
排序与查找
排序与查找
大多数程序设计的入门经典:排序与查找。排序和查找的经典算法已经固定,作为不同场景设计的调优基础。这些算法的提出和优化过程还是很有趣的。有兴趣可以参看Donald E. Knuth的《计算机程序设计艺术(第3卷)》排序与查找,非常有趣,值得业余一看。还有一篇关于算法的讨论。
排序
内排序与外排序
根据在排序过程中待排序的记录是否全部被放置在内存中,排序分为:内排序和外排序。
内排序是在排序整个过程中,待排序的所有记录全部被放置在内存中。外排序是由于排序的记录个数太多,不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进行。我们这里主要就介绍内排序的多种方法。
对于内排序来说,排序算法的性能主要是受3个方面影响:
1.时间性能
排序是数据处理中经常执行的一种操作,往往属于系统的核心部分,因此排序算法的时间开销是衡量其好坏的最重要的标志。在内排序中,主要进行两种操作:比较和移动。比较指关键字之间的比较,这是要做排序最起码的操作。移动指记录从一个位置移动到另一个位置,事实上,移动可以通过改为记录的存储方式来予以避免(这个我们在讲解具体的算法时再谈)。总之,高效率的内排序算法应该是具有尽可能少的关键字比较次数和尽可能少的记录移动次数。
2.辅助空间
评价排序算法的另一个主要标准是执行算法所需要的辅助存储空间。辅助存储空间是除了存放待排序所占用的存储空间之外,执行算法所需要的其他存储空间。
3.算法的复杂性
注意这里指的是算法本身的复杂度,而不是指算法的时间复杂度。显然算法过于复杂也会影响排序的性能。
根据排序过程中借助的主要操作,我们把内排序分为:插入排序、交换排序、选择排序和归并排序。可以说,这些都是比较成熟的排序技术,已经被广泛地应用于许许多多的程序语言或数据库当中,甚至它们都已经封装了关于排序算法的实现代码。因此,我们学习这些排序算法的目的更多并不是为了去在现实中编程排序算法,而是通过学习来提高我们编写算法的能力,以便于去解决更多复杂和灵活的应用性问题。
基于比较的排序算法复杂度下限为log(n!)=n*log(n)。
写一个测试排序类,定义一个Function接口用jdk8新特性,简化书写。
定义一个全局待排序数组和长度。
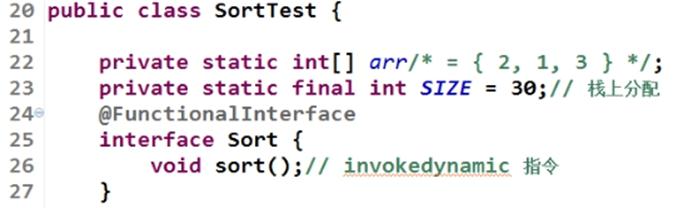
动态生成0-99数组的方法

打印数组方便测试排序

运行测试,凡是实现Sort接口的类。

冒泡

选择


数组交换

是否可以优化?
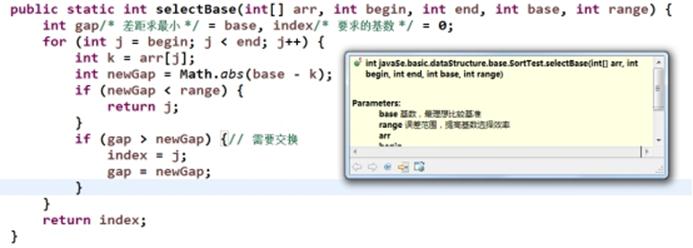
插入排序

这里用二分查找确定要插入的位置其位置。参考查找-二分查找
快速排序



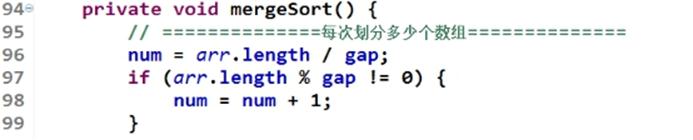
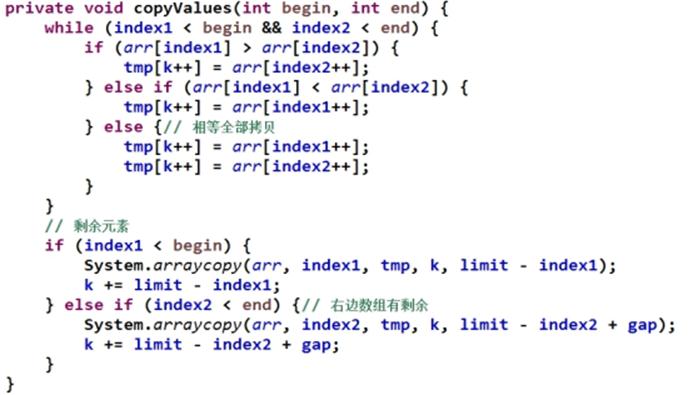
归并排序




查找
二分查找

位图
考虑这么一个场景,如果所有的数据在一个特定的范围,而且不重复。比如:编号点名,看看谁缺勤。可想的范围比如在:0-1000;再比如:服务器集群编号,每台服务器都有备份服务器,主备服务器id相同, 如果主服务器挂了,要求快速定位并切换。
可以定义一个定长bit数组,映射时候下标0对应最小编号,1表示存在编号,否则不存在。
如果在一个固定范围,数据重复可以用二维数组,一维记录数据,二位记录数据量。
Bit-Map映射表
如果数据量变大如:int的最大值以上。一个int二进制用32位表示。这样int[0]对应0-31。可以解决较大数据量问题。
Bloom-Filter
Bloom-Filter,即布隆过滤器,1970年由Bloom中提出。它可以用于检索一个元素是否在一个集合中。
Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它是一个判断元素是否存在集合的快速的概率算法。Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元素不再集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。因此,Bloom Filter不适合那些"零错误"的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter比其他常见的算法(如hash,折半查找)极大节省了空间。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。

