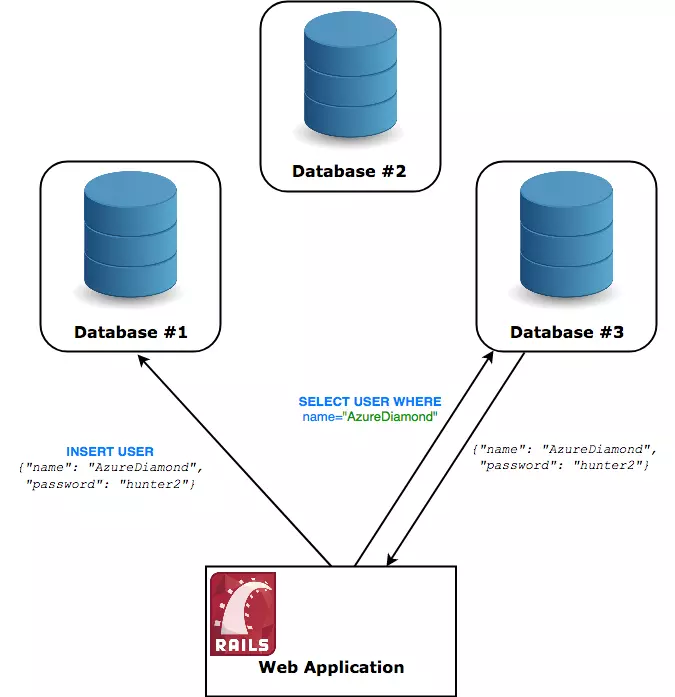
可被视为分布式的体系结构。
为什么分发系统
系统总是按需分配。事情的真相是管理分布式系统是一个复杂的主题,充满了陷阱和地雷。部署、维护和调试分布式系统令人头疼,为什么要去那里呢?
- 分布式系统使我们能够做水平扩展。回到我们前面的单个数据库服务器的例子,处理更多流量的唯一方法是升级运行数据库的硬件。这称为垂直缩放。
- 尽管可以垂直缩放,但是在某个点之后,我们会发现即使最好的硬件也不足以提供足够的流量,更不要说主机不切实际了。
- 水平缩放意味着添加更多的计算机,而不是升级单个硬件。
- 水平缩放在一定的阈值之后变得更便宜。
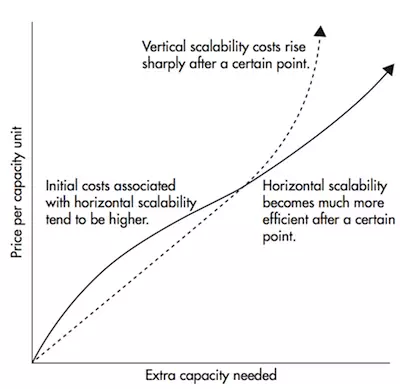
- 在一定的阈值之后,它比垂直缩放要便宜的多,但这不是偏好的主要情况。
- 垂直缩放只能将性能提升至最新的硬件功能。这些能力证明对于工作量适中到较大的技术公司是不够的。
- 关于水平缩放的最好的事情是,我们可以无限制的扩展规模,只要性能下降我们只需添加一台机器,最多可达到无限大的。
- 轻松扩展并不是从分布式系统获得的唯一好处,容错和低延迟也同样重要。
- 容错 - 跨越两个数据中心的十台机器集群本质上比单台机器更容错。即使一个数据中心着火,您的应用程序仍然可以工作。
- 低延迟 - 网络数据包出行的时间受到光速的限制。例如,纽约到悉尼之间光纤电缆的请求往返时间(即来回)的最短时间为 160ms。分布式系统允许您在两个城市都拥有一个节点,从而使流量达到最接近它的节点。
但是,要使分布式系统正常工作,需要在这些机器上运行的软件专门设计用于同时在多台计算机上运行,并处理随之而来的问题。事实证明,这并非易事。
缩放我们的数据库
想象一下,我们的Web应用程序非常受欢迎,我们的数据库每秒处理的查询次数开始增加两倍。那么我们的应用程序会立即开始降低性能,这会被用户注意到的。
在典型的Web应用程序中,通常我们读取信息比插入新信息或修改旧信息更频繁。
有一种方法可以提高读取性能,即通过所谓的主从复制策略。在这里,我们创建了两个与主要服务器同步更新的数据库服务器。问题是我们只能从这些新的实例中读取。
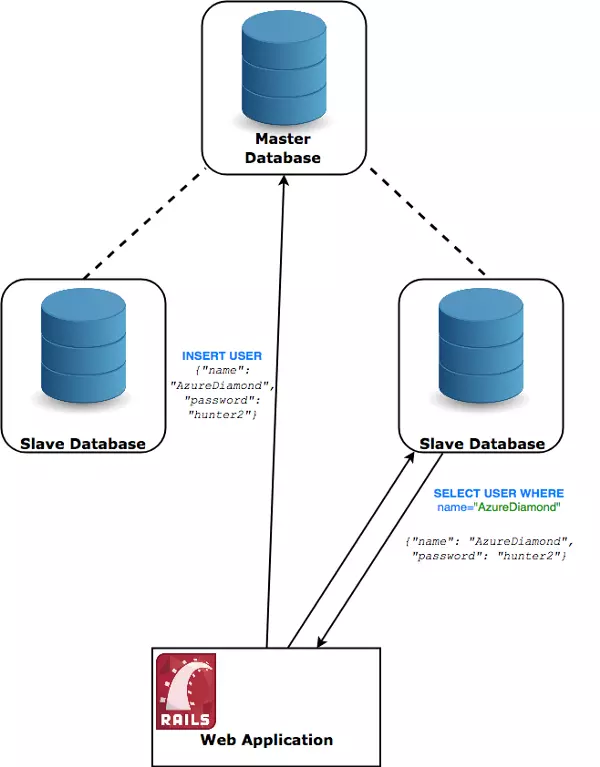
无论合适插入和修改信息,我们都可以与主数据库通信。反过来,它会异步的通知从数据库的变化,并将它们保存起来。
问题1:
我们失去了关系数据库的ACID(数据库事务正常执行的四个原则,分别指原子性、一致性、独立性及持久性)保证中的C。
现在有一种可能性,我们在数据库中插入一条新的记录,然后立即发出一个读取查询并获取任何东西,就好像它不存在一样!
