Adobe Acrobat DC 插件AutoBookmark的使用及其代码示例
前言
在网络上或者一些其他渠道我们经常下载获得一些我们需要的扫描文档或者pdf文件,但这些文档文件很多时候并没有目录标签,有时候给我们的阅读带来一些不便。强大的Adobe Acrobat DC 有一个目录制作插件AutoBookmark,可以根据制作的目录文档自动生成目录标签,据此,我将在下面的内容介绍如何使用AutoBookmark以及如何制作其需要的目录文档。
AutoBookmark的使用
设置目录文档导入格式
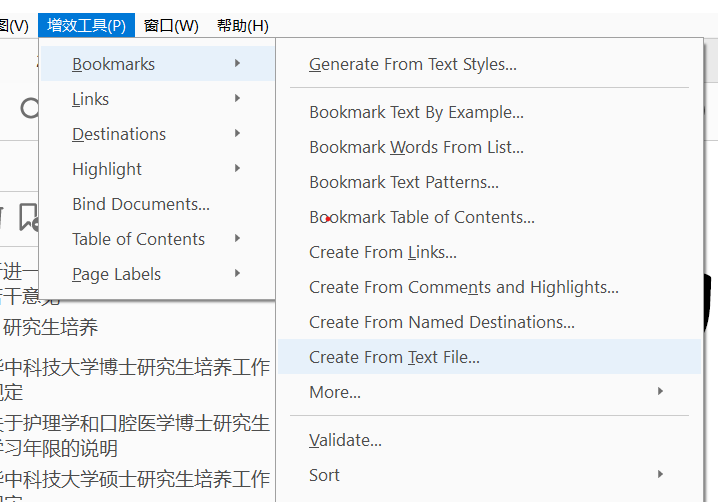
- 用Adobe Acrobat DC打开需要制作目录标签的pdf文档,在增效工具中的Bookmarks中选择Creat From Text File以打开目录文档格式制作界面。
![]()
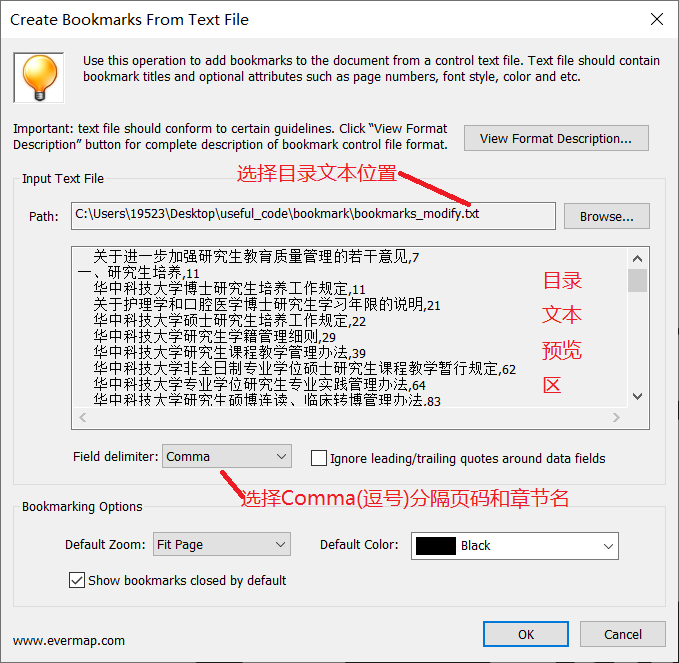
- 基本文档格式设置如下图
![]()
目录文档的制作
- 使用适当工具提取pdf文档中的目录界面的文字,并进行整理
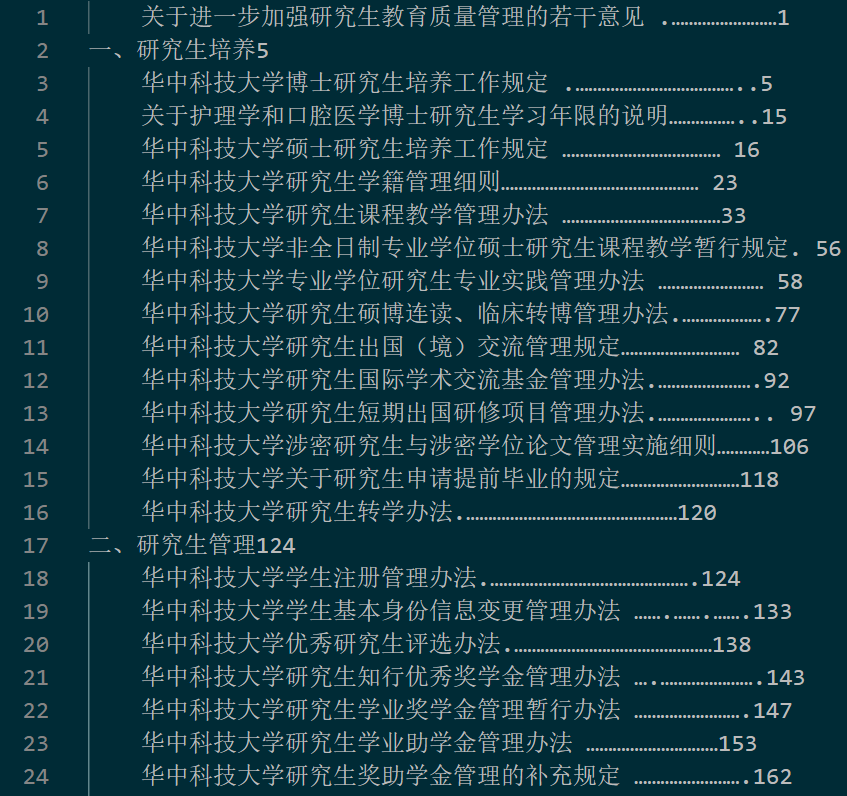
- 以tab区分不同的章节层次,每添加一个章节层次在开头添加一个tab(如下图为一个两层次的章节目录文档,这一步需自行调整)
![]()
- 使用以下python源代码去除章节名与页码之间的点号并插入逗号分割符(与Adobe Acrobat DC中Bookmarks插件的目录文档格式相一致)
# -*- coding: utf-8 -*- # adobe acrobat书签制作 import re with open('bookmarks.txt', 'r', encoding='utf-8') as f: txtword = f.readlines()#将目录以行的形式存放到txtword中 with open('bookmarks_modify.txt', 'w', encoding='gbk') as f: for i in txtword: pattern = r'[\u4e00-\u9fa5]+' #以unicode编码的形式寻找该行的中文 ch = re.findall(pattern, i)[-1] #提取目录中最后一个中文字符 num=re.findall('\d+',i)[-1] #寻找页码 pattern = ch+'.*?'+num+'.*\n' #提取最后的中文字符和页码以及两者之间的部分 num=str(int(num)+6) #将页码由字符类型转换为数据类型并调整页码大小(6为实际页码和标注码的差值,需要自己对照书籍或文章自己手动更改) a=re.sub(pattern,ch+','+num+'\n',i)#将最后的中文字符和页码以及两者之间的部分替换为',' f.writelines(a) #将修改好的行写入
- 以tab区分不同的章节层次,每添加一个章节层次在开头添加一个tab(如下图为一个两层次的章节目录文档,这一步需自行调整)
示例文件(提取码:4236)
注:
- bookmarks.py为源代码
- bookmarks.txt为调增好章节层次的txt文件
- bookmarks_modify.txt为去除多余点号和插入分隔符的txt目录文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号