将新的信息从主设备传播到从设备不会立即发生。实际上存在一个可以获取陈旧信息的时间窗口。如果情况并非如此,我们的写入性能会受到影响,因为它必须同步等待数据传播。
分布式系统带来了一些折衷。如果你想充分扩展,这个特殊的问题是我们必须忍受的。
继续扩展
使用从数据库方法,我们可以在一定程度上横向扩展读取流量。这很棒,但是我们在写入流量方面遇到了一堵墙,他仍然在一台服务器上面。
我们在这里没有太多选择。我们只需要将我们的写入流量分割为多个服务器,因为无法处理它。
一种方法是采用多主复制策略。在那里,而不是只能读取的从站,您有多个支持读取和写入的主节点。不幸的是,由于您现在有能力创建冲突(例如插入两个具有相同ID的记录),因此这会变得非常复杂。
让我们继续使用另一种称为分片(sharding)的技术(也称为分区)。
通过分片,我们可以将服务器分成多个较小的服务器,称为碎片。这些碎片都有着不同的记录,我们创建了哪种记录进入哪个碎片的规则。创建规则可以使数据以统一的方式传播,这非常重要。
对此的一种可能的方法是根据关于记录的某些信息来定义范围(例如,具有名称AD的用户)。
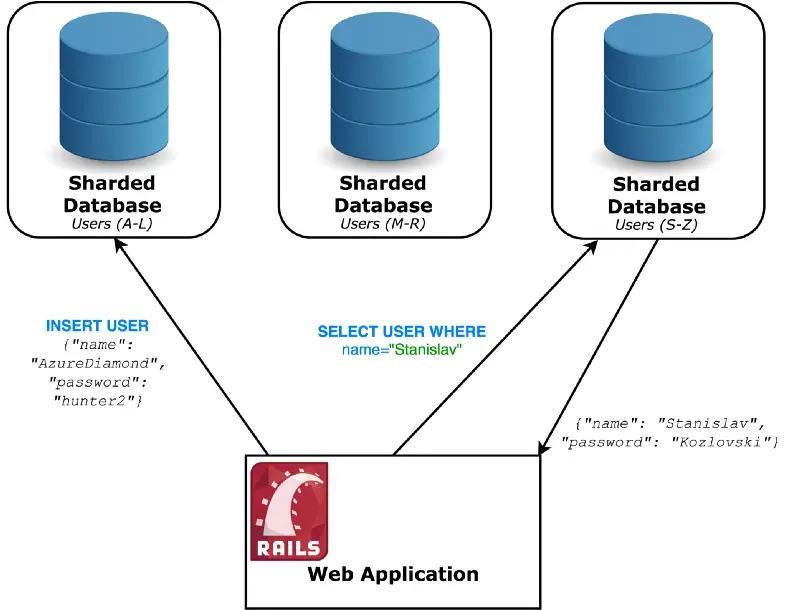
应该非常仔细地选择这个分片键,因为基于任意列的负载并不总是相等的。(例如,更多人拥有以C开头而非Z开头的名字)。一个接收更多请求的碎片被称为热点,必须避免。一旦分裂,重新分片的数据变得非常昂贵并且可能导致显着的停机时间,就像FourSquare臭名昭着的11小时停机一样。
为了保持我们的例子简单,假设我们的客户端(Rails应用程序)知道每个记录使用哪个数据库。值得注意的是,有许多分片策略,这是一个简单的例子来说明这个概念。
我们现在赢得了很多,我们可以将写入流量增加N倍,其中N是碎片的数量。这实际上给我们几乎没有限制 - 想象我们可以通过这种分区获得多么细微的粒度。
陷阱
软件工程中的一切或多或少都是一种折衷,这也不例外。Sharding不是简单的壮举,而是最好避免直到真正需要。
现在我们通过分区键之外的键进行查询的效率非常低(他们需要遍历所有的分片)。SQL 查询更加糟糕,而且复杂的查询实际上无法使用
分散与分布(Decentralized vs Distributed)
尽管这些词听起来很相似,可以得出结论意味着它们在逻辑上相同,但它们的差异会产生重大的技术和政治影响。
在技术层面上,分散型仍然是分布式的,但是整个分散式系统并不属于一个行动者。没有一个公司可以拥有分散的系统,否则它不会再分散。
这意味着我们今天将要发布的大多数系统都可以被看作是分布式集中式系统 - 这就是他们所做的。
如果你仔细想一想 - 创建一个分散系统就比较困难,因为那时你需要处理一些参与者是恶意的情况。正常分布式系统并非如此,因为您知道您拥有所有节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号